PowerBI于2日前更新,为何迟迟没有介绍更新的内容呢,这次涉及到两个很重大的更新:分级聚合(微软官方并未给出这个名字)以及PowerBI的查询编辑器(PowerQuery)开始支持 智能感知(千呼万唤始出来的功能)。
本文先介绍本次更新的其他内容,然后重点介绍分级聚合,让大家可以从整体上把握这个强大的特性。
本月更新的主要内容:
- 报表方面
- 散点图支持点阵图
- 从表或矩阵中复制值
- 内置主题
- 工具提示页正式发布且支持卡片图
- 分析方面
- 聚合(预览)
- Q&A支持RLS
- 自定义可视化
- Horizon Chart
- Text Enhancer by MAQ Software
- Advance Card
- Multi KPI
- Custom visual API updates
- 数据连接
- PDF file connector (preview)
- SAP BW connector – support for measure properties
- Dataflows connector (beta)
下面依次详细介绍。
散点图支持点阵图
散点图,是一个可以从多维反应数据状态的可视化对象,在PowerBI中散点图的默认计算逻辑是,针对某个点P,计算其在X轴的度量值以及计算其在Y轴的度量值。
因此,散点图默认的计算逻辑是让X轴和Y轴都放置度量值来进行计算,如下所示:
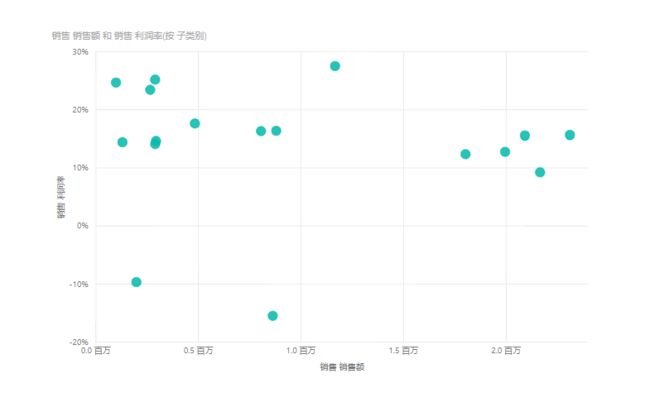
通过在X轴放置销售额以及在Y轴放置利润率,就可以同时计算任何一点的两个业务指标。
这虽然无可厚非,但显然并没有把散点图的能力全部释放,因为很有可能在X轴或Y轴并不需要考察度量值,而是放置属性(维度)。例如,在X轴可以放置维度,如下:
如果将维度同时放入详细信息,则会遇到错误:

可以看出,使用散点图的基本配置有两种选择:
- X轴维度,Y轴度量值,无详细信息粒度
- X轴度量值,Y轴度量值,有详细信息粒度
如果从DAX表查询的角度来看,散点图和点阵图确实有差异,点阵图的本质是对一个高粒度维度和一个度量值进行SUMMARIZECOLUMNS计算;而散点图的本质是对一个低粒度维度按两个度量值进行SUMMARIZECOLUMNS计算。由于很可能是低粒度维度,PowerBI必须对其结果进行高密度处理,会用到一个还没有发布的DAX函数,叫:SAMPLECARTESIANPOINTSBYCOVER。
当然,这并不妨碍我们去使用它,如果我们知道它的用法的话,例如:
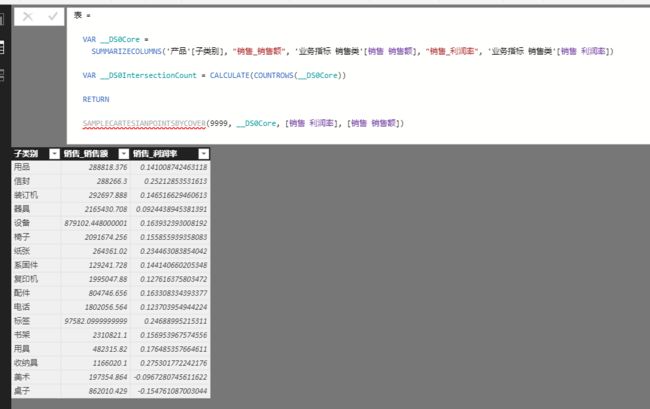
当然,从实际来看,我们几乎不会有这个需求,如果确实需要,不妨记得有这么一招即可。
从矩阵中复制值
这个很简单,完全是一个易用化的体现罢了,早该有了。目前仍然欠缺很多特性,例如从一个PBIX文件复制元素到另一个PBIX文件。
内置主题
主题,是一个很重要的课题。在PowerBI中对主题已经有了可以完全自定义的支持方案,但还未推出非常易用的表现使用方式,如:允许用户通过点击鼠标来设置主题,效果可以想象为:
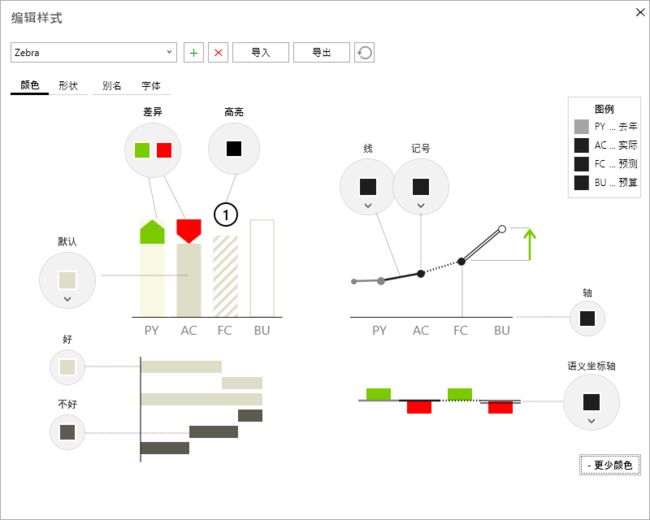
注意,这是想象的(ZebraBI的界面)。显然现在还仅仅停留在可以换个颜色:
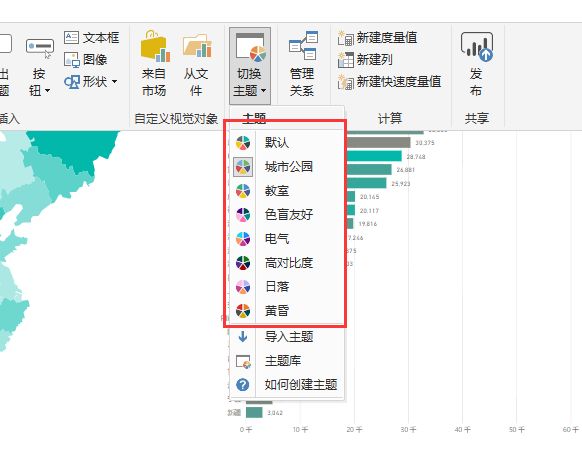
但相信这个方向应该逐渐会到来,毕竟有了她:

现在的主题就像是实习生,但相信在Chelsie Eiden的支持下,这些内容会越来越好。
工具提示页正式发布且支持卡片图
工具提示页不需要重复介绍,这是对默认工具提示的一个极大增强,对卡片图使用工具提示页的效果如下:
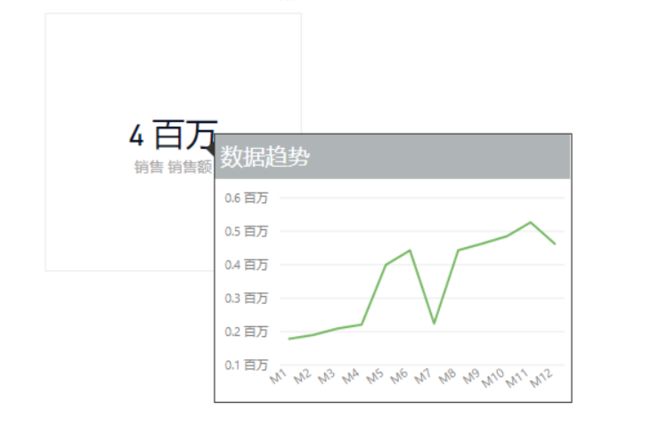
这样,我们又可以实现很多不同的交互易用性增强效果。
聚合(预览)
这里所说的 聚合 ,准确讲应该是 分级聚合 机制,这是极大提升查询性能的机制,稍后会花大量篇幅详细介绍。
Q&A支持RLS
RLS以正式发布,在此前的文章以详细说明过基于RLS在PowerBI中实现动态权限控制的终极方案,为了让该方案更加终极完美,我们将提供关于 【动态权限控制的专题剧场版】套件发布。
我们一起看下其效果:
用户权限配置:

角色权限配置:
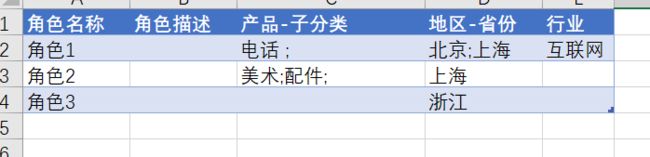
用户角色配置:

这样,可以根据实际情况仅仅在Excel中对用户或角色配置权限,实现全面动态性和灵活性,如下所示:

可以根据企业的实际情况直接或通过角色间接地为用户赋予权限,在运行时会全面检查所有权限并赋予用户。发布后,如果需要修改权限,仅仅只需要修改Excel配置文件而不需要重新编辑PowerBI文件。
这里的演示为了诠释RLS作为PowerBI权限控制的机制,可以非常强大和灵活的实现企业需求。该解决方案随后将以独立主体产品发布。预售:88元(正式发布后定价:188元)。(含方案示例及剧场版视频讲解)
自定义可视化
大家自己看吧,请参考官方文档,实在没啥好讲的。
PDF file connector (preview)
本次更新为PowerBI增加了可以读取PDF文件中表格的连接器。
请开启预览功能后才可以使用,可以看到PDF文档中以表格形式存在的数据,如下:
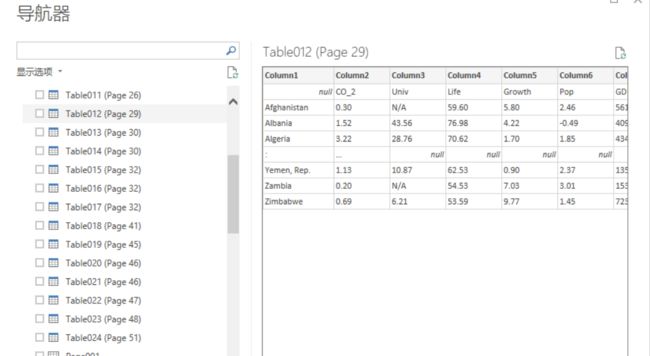
这对于标准化导出的PDF文件读取表数据是很有意义的。
M 智能感知
这可以说是本次更新中最大的两个亮点之一了,但却没有特别可以介绍的,因为大家像编辑器一样的用即可,如下:
在Excel120出品的PowerBI基础系列教程中已经给出了PowerQuery的常规用法及三大杀招,有了M智能感知,可以帮助我们快速找到函数,不必去查PQ文档了,这是很有生产力的特性。只可惜这个只能感知还有很大的提升空间,它只能在打开高级编辑后才可以使用,不能在公式栏使用比较遗憾,在这方面,已经有很多人立即反馈给微软了,希望在接下来的更新中可以有更好的补充。
重头戏:分级聚合
其实在PowerBI的7月更新中就介绍了一种 复合模型 机制,作为微软官方大多数情况是阐述一个特性是什么以及如何设置,但在背后的逻辑则往往在帮助文档中并未仔细提及,最显然的例子某过于官方文档对于 PowerBI DAX 的解释,如果完全仅仅按照官方文档来学习 DAX,相信有很多问题是搞不清楚的,幸亏有SQLBI.COM的意大利老师在此前多年对 DAX 的研究来帮助我们进一步解释。
对于 聚合 (目前官方的叫法),其实有很多背景,甚至相当复杂。这里给出一幅图来做简单说明。
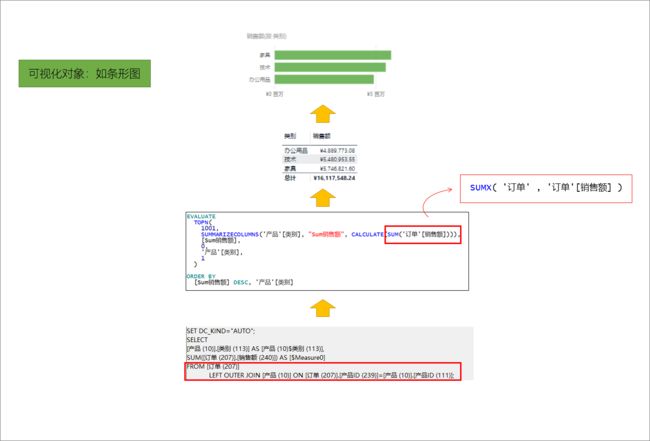
仔细观察上图,可以看出在聚合运算时,SUM实际将以SUMX执行,而SUMX作为迭代器将对事实表做全表逻辑扫描,并形成左外连接结构以返回查询结果。在 PowerBI 中,任何一个可视化对象,即使是最简单的一个条形图,都涉及 深入至原子粒度 数据的查询。其大概步骤包括:
- 【报表层】PowerBI 系统引擎根据可视化元素生成可以支持该可视化元素的 表结构 T1
- 【逻辑层】PowerBI 系统引擎根据 T1 的结构生成 DAX查询,并将该查询发送给 数据模型引擎(姑且这么简单称呼,更准确为 Vertipaq 列式存储引擎)
- 【模型层】由 数据模型引擎 在 数据模型 中完成查询
在忽略一定技术细节的合理性下,我们从逻辑上将这个过程大致分为三层:报表层,逻辑层,模型层。
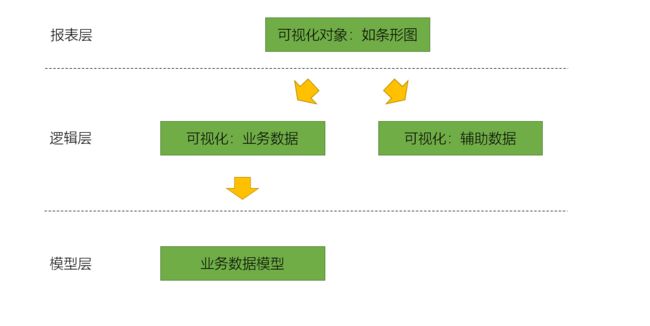
在这三层中会产生如下的依赖和作用关系:
- 【报表层】的可视化对象依赖于汇总的业务数据以及辅助数据
- 【逻辑层】包括汇总的业务数据,如:按类别汇总的销售额,依赖于业务数据模型
- 【逻辑层】包括用于支撑可视化的辅助数据,如:自定义分组,ABC分组,自定义排序等
- 【模型层】包括真正的所有业务数据
在整个BI的调用堆栈中,自上往下,也就是从可视化对象到原始数据,应该非常科学严谨地处理好每个环节以使得BI可以成功。在这个过程中,不同厂商从一开始就尝试各自的方法论。
例如,这里我们用PowerBI的机制与Tableau在报表逻辑层与报表展现层进行一个对比,会发现Tableau的表计算正是直接基于聚合后的业务数据进行操作,不再涉及对底层数据模型的调用,这使得其仅仅涉及表计算时候,性能会很好;而PowerBI并未提供像Tableau一样的 轻量级 表计算方法,PowerBI 一以贯之地使用 DAX,从设计上,DAX相比表计算显得更重,因为DAX直接处理原子数据。Tableau在逻辑层和报表层的聚合不足的情况下,会使用详细级别特性再向更原子粒度处理。
从这个层面看,Tableau在报表层和逻辑层有非常完善的处理方式;而PowerBI一以贯之的DAX总是那么重,即使不需要原始数据,它也会用原始数据来做计算。
因此,PowerBI 其实有两大痛点:
- 第一,再简单的表面聚合的可视化如果需要辅助数据,其实都是在建立模型,而这个模型却不是业务模型。这纯粹是为了弥补PowerBI在可视化报表层和逻辑层的薄弱而使用重量级的模型。
- 第二,相对于处理聚合后的数据,DAX是重量级的,因为DAX直接处理原子数据,PowerBI不太可能再做出一门轻量级的函数来处理表面的报表运算,因此,DAX处理的原子数据应该分类讨论,对于大多数报表需求,应该保持为聚合过的。
这里要介绍的 聚合 特性,其实是针对 PowerBI第二痛点 的改进。
再往下走就到了模型层,逻辑层从模型层获取真正的业务数据,这个模型层可以建立在PowerBI内部,也可以把这个模型层的物理实现交给数据库或其他数据源(如:SQLServer,SSAS,多维模型等),因此,PowerBI的理想架构大致应该为:
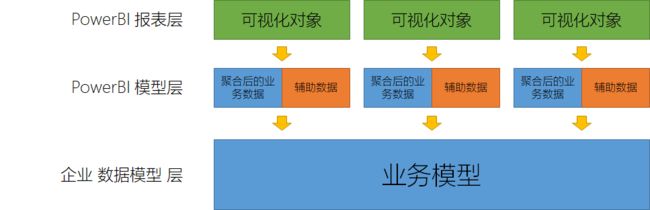
我们常见的PowerBI数据建模可以这样看:
- 没有或不需要企业数据模型层,但所有数据都进行 PowerBI 模型层。大部分企业或个人都在广泛地使用这种模式。
- 已经有了非常完善的企业数据仓库(如:以SQL Server实现)且用户需求非常简单,无需辅助数据,但数据量级非常庞大(如:数千万级以上),通常采用了 DirectQuery模式而忽略了 PowerBI 模型层。
- 更真实的情况,存在企业级数据仓库,且业务需求也非常复杂,需要平衡 PowerBI 模型层 以及 企业数据模型层,则可以同时采用 DirectQuery 模式 与 PowerBI 模型层,当然这也是为了平衡 DAX引擎的工作模式而需要考虑的。
聚合机制,正是为了满足这种复杂性而生的,伴随聚合机制的就必须可以让 PowerBI 模型层 与 企业数据模型层 同时兼容工作,也就是所谓的 复合模型。
这里,就不再深入展开 PowerBI 在平衡这些选择上的更深入考量,当然这些都是个人观点和使用感悟,不代表微软的官方说法。在后续的文章和教程会更详细地分析这些特性和使用场景及最佳实践。更重要的是等待PowerBI赶快弥补报表层的轻量级功能,不要分个组、排个名、汇个总还要写无比复杂的DAX,相信这个痛点也正难到了 PowerBI 的设计者们。能不能在易用性上与 Tableau 比肩也看这些了。
详解分级聚合特性
前面可以说是简要描述了为什么会存在分级聚合,简单说,就是为了平衡PowerBI模型层与企业数据模型层的性能而设计的机制。
我们来举例说明,假设有10亿交易数据,为了显示不同产品类别的销售额,不可能加载十亿数据,合理的计算逻辑应该是:
- 加载用户80%可能用过的聚合后的业务数据构建PowerBI模型层 M0。
- 如果用户查询的业务数据结果在M0存在,则直接返回结果。
- 如果用户查询的业务数据结果在M0不存在,则将该查询进一步发送给企业数据模型层 M1。
- 由企业数据模型层 M1 计算完毕并返回给 PowerBI,再显示结果。
我们举例如下:

如果不考虑隐藏状态的两个表,这是典型的符合Kimball维度建模的一个星型结构
这个结构可以理解为:
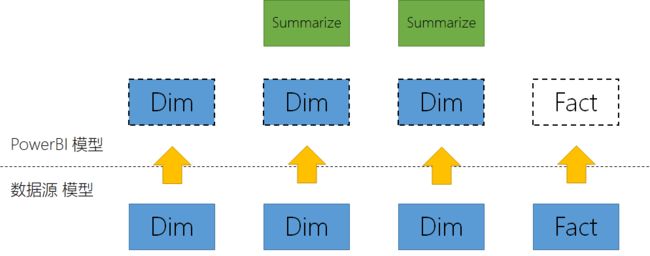
- 数据源的维度表按 混合存储模式 映射到PowerBI模型,含义为当可以从PowerBI模型获取时就从PowerBI模型获取,如果不能则发送至数据源获取。这特别适合于有限的维度表。
- 数据源的事实表由于海量数据限制(如:100亿行),无法加载进入PowerBI模型,即使是PowerBI Premium也不是合理的解决方案,则以DirectQuery模式(虚拟模式)映射到PowerBI模型,含义为当涉及到含有该事实的查询,发送至数据源计算,除非其聚合计算已经预先保存在PowerBI模型。
- 由于很多情况我们可以知道用户要如何操作或可能的操作,就可以将对海量事实的聚合计算预先保存在PowerBI模型中使上述规则可以命中聚合以直接返回结果。
请再仔细观察上图,本质上,如果你能猜中用户的查询,则直接给出预先准备的答案,否则该怎样处理就怎样处理。这句话道破了整套PowerBI查询优化的本质。在传统的多维数据模型Cube中,这又叫 预计算。在实际中,这是非常可行的,因为我们的客户是几乎完全在我们的预期下工作的。
演练PowerBI聚合特性
请确保下载了2018年9月更新后的PowerBI Desktop,如下:

并开启了相关的预览功能:

为了演练该功能,需要有数据库类的数据源配合,这也符合模拟企业级的生产环境。
以 混合存储模式 加载如下表:
- DimGeography
- DimCustomer
- DimPromotion
- DimDate
- DimProduct
- DimProductSubcategory
- DimProductCategory
如下:
以 DirectQuery存储模式 加载如下表:
- FactInternetSales
如下:
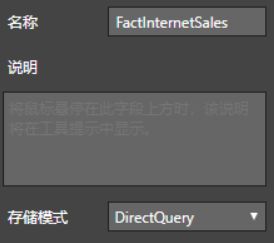
以 导入存储模式 加载如下汇总表:
- Sales Category Agg
- Sales Agg
如下:
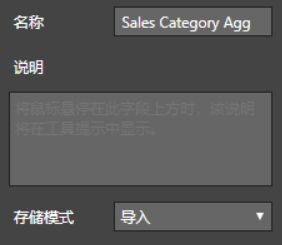
其中,
Sales Category Agg 是表 FactInternetSales 的 SalesAmount 按 ProductKey 汇总;Sales Agg 是表 FactInternetSales 的 SalesAmount 按 DateKey, CustomerKey, ProductKey, 汇总。这些内容可以使用 PowerBI 查询编辑的分组来实现。
如下:
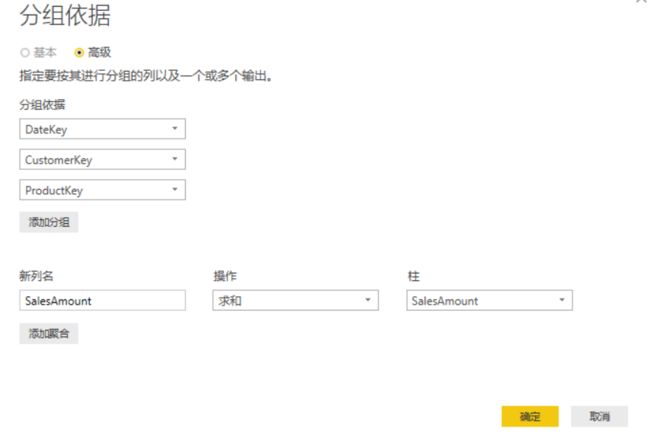
值得一提的是 PowerBI 的 PowerQuery 查询对此将做完全的优化并整体转换为等价的 SQL 发送给 SQL Server 来处理,如下:

可以直接看看在服务器运行这段自动生成的SQL的效果如下:
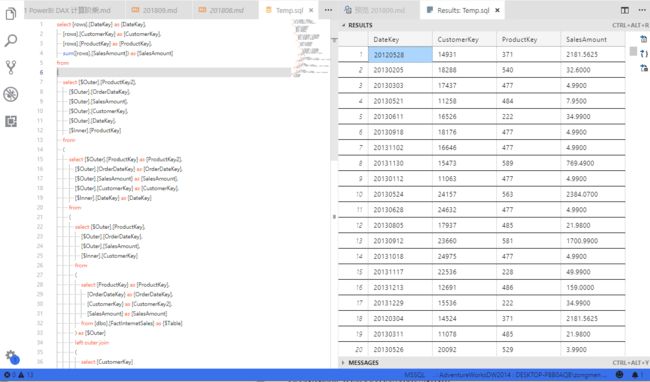
插曲:特别推荐 Visual Studio Code 编辑器。
此时需要对充当聚合功能的表进行设置:

如下:
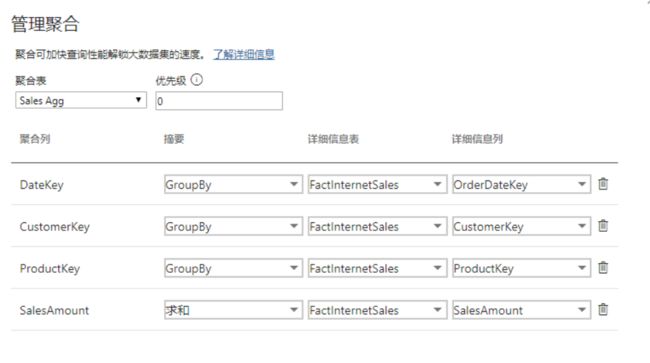
类似的:
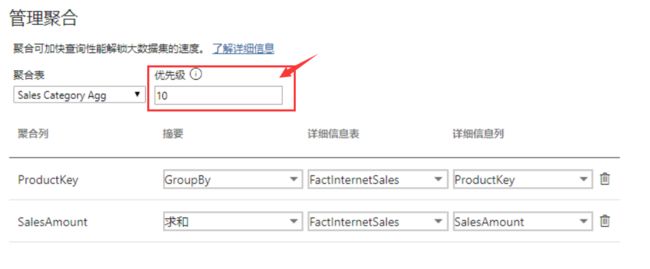
可以看出:
Sales Category Agg 的聚合粒度比 Sales Agg 更高,因此其优先级也应该更高。此时,我们就有了这样的一种查询体系,如下:
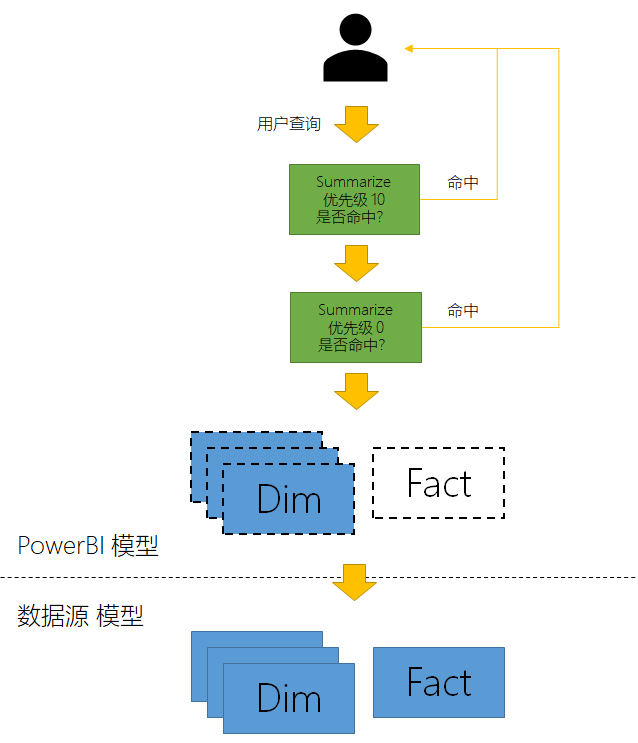
- 如果可以命中聚合,则直接返回结果。
- 命中聚合以优先级大小来匹配。
- 如果无法命中聚合,则转为正常查询。
- 如果PowerBI的存储无法支持查询,则转为发送至数据源计算。
以上,就是聚合的全部细节。
验证聚合的执行
接下来,我们验证下聚合是不是真的按照我们所想的顺序执行了。这里需要准备:
- SQL Server Profiler 监控 PowerBI 诊断端口
- DAX studio 查询 PowerBI 诊断端口
首先,用 DAX Studio 查询下PowerBI的本机端口,如下:

接着,用 SQL Server Profiler 监控 PowerBI ,如下:
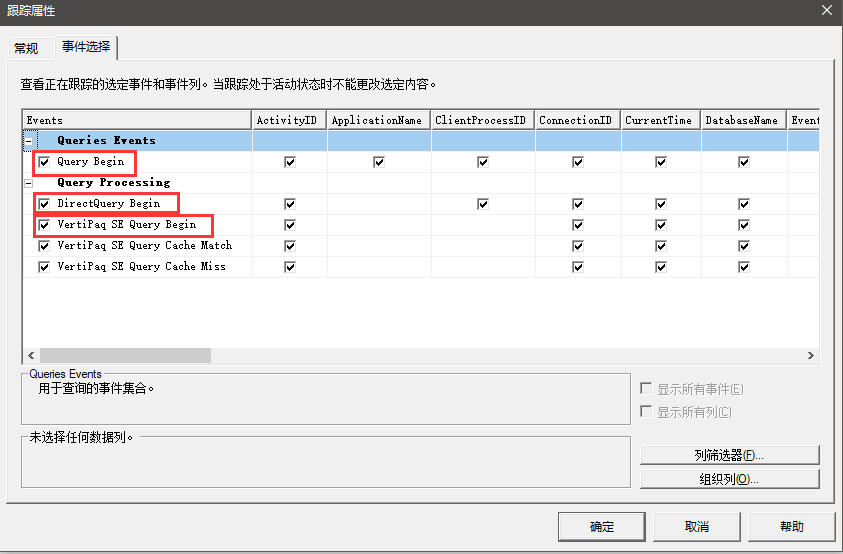
这里开启监控三个重要的事件:
- Queries Events / Query Begin :指示产生查询
- Query Processing / DirectQuery Begin:指示将查询发给数据源
- Query Processing / VertiPaq SE Query Begin:指示命中了当前PowerBI引擎
对于同一个Queries Events / Query Begin,如果命中了当前PowerBI引擎而不需要将查询发给数据源,则说明聚合起了作用。
实验1 - 命中PowerBI引擎的非聚合
我们将 DimPromotion 的 EnglishPromotionName 拖入报表,由于该维度是混合存储模式,这时会命中PowerBI引擎,结果如下:
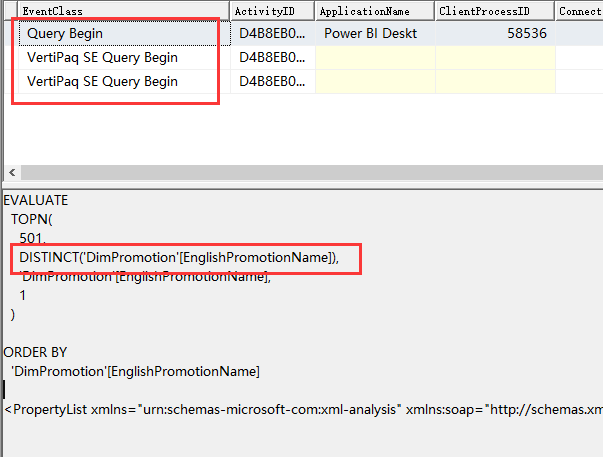
因此,并没有产生远程的DirectQuery查询。
实验2 - 命中PowerBI引擎的聚合
我们将 DimDate 的 CalendarYear , ClendarQuarter 以及 FactInternetSales 的 SalesAmount 拖入报表,这将命中 Sales Agg 聚合,结果如下:
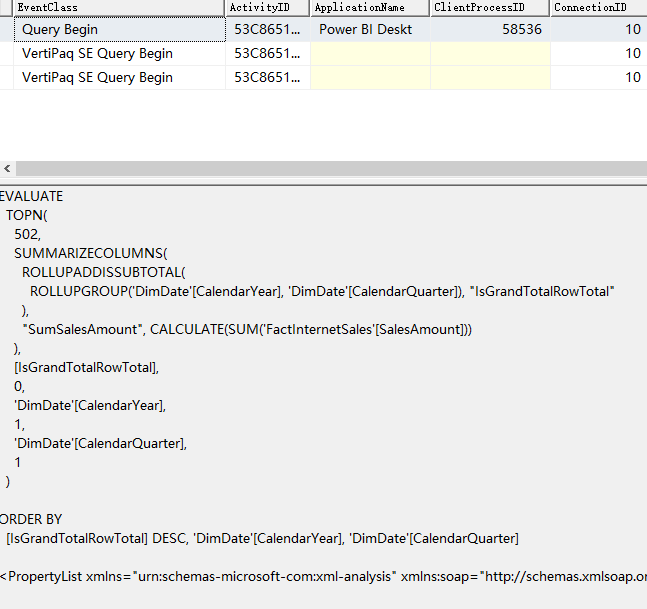
查询的结果为:
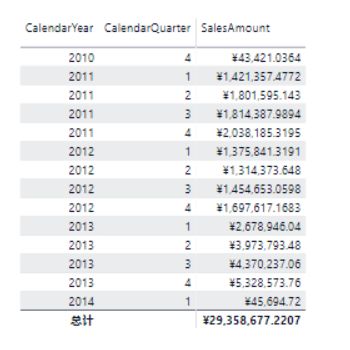
由于命中聚合,直接返回查询结果,并不会产生远程的DirectQuery查询。
实验3 - 无法命中PowerBI引擎的聚合
如果综合实验1和实验2,将得到一个无法命中PowerBI引擎聚合的结果,同时这也无法在纬度中找到答案,因此这将产生一个发送到远程的 DirectQuery 查询。
我们将:
- DimDate 的 CalendarYear , ClendarQuarter
- DimPromotion 的 EnglishPromotionName
- FactInternetSales 的 SalesAmount
拖入报表,这将形成无法命中的查询,如下:
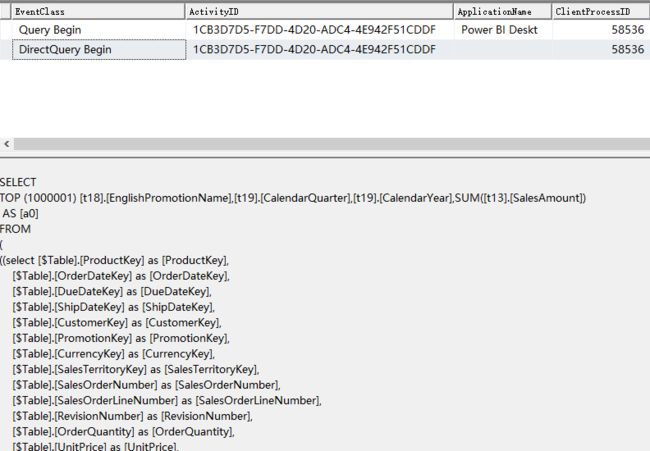
由于无法命中,必须产生DirectQuery发送至远程完成查询。
查询的结果为:
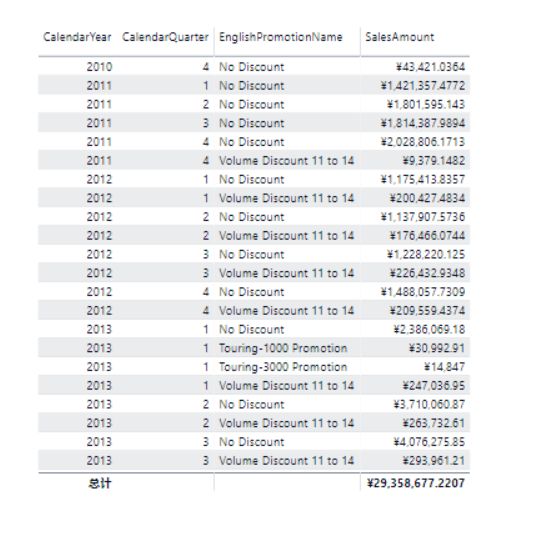
实验4 - 命中PowerBI引擎的聚合并按高优先级执行
如何可以同时命中不止一个聚合,则将按高优先级类执行。
我们将 DimProductCategory 的 EnglishProductCategoryName 以及 FactInternetSales 的 SalesAmount 拖入报表,这将同时命中 Sales Agg 和 Sales Category Agg 聚合,但由于 Sales Category Agg 的优先级更高,因此它应该胜出,其实际结果如下:
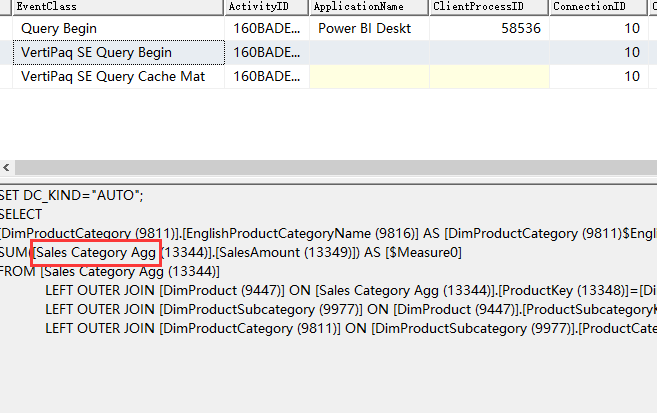
可见,首先是命中了聚合,其次是命中了高优先级的聚合。
实验5 - 错过高优先级聚合但命中其他聚合
如果无法命中高优先级的聚合,是否可以被低优先级的聚合进一步接住呢,进一步来通过实验验证。
我们将:
- DimDate 的 CalendarYear , ClendarQuarter
- DimProductCategory 的 EnglishProductCategoryName
- FactInternetSales 的 SalesAmount
拖入报表,这将错过 Sales Category Agg 聚合但却命中 Sales Agg 聚合,其实际结果如下:

至此,聚合的特性全部解释清楚并验证完成。
总结
不想特别强调很多显而易见的东西,如M终于有智能提示了。本次更新的重大意义更在于为我们展示了PowerBI将如何应对处理大规模数据的 平衡的艺术。从某种意义上说,DAX是一种重型函数,虽然它可以高性能地对原子级数据进行聚合,但也架不住很多报表级的辅助数据掺进来一起搞。
我们简单论述了分级聚合的体系以及框架结构,并详细解释了PowerBI聚合的特性,最后通过5个实验全面理解了这些特性。虽然还只是预览阶段,但我们不仅仅是知道这个特性,我们需要的是掌握并洞悉其背后的原理。
PowerBI 仍然快速迭代着,下期将可能发布在PBI文件之间复制可视化对象,这将实现很多生产力提升。
另外,在微软的 Microsoft Hackathon 项目类中,鼓励为PowerBI添加更多办公特性,相信一大批好的特性将在未来进一步完善PowerBI,我希望是完善在报表层和逻辑层的特性以减少对DAX语言的重型调用依赖。
最后,按微软的讲法,PowerBIDesktop将被打造成 数据PPT,这也许是PowerBI的一个新的定位。
希望大家不仅仅听说一下这些特性,可以亲自动手按照上述描述来实践一下,做到:

这让想起,杰克韦尔奇所说:“你们知道了,但是我们做到了。”以此和伙伴们共勉。这也许就是那一点点不同的所在。