前言
百度贴吧有十余年历史,笔者对此也有五年左右的持续接触。目睹了旧版贴吧被更易于插入广告的新版贴吧所取代,粗暴的帖间广告转变成真假莫辨的软文攻势,随之而来的两层会员制度,无孔不入的营销推广,甚至打破道德底线的变现行径……出于对贴吧现状的好奇,刚刚接触了Python爬虫的笔者随机抽取了15名大型贴吧大吧主各自的一部分粉丝进行粗略的二分,以期估计他们的粉丝中至少有多大比例的用户为僵尸粉丝。
平台及工具
Windows 10
Mozillia Firefox Web Browser 52.0.2 (32-bit)
Python 3.6 (32-bit)
bs4(BeautifulSoup分析网页内容供搜索)
urllib(URL相关核心模块)
openpyxl(将数据保存为Excel表格)
time(等待)
selenium(网页元素互动,用于登录一个获取他人个人页面的用户)
numpy pandas(用户信息矩阵建立,该版本中暂无用)
数据收集
** input:**用于获取粉丝的根节点ID列表
** output:**每个根节点至少全部,至多300名粉丝的信息(ID/吧龄/发帖数/关注/粉丝),是否为僵尸ID的判断结果,僵尸ID的比例。
暂定的僵尸粉丝判定条件为:
1.粉丝10人以下,关注100人以上的。or
2.粉丝10人以上,关注在粉丝的10倍以上的。or
3.个人主页无法正常访问返回404页面的。
注:满足条件3的用户大部分是贴吧自动封禁的僵尸、违禁内容发射装置,因此也划入此类。另外,存在一些僵尸ID形成了互相关注的僵尸网络,此时也无法算计在内,需要在以后的更新中加深爬取度数并更深入的分析,此为以后的计划。为此,代码亦收集了用户吧龄、发帖数等信息,不影响本次运作的结果,仅作保存。
页面分析
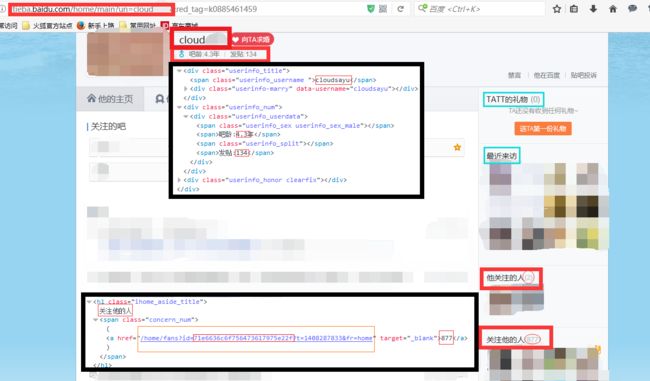
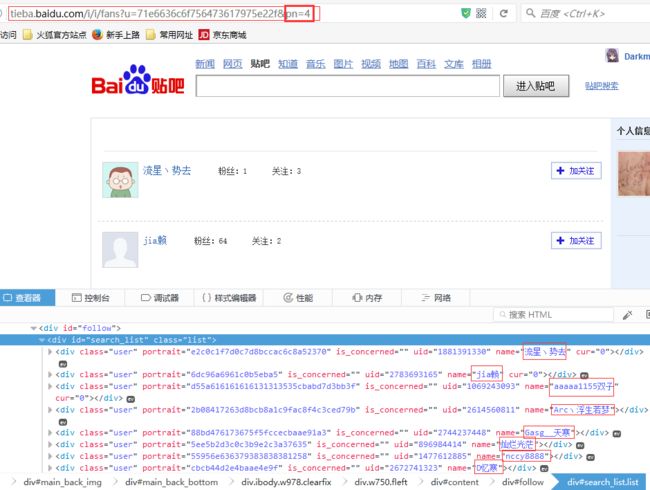
如果要进行大于1度的搜索,只需要在用户队列中继续讲1度用户作为“根节点”,将他们的粉丝加入用户队列即可(暂未用到)。
自动登录指定账号作为搜集者——>
根(0度)用户个人信息搜集——>根(0度)用户粉丝ID搜集——>
粉丝(1度)用户个人信息搜集——>粉丝(1度)用户粉丝ID搜集(——>
2度用户个人信息搜集——>2度用户粉丝ID搜集——>>N度用户)
代码实现
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import urllib.request
from urllib.request import urlopen
import urllib.parse
import numpy as np
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import openpyxl
class browser:
def __init__(self):
self.br = webdriver.Firefox()
self.login()
def login(self):
self.br.get("http://tieba.baidu.com")
log = self.br.find_element_by_xpath('//a[@class="btn_login"]')
log.click()
time.sleep(5.0)
username = self.br.find_element_by_id('TANGRAM__PSP_8__userName')
password = self.br.find_element_by_id("TANGRAM__PSP_8__password")
username.clear()
password.clear()
username.send_keys("搜寻者账号")
password.send_keys("搜寻者密码")
self.br.find_element_by_id("TANGRAM__PSP_8__submit").click()
def get(self, url):
self.br.get(url)
return self.br.page_source
class Person:
def __init__(self, username, degree):
# fans,concerns,age,mes,uid
self.username = username
self.fans = '0'
self.concerns = '0'
self.age = '0'
self.mes = '0'
self.degree = degree
self.uid = "未查到(无关注边)"
self.fan = []
self.concern = []
def select(self):
try:
url = "http://tieba.baidu.com/home/main/?un={}".format(
urllib.parse.quote(self.username))
except:
return
try:
soup = BeautifulSoup(
urlopen(url).read().decode('utf-8'), "html.parser")
except:
return
self.age, _, self.mes = soup.find(
'div', {'class': 'userinfo_userdata'}).findAll('span')[1:4]
self.age = self.age.string.split(':')[1][:-1]
self.mes = self.mes.string.split(':')[1]
if self.mes[-1:] == '万':
self.mes = str(int(float(self.mes[:-1]) * 10000 + 500))
partall = soup.findAll('h1', {'class': 'ihome_aside_title'})
allsum = soup.findAll('span', {'class': 'concern_num'})
ind = 0
for count, name in enumerate(partall):
name = str(name)
name = name.split('>')[1][:5]
if name == "他关注的人" or name == "她关注的人":
self.concerns = allsum[ind].find('a').string
ind += 1
if name == "关注他的人" or name == "关注她的人":
self.fans = allsum[ind].find('a').string
try:
self.uid = soup.find('span', {'class': 'concern_num'}).find(
'a').get('href').split('id=')[1].split('?')[0]
except:
pass
self.fr = pd.DataFrame(
[[self.username, self.fans, self.concerns, self.age, self.mes, self.degree, '', '', '', '']], columns=ids)
done.add(self.username)
def getfans(self):
if self.uid[0] == '未':
return
for page in range(1, 16):
url = "http://tieba.baidu.com/i/i/fans?u={}&pn={}".format(
self.uid, str(page))
soup = BeautifulSoup(br.get(url), "lxml")
userlist = soup.findAll('div', {'class': 'user'})
if len(userlist) == 0:
break
for user in userlist:
name = user.find('span', {'class': 'name'}).find('a').string
self.fan.append(name)
if name not in f:
f[name] = len(persons)
print("{}度用户<{}>加入成功!".format(str(self.degree + 1), name))
persons.append(Person(name, self.degree + 1))
def getconcerns(self):
if self.uid[0] == '未':
return
for page in range(1, 16):
url = "http://tieba.baidu.com/i/i/concern?u={}&pn={}".format(
self.uid, str(page))
soup = BeautifulSoup(br.get(url), "lxml")
userlist = soup.findAll('div', {'class': 'user'})
if len(userlist) == 0:
break
for user in userlist:
name = user.find('span', {'class': 'name'}).find('a').string
self.concern.append(name)
if name not in f:
f[name] = len(persons)
print("{}度用户<{}>加入成功!".format(str(self.degree + 1), name))
persons.append(Person(name, self.degree + 1))
def describe(self):
print("No:", allUserCounter)
print("Junk:", junkUserCounter)
if allUserCounter > 0:
print("junkPercent:", 100 * junkUserCounter / allUserCounter, "%")
print("用户名:", self.username)
print("粉丝数:", self.fans)
print("关注数:", self.concerns)
print("吧 龄 :", self.age)
print("发帖数:", self.mes)
def selectall(self):
self.select()
self.getfans()
self.getconcerns()
wb = openpyxl.load_workbook('res.xlsx')
sheet = wb.active
ids = ["Username", "Fans", "Concerns", "Age", "Messages", "Degree", "isJunkId", "totalId", "junkId", "junkPercent"]
for count, tag in enumerate(ids):
sheet.cell(row=1, column=count + 1).value = tag
persons = []
allUserCounter = 0
junkUserCounter = 0
f = {}
done = set()
br = browser()
time.sleep(0.3)
initFile = open('0degree.txt', 'r') #读取根用户ID
text = [i for i in initFile.read().split('\n') if i != '']
initFile.close()
for user in text:
p = Person(user, 0)
p.selectall()
sheet.cell(row=sheet.max_row + 1, column=1).value = p.username
sheet.cell(row=sheet.max_row, column=2).value = int(p.fans)
sheet.cell(row=sheet.max_row, column=3).value = int(p.concerns)
sheet.cell(row=sheet.max_row, column=4).value = float(p.age)
sheet.cell(row=sheet.max_row, column=5).value = int(p.mes)
sheet.cell(row=sheet.max_row, column=6).value = p.degree
p.describe()
for d2user in persons:
if d2user.username not in done:
allUserCounter += 1
p = Person(d2user.username, 1)
p.select()
print("Accecss!!!--->" + d2user.username)
sheet.cell(row=sheet.max_row + 1, column=1).value = p.username
sheet.cell(row=sheet.max_row, column=2).value = int(p.fans)
sheet.cell(row=sheet.max_row, column=3).value = int(p.concerns)
sheet.cell(row=sheet.max_row, column=4).value = float(p.age)
sheet.cell(row=sheet.max_row, column=5).value = int(p.mes)
sheet.cell(row=sheet.max_row, column=6).value = p.degree
if int(p.concerns) >= 100 and int(p.fans) <= 10 or (int(p.fans) >= 10 and int(p.concerns) / int(p.fans) >= 10) or int(p.concerns) + int(p.fans) == 0:
junkUserCounter += 1
sheet.cell(row=sheet.max_row, column=7).value = 1
p.describe()
if allUserCounter % 100 == 0:
print(allUserCounter, " SAVED")
wb.save('res.xlsx')
sheet.cell('H2').value = allUserCounter
sheet.cell('I2').value = junkUserCounter
sheet.cell('J2').value = junkUserCounter / allUserCounter
wb.save('res.xlsx')
f列表存用于去重,数据每隔100个子节点储存一次防止被管理员或者系统弄得颗粒无收。
初步效果
0度用户输入15人,2800个1度节点
843个僵尸粉丝/2800个粉丝 ≈ 30%僵尸粉比例