摘要
在上一个作业中,我们实现了两层的简单神经网络,在计算loss和grad时实现很简单但没有体现模块化设计,在本次作业中我们将实现模块化编程,使得能够更方便的实现多层不同结构的神经网络。
对于每个层,我们将实现“forward”和“backward”函数。“forward”函数会接收输入、权重和其他的参数并返回输出和“cache”,‘cache’中存储在“backward”中需要的数据。例如:
def layer_forward(x, w):
""" Receive inputs x and weights w """
# Do some computations ...
z = # ... some intermediate value
# Do some more computations ...
out = # the output
cache = (x, w, z, out) # Values we need to compute gradients
return out, cache
“backward”函数将接受上一层的梯度和“cache”,返回输入和权重的梯度,像这样:
def layer_backward(dout, cache):
"""
Receive derivative of loss with respect to outputs and cache,
and compute derivative with respect to inputs.
"""
# Unpack cache values
x, w, z, out = cache
# Use values in cache to compute derivatives
dx = # Derivative of loss with respect to x
dw = # Derivative of loss with respect to w
return dx, dw
除了构造不同结构的神经网络,我们还要探索不同的更新规则,使用随机失活和批量正则化来更有效率的优化较深的网络。
主要内容:
常用层的实现
多层神经网络实现
参数更新
批量归一化
(反向)随机失活
常用层的实现
这部分比较简单,只是用模块化的思想实现了层的前向和反向传播。
- 需要注意的一点:偏移量b是一个向量,不是一个矩阵,在计算out时不需要进行转置再相加,直接相加即可。这点在后面实现多层神经网络时对参数初始化的时候也是一样的。
affine layer:
def affine_forward(x, w, b):
"""
Computes the forward pass for an affine (fully-connected) layer.
The input x has shape (N, d_1, ..., d_k) and contains a minibatch of N
examples, where each example x[i] has shape (d_1, ..., d_k). We will
reshape each input into a vector of dimension D = d_1 * ... * d_k, and
then transform it to an output vector of dimension M.
Inputs:
- x: A numpy array containing input data, of shape (N, d_1, ..., d_k)
- w: A numpy array of weights, of shape (D, M)
- b: A numpy array of biases, of shape (M,)
Returns a tuple of:
- out: output, of shape (N, M)
- cache: (x, w, b)
"""
out = None
#############################################################################
# TODO: Implement the affine forward pass. Store the result in out. You #
# will need to reshape the input into rows. #
#############################################################################
pass
x_shape=x.shape
x=np.reshape(x,(x.shape[0],-1))
out=x.dot(w)+b
# out = x.dot(w) + b.T
x=np.reshape(x,x_shape)
cache = (x, w, b)
return out, cache
def affine_backward(dout, cache):
"""
Computes the backward pass for an affine layer.
Inputs:
- dout: Upstream derivative, of shape (N, M)
- cache: Tuple of:
- x: Input data, of shape (N, d_1, ... d_k)
- w: Weights, of shape (D, M)
Returns a tuple of:
- dx: Gradient with respect to x, of shape (N, d1, ..., d_k)
- dw: Gradient with respect to w, of shape (D, M)
- db: Gradient with respect to b, of shape (M,)
"""
x, w, b = cache
dx, dw, db = None, None, None
#############################################################################
# TODO: Implement the affine backward pass. #
#############################################################################
pass
x_size=x.shape
x=np.reshape(x,(x.shape[0],-1))
# db=np.sum(dout,axis=0, keepdims=True).T
db = np.sum(dout, axis=0)
dw=x.T.dot(dout)
dx=dout.dot(w.T)
dx=np.reshape(dx,x_size)
return dx, dw, db
ReLU layer:
def relu_forward(x):
out = None
#############################################################################
# TODO: Implement the ReLU forward pass. #
#############################################################################
pass
out=np.maximum(0,x)
cache = x
return out, cache
def relu_backward(dout, cache):
dx, x = None, cache
#############################################################################
# TODO: Implement the ReLU backward pass. #
#############################################################################
pass
dx = dout
dx[x <= 0] = 0
return dx
affine_relu layer:
将affine和relu结合起来。
def affine_relu_forward(x, w, b):
"""
Convenience layer that perorms an affine transform followed by a ReLU
Inputs:
- x: Input to the affine layer
- w, b: Weights for the affine layer
Returns a tuple of:
- out: Output from the ReLU
- cache: Object to give to the backward pass
"""
a, fc_cache = affine_forward(x, w, b)
out, relu_cache = relu_forward(a)
cache = (fc_cache, relu_cache)
return out, cache
def affine_relu_backward(dout, cache):
"""
Backward pass for the affine-relu convenience layer
"""
fc_cache, relu_cache = cache
da = relu_backward(dout, relu_cache)
dx, dw, db = affine_backward(da, fc_cache)
return dx, dw, db
完成上面的各个常用层后可以构造多层结构的网络,作业用这种方法让我们实现了一个两层的神经网络,不再赘述。
多层神经网络
利用上面完成的各个模块组成一个含有L层的神经网络(使用ReLU为激活函数,softmax为代价函数)。对于一个含L层的神经网络,其结构如下:
{affine - [batch norm] - relu - [dropout]} x (L - 1) - affine - softmax
其中的批量正则化和随机失活为可选项,在后面会详细解释,大括号{...}中的模块重复L-1次。
参数初始化
需要将L层的W和b初始化,W需要符合标准差为weight_scale的正态分布。如果使用了批量正则化则还需要初始化gamma和beta。
需要注意:
- 偏移量b是一个一维向量,而不是矩阵,在上面提到过。
for i, d in enumerate(hidden_dims):
if i == 0:
self.params['W%d' % (i + 1)] = weight_scale * np.random.randn(input_dim, hidden_dims[i])
else:
self.params['W%d' % (i + 1)] = weight_scale * np.random.randn(hidden_dims[i - 1], hidden_dims[i])
self.params['b%d' % (i + 1)] = np.zeros(hidden_dims[i])
if use_batchnorm:
self.params['gamma%d' % (i + 1)] = np.ones([hidden_dims[i]])
self.params['beta%d' % (i + 1)] = np.zeros([hidden_dims[i]])
self.params['W%d' % (i + 2)] = weight_scale * np.random.randn(hidden_dims[i], num_classes)
self.params['b%d' % (i + 2)] = np.zeros(num_classes)
计算loss和grad
利用前面完成的模块完成,体现了模块化编程的好处。代码没什么好说的,省略。
过拟合实验
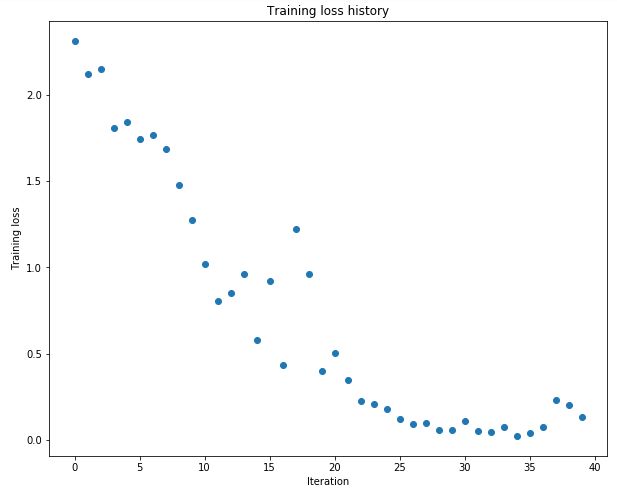
作业先后构造了三层和五层的网络,每层节点数都为100,要求我们调节weight scale和learning rate使训练20步后训练集准确率为100%。
实验发现要使五层的网络过拟合的weight scale要远大于三层网络的weight scale,说明更深层的网络会使W得值越来越接近于零,因此需要更大的标准差。

参数更新
SGD+Momentum
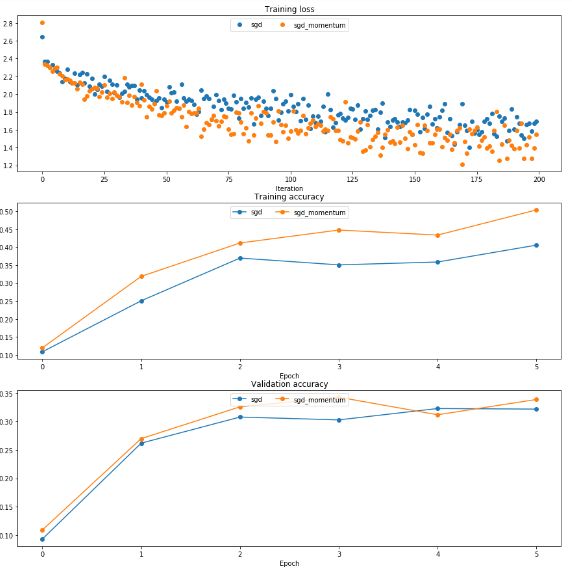
方法引入动量的概念,引入摩擦系数mu,比普通SGD更快接近最低点。

从下图可以看出改进后的更新方法的训练损失更低,准确率更高。
RMSProp
这张图来自知乎网友:https://zhuanlan.zhihu.com/p/21798784?refer=intelligentunit
Adam
因为矩阵初始化为零,所以需要进行偏差补偿。
m=config['m']
v=config['v']
t=config['t']
eps=config['epsilon']
t = t + 1
m = config['beta1'] * m + (1 - config['beta1']) * dx
v = config['beta2'] * v + (1 - config['beta2']) * (dx ** 2)
m_bias = m / (1 - config['beta1'] ** t) #偏差补偿
v_bias = v / (1 - config['beta2'] ** t)
x += - config['learning_rate'] * m_bias / (np.sqrt(v_bias) + eps)
next_x=x
t=t+1
config['t']=t
config['m']=m
config['v']=v
从下图可以看出四种方法之间的比较。Adam的损失值基本最低,而准确率最高。


批量归一化
如上面所提到的,使用不同的参数更新规则可以使更深的神经网络训练得更容易,另一个方法就是使用批量归一化。通常来说,机器学习的方法对于不相关的具有零均值和单位标准差的数据会工作的更好。因此,在每一层中都插入批量归一化对数据进行处理。在训练得过程中,我们会随机选择一批数据用于估计总体数据的均值和方差并用它对数据的特征进行归一化处理,
我对下面这一句话不理解
同时也会保存均值和方差的运行均值(running mean 和 running variation),在测试的时候这将会用来归一化特征。
批量归一化:正向通道
公式:

代码如下, 我对于其中保存running mean 和 running var,和在测试模式下使用这两个参数归一化不理解原因,为什么不直接使用mean和var进行归一化?
if mode == 'train':
mean=np.mean(x,axis=0,keepdims=True)
var=np.var(x,axis=0,keepdims=True)
x_norm=(x-mean)/np.sqrt(var+eps)
out=gamma*x_norm+beta
running_mean = momentum * running_mean + (1 - momentum) * mean
running_var = momentum * running_var + (1 - momentum) * var
cache=(x_norm,x,gamma,beta,mean,var,eps)
elif mode == 'test':
pass
x = (x - running_mean) / np.sqrt(running_var+eps)
out = gamma * x + beta
批量归一化:反向传播
反向传播还是使用链式法则一步一步进行。
需要特别注意:计算dx和dmean时要将所有用到x和mean的部分的梯度相加,在我的上一篇笔记也有提到。从前面正向传播的公式也可以看到。

代码如下:
def batchnorm_backward(dout, cache):
x_norm, x, gamma, beta, mean, var, eps=cache
dgamma=np.sum(dout*x_norm,axis=0)
dbeta=np.sum(dout,axis=0)
dx_norm=dout*gamma
#print 'dx_norm.shape',dx_norm.shape
dvar=np.sum((x-mean)*dx_norm,axis=0,keepdims=True)*(-0.5)/(np.sqrt(var+eps))**3
#print 'dvar.shape',dvar.shape
dmean=-np.sum(dx_norm,axis=0,keepdims=True)/np.sqrt(var+eps)+dvar*(-2/x.shape[0])*np.sum((x-mean),axis=0,keepdims=True)
# print 'dmean.shape',dmean.shape
dx=dx_norm/np.sqrt(var+eps)+dmean/x.shape[0]+dvar*2/x.shape[0]*(x-mean)
return dx, dgamma, dbeta
批量归一化用于深网络
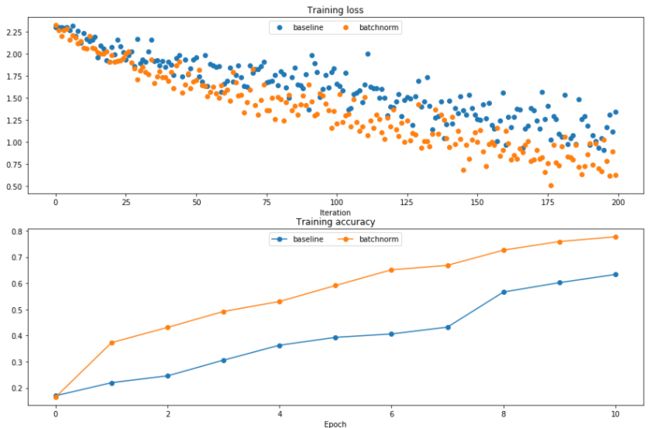
作业测试了一个五层每层节点都为100个的网络。从结果中可以看出批量归一化使loss更低,准确率更高。

批量归一化与权重初始化实验
作业用一个8层每层节点数为50的网络讨论批量归一化与weight scale之间的关系。

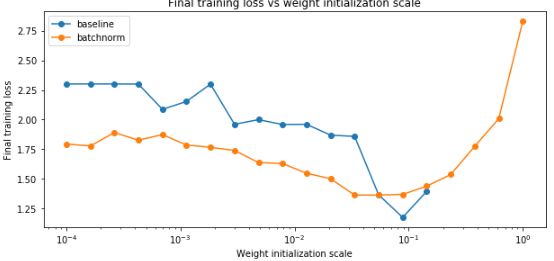
从图中可以看出,对于较小的weight scale,使用批量归一化得到的准确率更高,loss更小,对于较大的weight scale则相差不大。使用批量归一化可以使更深的神经网络的梯度减小问题得到改善。
(反向)随机失活
由于正向随机失活要改predict函数,因此反向失活更普遍。需要注意反向失活的正向传播需要除一个系数
mask=(np.random.rand(*x.shape)>p)/(1-p) #除一个系数
out=x*mask
反向传播:
``
dx=dout*mask
测试结果:
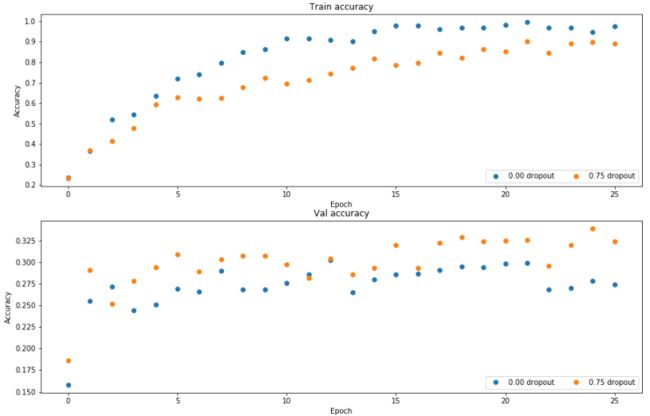
在训练集上的准确率不使用dropout的情况下更高,而在验证集上使用dropout的情况下准确率更高,说明使用dropout可以防止过拟合。
训练一个准确率最高的网络
使用上面所有优化功能,尽可能训练出准确率更高的网络。这部分以后完成。
``