前面写了那么多,终于来到了重点......
本文中,我们先来演示常见的转码写法。

string.getBytes("charset"):将string中的字符数组按照我们指定charset格式转成字节数组。
new String(byte[] byteArray, "charset"):告诉java说,字节数组byteArray是按照charset格式解码得来的,现在需要对它进行解析并转化成内码为Utf-16格式的字符。因此,使用这个方法,要先确定好字节数组byteArray是按照什么编码格式得来的。
值得注意的是,很多人会错误地认为ni_new_gbk就是GBK格式的,还有ni_new_utf8 就是UTF-8格式的。一定要记得,jvm中字符内码只有UTF-16格式。(不理解可以看我之前的文章)
JVM中字符转码底层过程原理
1)str.getBytes();
Utf-16-->Unicode--> Utf-8
str中char是Utf-16格式的,先转化成Unicode,然后再转化成Utf-8
2)str.getBytes("charset");
Utf-16-->Unicode--> charset
str中char是Utf-16格式的,先转化成Unicode,然后再转化成charset
3)String str_new = new String(byteArray, "charset");
charset -->Unicode-->Utf-16
byteArray是某字符(或字符数组)按照charset格式解码得来的,先转化成Unicode,然后再转化成Utf-16
由上面,我们可以发现Unicode在JVM中是各编码格式之间转化的中介!!!
我们知道,Unicode和Utf-8、Utf-16互转是有一套算法的。然而,Unicode 和GBK等又如何互转?
Unicode,作为万国码,必定是所有编码方案的中心。别的编码方案必定跟Unicode有一套转化逻辑。也因此,不同编码方案之间互转,也常常以Unicode作为中转。
在这里,我们要引出CodePage的概念。前面的文章中,我们演示过在dos窗口改变系统编码(其实改变的是dos窗口的codepage)。
CodePage是各国的文字编码和Unicode之间的映射表。比如简体中文和Unicode的映射表就是CP936。以下是几个常用的codepage,相应的修改上面的地址的数字即可。
codepage=936 简体中文GBK
codepage=950 繁体中文BIG5
codepage=437 美国/加拿大英语
codepage=932 日文
codepage=949 韩文
codepage=866 俄文
上面的codepage,我们可以通过这里获取。
我们打开cp936,即GBK 和 Unicode 映射表。
我们知道 '你'的GBK编码是:0xC4E3,Unicode编码是0x4F60,
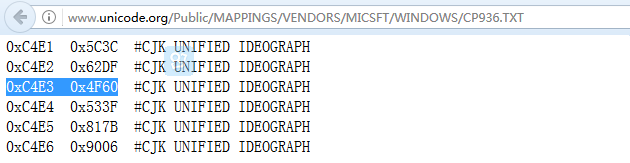
没错,jvm启动之时会在内存中建立此映射表。当我们需要对某一个GBK字符转化成UTF-8,JVM底层会先查询cp936映射表,就可以转化到Unicode编码,然后再由Unicode转化到Utf-8。