PYTHON爬虫入门&视频网站BILIBILI用户爬取爬虫详解
前言
Python使用版本:2.7
得到数据挖掘的课题后,我接触到了Python,也发现了在同样的命题下,使用的工具不同,方法不同,即使是得到了同样的结果,耗费的人力时间成本也不尽相同。
这引起了我对典型爬虫方式的便捷程度(主要是程序员角度)的一点思考。
典型?
就目前学习到的知识来看,不使用Scrapy等爬虫框架的情况下,Python爬虫可以说是由以下几个功能组合起来的:
模拟浏览器发送请求(GET/POST)
获取方式分类
GET方法
范例采用requests扩展库的get函数
返回页面内容:
# -*- coding:utf-8 -*-
import requests
url = 'http://space.bilibili.com/218345/#!/'
response = requests.get(url).content
print response
有时GET方法也有除网址以外的传入参数:Query String Parameters
# -*- coding:utf-8 -*-
import requests
import datetime, time
def datetimeTrans(d):
currentMachTime = lambda: int(round(time.time() * 1000))
return currentMachTime()
url = 'http://search.bilibiili.com/all'
payload = {
'keyword': 'THE GIRL WITH THE'
}
result = requests.get(url, params = payload).content #inject query string parameters
print result
POST方法
范例使用requests.post()
POST方法常用于请求模拟登陆,需传入参数“Form Data”
# -*- coding:utf-8 -*-
import requests
import time, datetime
def datetimeTrans(d):
currentMachTime = lambda: int(round(time.time() * 1000))
return currentMachTime()
url = 'http://space.bilibili.com/ajax/member/GetInfo?mid=218345'
headers = {
#pass
}
payload = {
'mid': 218345
'_': datetimeTrans(datetime.datetime.now())
}
print url
response = requests.post(url, headers = headers, data = payload).content #inject form data
print response
GET&POST对比
GET相较于POST的优势
(引用知乎上罗志宇的回答)
- 请求中的URL可以被手动输入
- 请求中的URL可以被存在书签里,或者历史里,或者快速拨号里面,或者分享给别人。
- 请求中的URL是可以被搜索引擎收录的。
- 带云压缩的浏览器,比如Opera mini/Turbo 2, 只有GET才能在服务器端被预取的。
- 请求中的URL可以被缓存。
POST相较于GET方法的特性
-POST不像GET的URL会显示在浏览器历史和WEB服务器日志中,相较更为安全
-在准则中,不可重复的操作(例如创建条目或修改一条记录),多是由POST请求完成的,因为POST不能被缓存,所以浏览器不会多次递交。
(关于这条我们举个小例子。假如你做了一个BLOG,并设计了一个URL来删除你的BLOG上的所有帖子…那么画面就会变得很美:一个搜索引擎的爬虫爬过,很快你就知道什么叫不作死就不会死了。)
可见,POST的GET的运用是需要分场合的。
结合网页实例判别请求类型
由于项目是关于视频网站bilibili的,网页实例也来自bilibili。
(使用chrome浏览器自带的检查工具获取network信息)
GET(myinfo)
需cookie和传入参数

POST(getinfo)
Form Data为机器时间与用户ID

元素定位及资源筛选
光是获得了网页内容,不加以处理将占用大量的空间。所以在进行存储之前,需要定位信息,进行信息的过滤。
这个时候就可以选用Xpath或者BeautifulSoup对网页内容(HTML/XML)内容进行分析。
Xpath
从dom网址寻找网址信息及标题信息
# -*- coding:utf-8 -*-
from lxml import etree
dom = etree.HTML(all_text) #all_text is a string object
url_list = dom.Xpath('//table[@class="list"]/tr[@class="even" or "odd"]/td/span/a[1]/@href') #find links (@href)
title = dom.Xpath('//*[@id="content"]/div[3]/h1/text()') #find titles (text())
print title
print url_list
BeautifulSoup
BeatufulSoup实例可以通过标签等对象直接进行结点资料的访问,与数据储存的对接口非常的好
prettify() 结构简明化函数,实例.标签可直接访问结点
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup as Soup
url = 'http://space.bilibili.com/218345/#!/'
response = requests.get(url).content
soup = Soup(response)
print soup.prettify()
print soup.title.string
print soup.a
print soup.h1
数据保存
- 不再赘述文件读写保存方式,可查询官方文档或中文教程
MySQL数据库
创建MySQL数据库,创建对应数据的表
(指令在cmd或terminal的mysql界面中输入)
CRATE TABLE bilibili;
USE bilibili;
CREATE TABLE `test` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`mid` varchar(11) DEFAULT NULL,
`name` varchar(45) DEFAULT NULL,
`sex` varchar(11) DEFAULT NULL,
`face` varchar(200) DEFAULT NULL,
`regtime` varchar(45) DEFAULT NULL,
`spacesta` int(11) DEFAULT NULL,
`birthday` varchar(45) DEFAULT NULL,
`place` varchar(45) DEFAULT NULL,
`attention` int(11) DEFAULT NULL,
`sign` varchar(300) DEFAULT NULL,
`attentions` text,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
多线程爬取
map()使得并行代码可以快速运行,而支持map()函数并行的库有multiprocessing.dummy和multiprocessing。
其中dummy库的多进程模块采用的是线程(在Windows中,进行CPU分配是以线程为单位的,一个进程可能由多个线程组成),这能够使得数据轻松的在这两个之间进行前进和回跃,特别是对于探索性程序来说十分有用。
# -*- coding:utf-8 -*-
from multiprocessing.dummy import Pool as ThreadPool
def getsource(url):
pass
pool = ThreadPool(1)
try:
results = pool.map(getsource, url)
except Exception:
pass
服务器代理
我选择的阿里云服务器在进行爬虫代理爬取的时候,经历了三个环节:
- 服务器配置(根据服务器官方文档进行)
- 爬虫运行环境设置(主要是Mysql及Python扩展库配置)
- 远程连接(windows自带的mstsc进程)
关于这些环节,网上都能找到相应教程
非典型又是什么?
到以上为止,一个基础的Python爬虫的常规构造过程包括但绝不限于上文提到的内容。
还有正则表达式,去重判断,或者是发送包的Form Data需要加密,构造爬虫的时候不仅可以选择基于 HttpClient的爬虫,还可以选择内置于浏览器引擎的爬虫(PhantomJS,Selenium)等细节本文没有提到。但是由于文章的重点并不是典型的爬虫写法,所以点到即止。
如果就以上提到深入下去,可以说日常生活中绝大部分能够接触到的网页,都可以用上述提到的内容进行信息爬取。
但是如果我没有接下来提到的这个项目,记录的角度可能就不是现在这样的了。
所谓非典型
首先要解决一个问题:为什么我叫这个项目为非典型爬虫。
这里主要介绍此类非典型爬虫适用的网页特性,以及具体的代码实现方法。
网页对象特性
像是上文中提到过的通过模拟浏览器发送请求,在获取信息后使用结点(BeautifulSoup或者Xpath及正则表达式)进行所需数据段的访问,可以说是一种万能的获取数据的方法。
但是就像下面关于BILIBILI用户页面的图片中,network-Headers里显示的一样,用户的信息是单独发过来的json文件(Response Headers: Content-Type: application/json; charset=utf-8)。对于json文件就存在着更加便捷的访问方式。
在了解了网页内容的基础上进行这样的操作,就仿佛把获取信息和信息筛选这两个步骤合并了,在处理数据上无疑轻松了不少。

Myinfo请求返回数据preview:
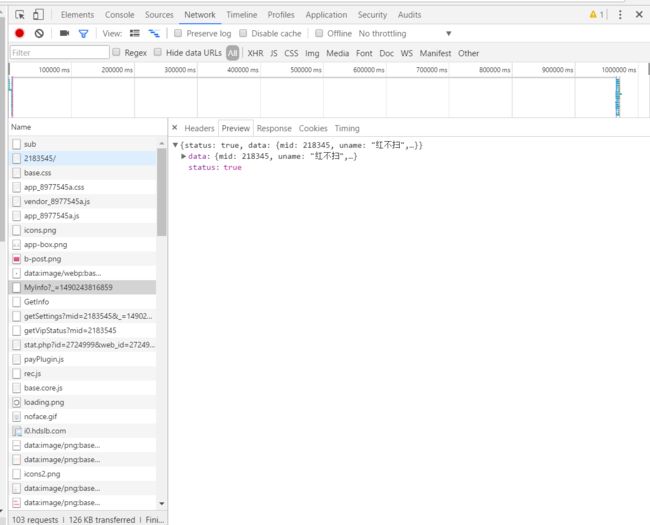
Getinfo返回数据preview:

从对比可以发现,MyInfo中和GetInfo两个请求返回的都是json内容,区别在于MyInfo获取方式为GET,GetInfo获取方式为POST。
Json内容的返回包使后续处理信息变得十分简便,只需要借用库函数json.loads()就可以实现对返回数据的提取,避免了分析网页相对结点提取信息的步骤。
而如果对GetInfo网站返回的json数据进行分析,可以发现返回包中已经包含其关注人的ID的list,对这个list的id进行遍历爬取,又可以获得一系列活跃用户的id,这样应该可以对特定大ip的用户人群进行用户类型统计。(有待完善)
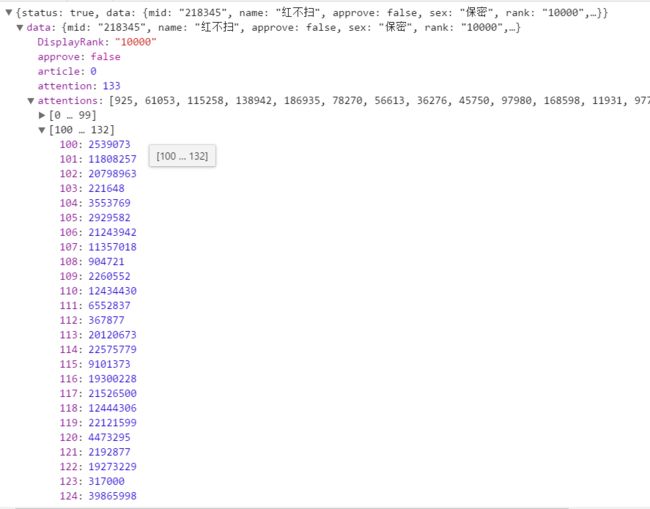
返回包处理&判重
JS文件处理
jsDict = json.loads(jsoncontent)
if jsDict['status'] == True:
pass #use the dict to take out message in the jsoncontent
判重
- 数据直接存入数据库,并通过PRIMARY KEY(id)判断是否已存在于数据库。
- 通过for i in range()语句,程序员自己定制爬取用户段
在这两个判重条件下,去重变成了似乎不是那么重要的东西(仅限本项目)
数据库重复信息显示:
try:
pass #codes of pushing the data into a table
except MySQLdb.Error, e:
print "Mysql_Error %d: %s" % (e.args[0], e.args[1]) # if is the same, print error message
总结
Python写就的典型爬虫基本可以应对常见的大部分网站,而此次介绍的非典型爬虫案例,则是根据个别网页特性进行针对方案写就的,在获取专门化的信息上提供了另外一种思路。
在想要得到的资料需要用一大串正则表达式才能够匹配到之时,如果资料的获取可以通过类似更加便捷的方式获取,这样的思路无疑会使代码功能得到简化。
但是鉴于并非所有的网站都用相同请求获得用户信息,真的必须使用正则的时候肯定也不少。在寻找快捷途径的之前,还是要求程序员要有扎实的基本功啊。(sign)
参考项目/代码
Requests: HTTP for Humans
Bilibili用户信息
Bilibili模拟登陆
post 相比get 有很多优点,为什么现在的HTTP通信中大多数请求还是使用get
使用python+xpath获取下载链接
Beautiful Soup Documentation
用map函数来完成Python并行任务的简单示例(对于multiprocessing.dummy的应用)
Python: what are the differences between the threading and multiprocessing modules?
如何应对网站反爬虫策略?如何高效地爬大量数据?