介绍
Inception v2与Inception v3被作者放在了一篇paper里面,因此我们也作为一篇blog来对其讲解。
Google家的Inception系列模型提出的初衷主要为了解决CNN分类模型的两个问题,其一是如何使得网络深度增加的同时能使得模型的分类性能随着增加,而非像简单的VGG网络那样达到一定深度后就陷入了性能饱和的困境(Resnet针对的也是此一问题);其二则是如何在保证分类网络分类准确率提升或保持不降的同时使得模型的计算开销与内存开销充分地降低。在这两个问题中,他们尤其关注第二个问题,毕竟在移动互联网大行天下的今天,如何将复杂的CNN模型部署在计算与存储资源均有限的移动端,并使之有效地运行有着更大的实际价值。
在Inception v1当中,它用于参赛的Googlenet模型只使用了约5百万个参数,与它相比,Alexnet使用了约6千万个参数,VGG用的参数更是多达1亿八千万个(当然其中主要是因为后两者使用了较大的FC层)。
而在Inception v2模型中,作者们又进一步考虑了其它减少计算与可训练参数的可能,最终这一新模型在使用较少训练参数的情况下达到了更高的state-of-art分类准确率。
模型设计的通用准则
对于CNN模型设计与训练这一‘炼金术’学问,Googler们在一番摸索与思考后提出了以下几个尚未被证伪的‘炼金法则’。而Inception v2/v3模型的设计思想即是源自于它们。
慎用bottleneck
如果出于模型分类精度考虑,那么应尽量避免使用bottleneck模块(关于此可参考不才之前的那篇inception v1博客),尤其是不应当在模型的早期阶段使用。作者们认为CNN模型本质上是一个DAG(有向无环图),其上信息自底向上流动,而每一个bottleneck的使用都会损失一部分信息,因此当我们出于计算与存储节省而使用bottleneck时,一定要下手轻些(不要一下子使用1x1 conv缩减过多的feature maps的channels数目,如果一定要用reduction模块也要在模型较靠后的几层使用)。
层宽些还是有好处的
撇开计算与内存开销增加的负面因素不谈,每个Conv层的kernels数目增加对于模型处理局部信息,进而更有效地对其表达还是有好处的。毕竟多些参数就可使得每层获得多些的表达能力,所谓一寸长一寸强。它还可使得模型收敛得更快(当然是指的整体所需的迭代次数减少,而非整体训练下来所需的全部时间)。
更深的较底层(size亦小)可以使劲压
这个纯是实验多了试出来的结论。即对于网络后面的feature maps可以使用像bottleneck那样的模块对其进行channels数目缩减再进行3x3 conv这样的较大计算。在其中1x1 conv reduction op的使用不仅不会影响模型精度,反而还能使其收敛速度加快。他们给出的猜测性解释是,后期较小size的feature maps之上的相邻units(即channels)之间具有更加的关联性(即冗余信息不少),因此可以折腾的厉害些(使输出的channels变少)而不担心信息丢失(反而信息被梳理的更清晰、有效)。。(好吧,我承认这一段乍读像是在胡说,我自己也是云里雾里。。什么时候SCI文章也开始像李义山的诗一样朦胧了。。)
平衡网络的深度与宽度
Googler们将深度学习网络的设计问题视为了一个在计算/内存资源限定条件存在的情况下,通过有效组合、堆加各种层/模块,从而使得模型分类精度最高的一种最优化问题。而这自然也是最近火热的所谓AutoML的核心思想。。
他们认为(也是通过实验后总结)一个成功的CNN网络设计一定要将深度与宽度同时增加,瘦高或矮胖的CNN网络都不如一个身材匀称的网络的效果好。
Inception v2中引入的一些变动
将kernel size较大的conv计算进一步分解
inception v1中稀疏表达模块的思想在inception v2中得到了较好的继承。既然我们可以用稀疏的inception模块来有力地表达多维度信息,那么干吗不再进一步将其中大的kernel size的conv层再进一步分解展开呢。。Network in network文章中提到一个表达力强的复杂网络可以由较简单的小网络来组成,那么干脆就将网络的组合维度再增加些好了,说不定就能更有效地逼近人脑神经元的组合复杂度呢。。下图为inception v1中所使用的inception 模块。

大kernel分解为多个小kernel的累加
首先试着将一个5x5的conv分解为了两个累加在一块的3x3 conv。如此可以有效地只使用约(3x3 + 3x3)/(5x5)=72%的计算开销。下图可看出此替换的有效性。

它的实用直接可将我们原来在inception v1中所用的inception module升级为了如下一种新的inception module。
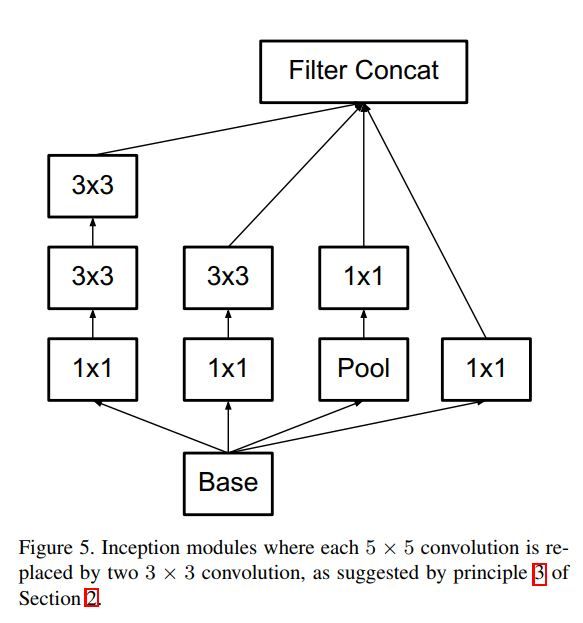
将对称的conv计算分解为非对称的conv计算
这一次是将一个3x3的conv分解为了两个分别为1x3与3x1的conv计算。这样同样可以只使用约(1x3 + 3x1) / (3x3) = 67%的计算开销。下图是此替换的有效性。作者更进一步发挥想象,认为任一个nxn conv都可通过替换为两个分别为1xn与nx1的convs层来节省计算与内存。
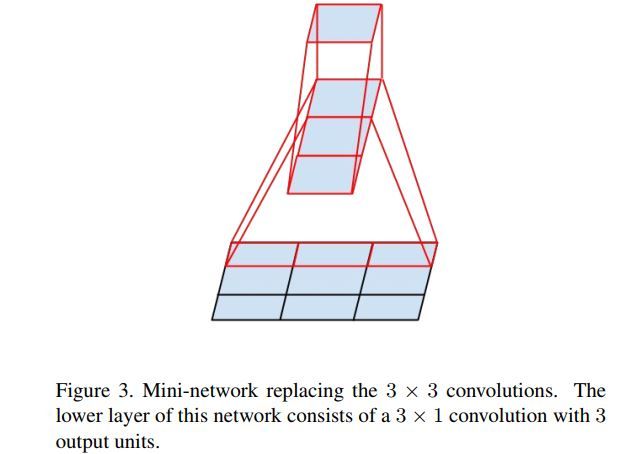
它的使用带来了另外一种更新的inception模块变种,如下图所示。

增加的分类层的作用分析
在inception v1中,作者为了减少深度模型中反向传播时梯度消失的问题,而提出了在模型的中间与较底部增加了两个extra 分类loss层的方案。
在inception v2中,作者同样使用了extra loss层。不过他们反思了之前说过的话,觉着不大对了,果断以今日之我否定了昨日之我。他们现在(当时是2015年)觉着extra loss的真正意义在于对训练参数进行regularization。为此他们试着在这些extra loss的FC层里添加了BN或者dropout层,果然发现分类结果好了些,于是就兴冲冲地发布了这一‘重大’最新发现。。
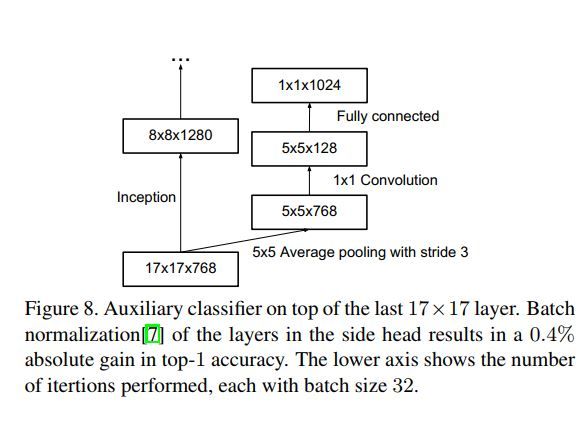
更高效的下采样方案
深度CNN网络中一般会不断使用Pool层来减少feature maps size。这必然意味着传递信息的不断丢失。一般为了减少信息的过度丢失,在加入Pool层减少feature maps size的同时都会同比例扩大它的channels数目(此一思想与做法可在VGG网络中明显看到,亦已被所有的CNN网络设计所遵循)。
真正实行可以有两个办法,其一先将channels数目扩大(一般使用1x1 conv),然后再使用pool层来减少feature map size,不过其中1x1 conv的计算显然会有非常大的计算开销;其二则是先做Pooling减少feature map size,然后再使用1x1 conv对其channels数目放大,不过显然首先使用Pooling的话会造成信息硬性丢失的不可避免,在此之后再使用1x1 conv去增加channels数目的做法已经有些亡羊补牢之嫌了。。下图反映了这两种较为传统的做法。

所以作者提出了他们的办法,确实比较新颖。即分别使用pool与conv直接减少feature map size的做法分别计算,完了后再将两者算出的feature maps组合起来,妙哉,直欲为此饮上一大浮白也!下图是此一方法的表示。

最终的Inception v2/inception v3模型
讲到这里,inception v2/v3已经呼之欲出了。请见下表。
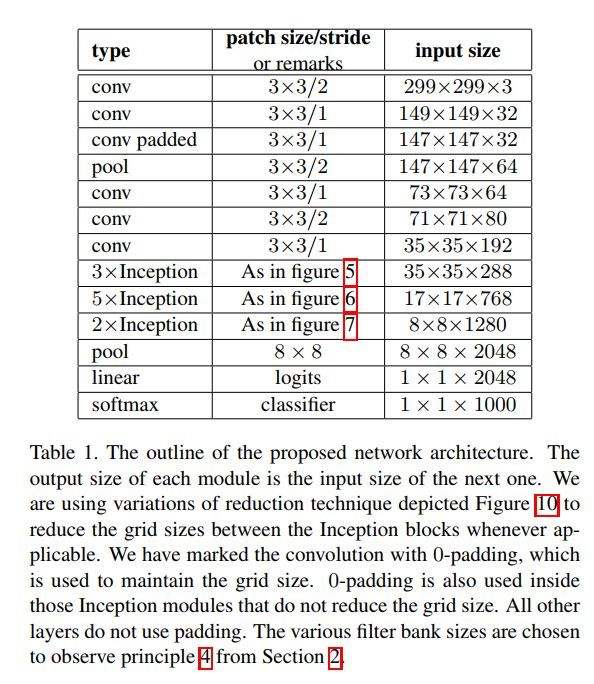
其中v2/v3模型结构上的差别只有一点即在inception v3中使用的Aug loss里面使用了BN进行regularization。
使用Label smoothing来对模型进行规则化处理
作者认为softmax loss过于注重使模型学习分类出正确的类别(label),而过于地试着偏离其它的非正确labels。。如此的话可能使得训练得到的模型在新的数据集上扩展性不好(即易陷入overfitting的困局)。为此他们认为有必要使用label的先验分布信息对其loss进行校正。如下为他们最终使用的loss。

实验结果
下图为inception v3与其它模型相比的实验结果。

代码分析
我们还是通过intel caffe里面的inception v3 prototxt file来看下它的模型设计实验吧。当然重点是看新引入的两种inception module设计。单纯去看prototxt file的话会有些不方便,毕竟配置文件实在是太长了,建议使用Netscope这个工具导入caffe的prototxt file去图形化认识它的网络。
此模型位置可于intel caffe的此处看到:models/intel_optimized_models/benchmark/googlenet_v3/train_val.prototxt。
如下为inception模型变形一。
layer {
name: "mixed_3_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_2_chconcat"
top: "mixed_3_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 384
bias_term: false
pad: 0
kernel_size: 3
stride: 2
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_3_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_3_conv_conv2d"
top: "mixed_3_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_3_conv_relu"
type: "ReLU"
bottom: "mixed_3_conv_conv2d_bn"
top: "mixed_3_conv_conv2d_relu"
}
layer {
name: "mixed_3_tower_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_2_chconcat"
top: "mixed_3_tower_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 64
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_3_tower_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_3_tower_conv_conv2d"
top: "mixed_3_tower_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_3_tower_conv_relu"
type: "ReLU"
bottom: "mixed_3_tower_conv_conv2d_bn"
top: "mixed_3_tower_conv_conv2d_relu"
}
layer {
name: "mixed_3_tower_conv_1_conv2d"
type: "Convolution"
bottom: "mixed_3_tower_conv_conv2d_relu"
top: "mixed_3_tower_conv_1_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 96
bias_term: false
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_3_tower_conv_1_batchnorm"
type: "BatchNorm"
bottom: "mixed_3_tower_conv_1_conv2d"
top: "mixed_3_tower_conv_1_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_3_tower_conv_1_relu"
type: "ReLU"
bottom: "mixed_3_tower_conv_1_conv2d_bn"
top: "mixed_3_tower_conv_1_conv2d_relu"
}
layer {
name: "mixed_3_tower_conv_2_conv2d"
type: "Convolution"
bottom: "mixed_3_tower_conv_1_conv2d_relu"
top: "mixed_3_tower_conv_2_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 96
bias_term: false
pad: 0
kernel_size: 3
stride: 2
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_3_tower_conv_2_batchnorm"
type: "BatchNorm"
bottom: "mixed_3_tower_conv_2_conv2d"
top: "mixed_3_tower_conv_2_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_3_tower_conv_2_relu"
type: "ReLU"
bottom: "mixed_3_tower_conv_2_conv2d_bn"
top: "mixed_3_tower_conv_2_conv2d_relu"
}
layer {
name: "max_pool_mixed_3_pool"
type: "Pooling"
bottom: "ch_concat_mixed_2_chconcat"
top: "max_pool_mixed_3_pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
pad: 0
}
}
如下为inception v2/v3中所使用的较为新颖的下采样模块的表示。
layer {
name: "mixed_2_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_1_chconcat"
top: "mixed_2_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 64
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_2_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_2_conv_conv2d"
top: "mixed_2_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_2_conv_relu"
type: "ReLU"
bottom: "mixed_2_conv_conv2d_bn"
top: "mixed_2_conv_conv2d_relu"
}
layer {
name: "mixed_2_tower_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_1_chconcat"
top: "mixed_2_tower_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 48
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_2_tower_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_2_tower_conv_conv2d"
top: "mixed_2_tower_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_2_tower_conv_relu"
type: "ReLU"
bottom: "mixed_2_tower_conv_conv2d_bn"
top: "mixed_2_tower_conv_conv2d_relu"
}
layer {
name: "mixed_2_tower_conv_1_conv2d"
type: "Convolution"
bottom: "mixed_2_tower_conv_conv2d_relu"
top: "mixed_2_tower_conv_1_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 64
bias_term: false
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_2_tower_conv_1_batchnorm"
type: "BatchNorm"
bottom: "mixed_2_tower_conv_1_conv2d"
top: "mixed_2_tower_conv_1_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_2_tower_conv_1_relu"
type: "ReLU"
bottom: "mixed_2_tower_conv_1_conv2d_bn"
top: "mixed_2_tower_conv_1_conv2d_relu"
}
layer {
name: "mixed_2_tower_1_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_1_chconcat"
top: "mixed_2_tower_1_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 64
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_2_tower_1_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_2_tower_1_conv_conv2d"
top: "mixed_2_tower_1_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_2_tower_1_conv_relu"
type: "ReLU"
bottom: "mixed_2_tower_1_conv_conv2d_bn"
top: "mixed_2_tower_1_conv_conv2d_relu"
}
layer {
name: "mixed_2_tower_1_conv_1_conv2d"
type: "Convolution"
bottom: "mixed_2_tower_1_conv_conv2d_relu"
top: "mixed_2_tower_1_conv_1_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 96
bias_term: false
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_2_tower_1_conv_1_batchnorm"
type: "BatchNorm"
bottom: "mixed_2_tower_1_conv_1_conv2d"
top: "mixed_2_tower_1_conv_1_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_2_tower_1_conv_1_relu"
type: "ReLU"
bottom: "mixed_2_tower_1_conv_1_conv2d_bn"
top: "mixed_2_tower_1_conv_1_conv2d_relu"
}
layer {
name: "mixed_2_tower_1_conv_2_conv2d"
type: "Convolution"
bottom: "mixed_2_tower_1_conv_1_conv2d_relu"
top: "mixed_2_tower_1_conv_2_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 96
bias_term: false
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_2_tower_1_conv_2_batchnorm"
type: "BatchNorm"
bottom: "mixed_2_tower_1_conv_2_conv2d"
top: "mixed_2_tower_1_conv_2_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_2_tower_1_conv_2_relu"
type: "ReLU"
bottom: "mixed_2_tower_1_conv_2_conv2d_bn"
top: "mixed_2_tower_1_conv_2_conv2d_relu"
}
layer {
name: "AVE_pool_mixed_2_pool"
type: "Pooling"
bottom: "ch_concat_mixed_1_chconcat"
top: "AVE_pool_mixed_2_pool"
pooling_param {
pool: AVE
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "mixed_2_tower_2_conv_conv2d"
type: "Convolution"
bottom: "AVE_pool_mixed_2_pool"
top: "mixed_2_tower_2_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 64
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_2_tower_2_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_2_tower_2_conv_conv2d"
top: "mixed_2_tower_2_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_2_tower_2_conv_relu"
type: "ReLU"
bottom: "mixed_2_tower_2_conv_conv2d_bn"
top: "mixed_2_tower_2_conv_conv2d_relu"
}
以下为inception模块变形二的描述。
layer {
name: "mixed_9_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_8_chconcat"
top: "mixed_9_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 320
bias_term: false
pad: 0
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
kernel_h: 1
kernel_w: 1
}
}
layer {
name: "mixed_9_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_conv_conv2d"
top: "mixed_9_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_conv_relu"
type: "ReLU"
bottom: "mixed_9_conv_conv2d_bn"
top: "mixed_9_conv_conv2d_relu"
}
layer {
name: "mixed_9_tower_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_8_chconcat"
top: "mixed_9_tower_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 384
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_9_tower_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_conv_conv2d"
top: "mixed_9_tower_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_conv_relu"
type: "ReLU"
bottom: "mixed_9_tower_conv_conv2d_bn"
top: "mixed_9_tower_conv_conv2d_relu"
}
layer {
name: "mixed_9_tower_mixed_conv_conv2d"
type: "Convolution"
bottom: "mixed_9_tower_conv_conv2d_relu"
top: "mixed_9_tower_mixed_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 384
bias_term: false
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
pad_h: 0
pad_w: 1
kernel_h: 1
kernel_w: 3
}
}
layer {
name: "mixed_9_tower_mixed_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_mixed_conv_conv2d"
top: "mixed_9_tower_mixed_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_mixed_conv_relu"
type: "ReLU"
bottom: "mixed_9_tower_mixed_conv_conv2d_bn"
top: "mixed_9_tower_mixed_conv_conv2d_relu"
}
layer {
name: "mixed_9_tower_mixed_conv_1_conv2d"
type: "Convolution"
bottom: "mixed_9_tower_conv_conv2d_relu"
top: "mixed_9_tower_mixed_conv_1_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 384
bias_term: false
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
pad_h: 1
pad_w: 0
kernel_h: 3
kernel_w: 1
}
}
layer {
name: "mixed_9_tower_mixed_conv_1_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_mixed_conv_1_conv2d"
top: "mixed_9_tower_mixed_conv_1_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_mixed_conv_1_relu"
type: "ReLU"
bottom: "mixed_9_tower_mixed_conv_1_conv2d_bn"
top: "mixed_9_tower_mixed_conv_1_conv2d_relu"
}
layer {
name: "mixed_9_tower_1_conv_conv2d"
type: "Convolution"
bottom: "ch_concat_mixed_8_chconcat"
top: "mixed_9_tower_1_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 448
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_9_tower_1_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_1_conv_conv2d"
top: "mixed_9_tower_1_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_1_conv_relu"
type: "ReLU"
bottom: "mixed_9_tower_1_conv_conv2d_bn"
top: "mixed_9_tower_1_conv_conv2d_relu"
}
layer {
name: "mixed_9_tower_1_conv_1_conv2d"
type: "Convolution"
bottom: "mixed_9_tower_1_conv_conv2d_relu"
top: "mixed_9_tower_1_conv_1_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 384
bias_term: false
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_9_tower_1_conv_1_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_1_conv_1_conv2d"
top: "mixed_9_tower_1_conv_1_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_1_conv_1_relu"
type: "ReLU"
bottom: "mixed_9_tower_1_conv_1_conv2d_bn"
top: "mixed_9_tower_1_conv_1_conv2d_relu"
}
layer {
name: "mixed_9_tower_1_mixed_conv_conv2d"
type: "Convolution"
bottom: "mixed_9_tower_1_conv_1_conv2d_relu"
top: "mixed_9_tower_1_mixed_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 384
bias_term: false
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
pad_h: 0
pad_w: 1
kernel_h: 1
kernel_w: 3
}
}
layer {
name: "mixed_9_tower_1_mixed_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_1_mixed_conv_conv2d"
top: "mixed_9_tower_1_mixed_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_1_mixed_conv_relu"
type: "ReLU"
bottom: "mixed_9_tower_1_mixed_conv_conv2d_bn"
top: "mixed_9_tower_1_mixed_conv_conv2d_relu"
}
layer {
name: "mixed_9_tower_1_mixed_conv_1_conv2d"
type: "Convolution"
bottom: "mixed_9_tower_1_conv_1_conv2d_relu"
top: "mixed_9_tower_1_mixed_conv_1_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 384
bias_term: false
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
pad_h: 1
pad_w: 0
kernel_h: 3
kernel_w: 1
}
}
layer {
name: "mixed_9_tower_1_mixed_conv_1_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_1_mixed_conv_1_conv2d"
top: "mixed_9_tower_1_mixed_conv_1_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_1_mixed_conv_1_relu"
type: "ReLU"
bottom: "mixed_9_tower_1_mixed_conv_1_conv2d_bn"
top: "mixed_9_tower_1_mixed_conv_1_conv2d_relu"
}
layer {
name: "AVE_pool_mixed_9_pool"
type: "Pooling"
bottom: "ch_concat_mixed_8_chconcat"
top: "AVE_pool_mixed_9_pool"
pooling_param {
pool: AVE
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "mixed_9_tower_2_conv_conv2d"
type: "Convolution"
bottom: "AVE_pool_mixed_9_pool"
top: "mixed_9_tower_2_conv_conv2d"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output: 192
bias_term: false
pad: 0
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "mixed_9_tower_2_conv_batchnorm"
type: "BatchNorm"
bottom: "mixed_9_tower_2_conv_conv2d"
top: "mixed_9_tower_2_conv_conv2d_bn"
batch_norm_param {
}
}
layer {
name: "mixed_9_tower_2_conv_relu"
type: "ReLU"
bottom: "mixed_9_tower_2_conv_conv2d_bn"
top: "mixed_9_tower_2_conv_conv2d_relu"
}
参考文献
- Rethinking the Inception Architecture for Computer Vision, Christian-Szegedy, 2015
- https://github.com/intel/caffe
- http://ethereon.github.io/netscope/#/editor