摘要: 如何判断偏差和方差?我们应该如何降低误差?本文将就这两个问题探讨如何使用学习曲线降低这两个主要误差。
机器学习模型两个主要的误差来源:偏差和方差。在构建模型时,设法降低这两个主要误差,模型的准确度会更高。本文将就这两个问题探讨如何使用学习曲线降低这两个主要误差,我们将使用真实的数据集,并尝试预测发电厂的电力输出。
偏差-方差权衡(trade-off)
在监督学习中,假设特征和目标间存在某种关系,并用模型预测这种未知的关系。假定这个假设成立,则称这个描述特征和目标间关系的模型为f。
实际应用中,f几乎是完全未知的,我们试着用模型f(^)预测(注意二者标记略有不同)。使用某一数据集会输出一个f(^),使用不同的数据集,或许会输出不同的f(^)。随着训练集的改变,则输出不同的f(^)。随着数据集的改变而f(^)发生变化的量被称为方差。
使用线性回归或随机森林等不同的方法预测真实f。例如,线性回归假设特征和目标之间存在线性关系。然而,对于大多数实际场景来说,特征和目标之间的真实关系是复杂且非线性的。简化假设会给模型带来偏差,对真实关系的假设错误越多,偏差越高,反之亦然。
一般来说,在某些测试数据上进行测试时,模型f(^)会有一些误差。偏差和方差只会增加误差,若希望模型的误差最低,则偏差和方差需要降到最低。但是这不太可能,因此偏差和方差之间需要有个权衡。低偏差的方法非常适合训练数据,如果改变训练集,则会得到明显不同的模型。
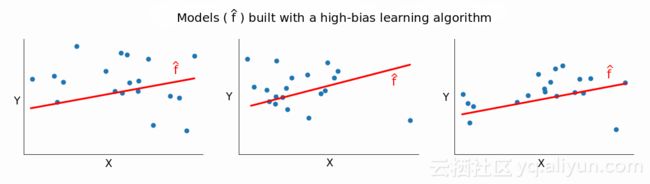
如果训练集改变时,模型f(^)没有太大的改变,则方差很小,这说明偏差越大,方差越小。
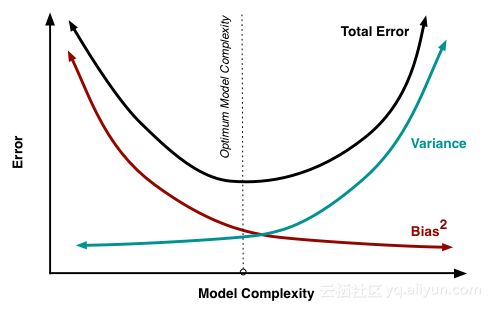
我们从数学上解释下想要较低偏差和方差的原因:方差和偏差只会增加模型误差,我们希望偏差较低以避免建立一个过于简单的模型。在大多数情况下,一个简单的模型在训练数据上表现很差,且极有可能在测试数据上有糟糕的表现。
同样,我们希望方差较低以避免建立一个过于复杂的模型。这样的模型几乎完全适合训练集上的所有数据点。然而,训练数据通常包含噪音,而且只是一个更大样本集中的一个样本。复杂的模型能捕捉到噪音,对样本外数据进行测试时,性能通常较差。这是因为模型很好的学习了样本训练数据,它对样本内的数据很了解,但是对其他数据一无所知。然而,在实际应用中不能同时拥有较低的偏差和方差,因此要在二者之间做一个权衡。
学习曲线
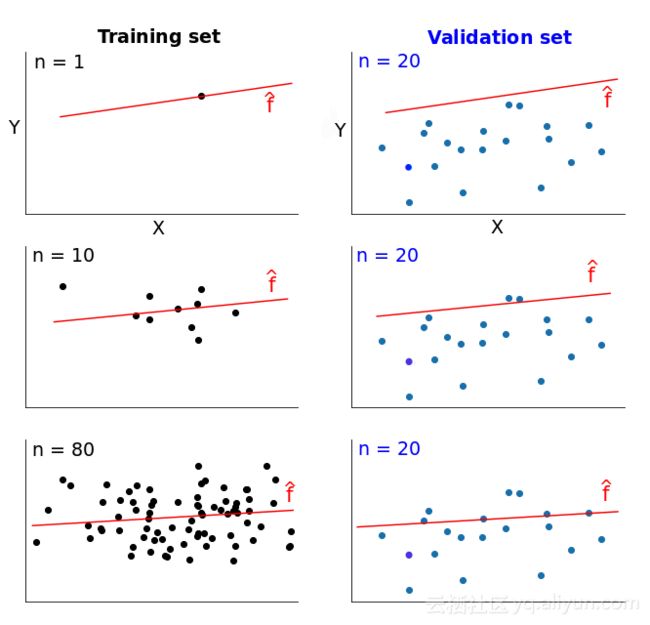
将现有数据一分为二:训练集和验证集。从训练集取出1个实例预测模型。再测量模型在验证集和单个训练实例上的误差。单个训练实例上误差为0,因为完全适合单个数据点很容易,但验证集上的误差将会很大,因为该模型是为单个实例构建的,无法精确的推导出其他数据。再分别取50、100、500……直到使用整个训练集,训练集改变时,误差值随之改变。
有两个误差值可供测量:验证集和训练集。根据训练集大小的变化绘制两个误差,得到两条曲线,这两条曲线被称为学习曲线。学习曲线展示了随着训练集数据量的增加,模型误差的变化。
N=1时(N为训练实例的数量),该模型完全适合单个训练数据点,误差为0,但并不适合于20个不同数据点的验证集,误差要高的多。随着N增大,模型不再适合训练集,训练误差变大。然而模型是在更多数据上训练的,因此可以更好的适应验证集,验证误差减少。学习曲线如下。
数据说明
上述学习曲线是理想化的表现,下面在实践中使用真实数据进行探讨:建立预测电厂每小时电能输出的回归模型。使用pandas库中的read_excel()函数读取存储数据的.xlsx文件。

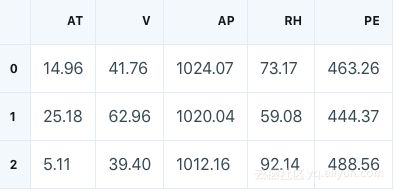
每列含义如下:
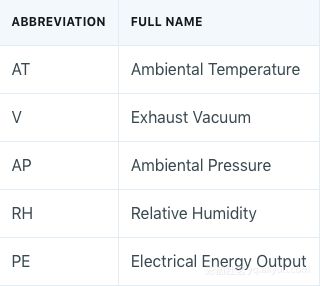
PE是目标变量,描述每小时电量净值的输出,所有其它变量都是潜在特征值,也是小时平均值,而不是像PE那样的净值。
确定数据集的大小
训练集的最小值是1,最大值是训练集中实例总个数。我们的数量集有9568个实例,因此最大值为9568。使用80:20(训练集:验证集)的比例确定训练集有7654个实例,验证集有1914个实例,则产生学习曲线的最大值为7654。
在这里,我们使用如下6个范围值,针对每个指定数值分别训练新的模型。
使用scikit-learn中的learn_curve()函数生成回归模型的学习曲线
代码单元如下图所示,具体含义请阅读原文:

learning_curve()的返回值如下:
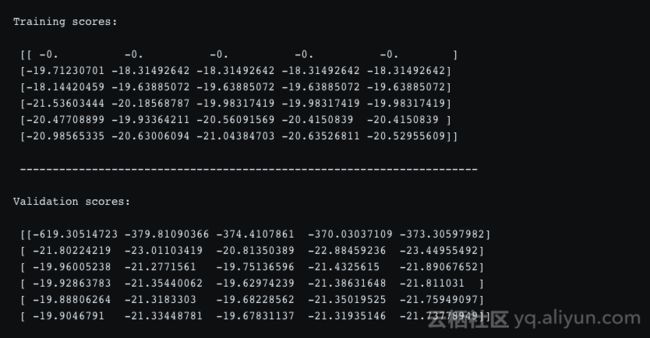
我们得到六行,每行有5个误差值。这是因为learning_curve()运行k折交叉验证,其中k由给定cv参数给出。本文cv=5,则有5次分割。每次分割,给定训练集大小,模型被训练。上图两个数组中,每列表示一个分割,每行表示测试集大小。训练误差表如下图所示。
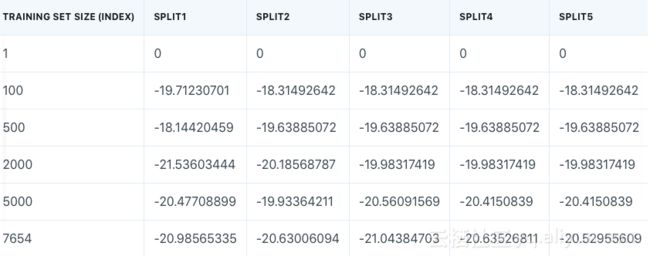
为了绘制学习曲线,只需得到每个训练集大小的单个误差,而不是5。在下述代码中,取每行平均值,并反转误差值的符号。请注意,训练集上的一些误差值是相同的。N=1时,误差值相同是预期内的,但是除了最后一行,也有很多相同的值。这是由于每次分分割时,没有对训练数据随机化处理。因此需要将函数learning_curve()中shuffle参数设为True,随机化每个拆封的训练数据索引号。
线性回归学习曲线——高偏差和低方差
使用matplotlib工作流绘制训练集和验证集的学习曲线:
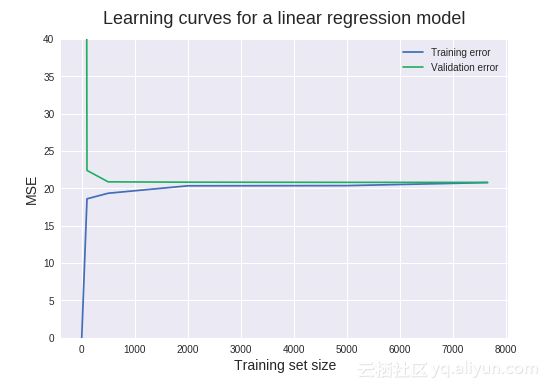
如上图所示,N=1时,MSE=0,这是因为模型可以完全拟合单个数据,因此预测是完美的。N=1914时,MSE=423.4,这是将y轴范围限制在0-40范围内的原因,可精确读取大部分MSE值。MSE如此高,是因为单一数据点上训练的模型不可能精确的推广到其他1914个新实例中。
当N增加到100时,训练MSE急剧增加,而验证MSE急剧降低。线性回归模型并不能完全预测所有100个训练数据,因此训练MSE>0,因为使用了更多数据,模型在验证集上表现要好很多。当N增加到500时,验证MSE基本保持不变,这表明,增加更多的训练数据也不会构建出更好的模型。现在来判断偏差和方差,一个偏差问题的主要指标是高质量验证误差。这里,验证MSE最终停滞在约20这个值上。让我们用领域内知识来回答这有多好。
从技术上来讲,20的单位是(MW)2(兆瓦平方),目标列值单位是兆瓦。20(MW)2的平方根约为4.5MW。每个目标值代表每小时净电量输出,所以模型每小时平均减少4.5MW。因此,4.5MW相当于4500个手持式吹风机产生的热量。预测一天或更长时间的总能量输出,则需要叠加。
模型具有低偏差还是高偏差需要看训练误差,如果训练误差很低,则预测模型对训练数据有很好的拟合度,则对该组数据具有低偏差,反之,对该组数据具有高偏差。在这里,训练MSE为20是相当大的数值,因此它有较高的偏差。
评估方差的方法如下:
(1)检测验证和训练学习曲线之间的间隔。训练和验证误差之间的关系:间隔=验证误差-训练误差。误差差异越大,间隔就越大,方差就越大。因此,上图中方差很小。
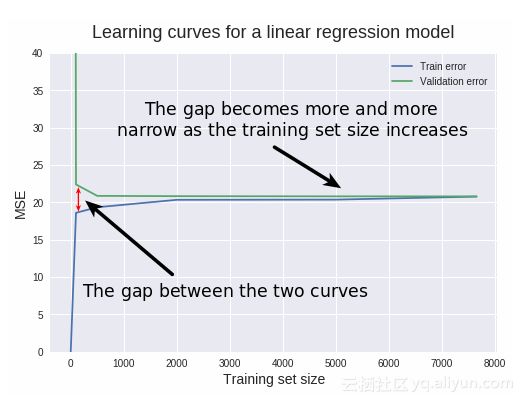
(2)检测训练MSE值及变化趋势。高训练MSE值也是一个检测低方差的快速方法。如果算法方差很小,改变数据集时,算法会产生简单且相似的模型,不能很好地适应训练数据(不适合数据),所以期望得到高训练MSE值。因此,高训练MSE值可以作为低方差的指标。该模型的训练MSE值约为20,因此方差很小。
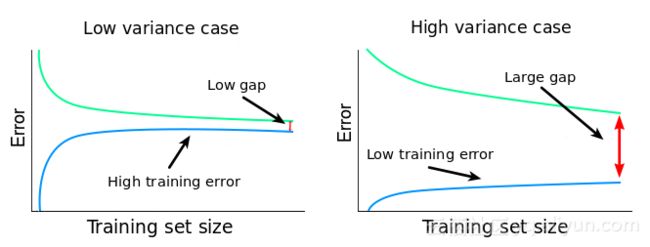
我们可以得出以下结论:该算法是高偏差和低方差,它对训练数据欠拟合;该算法增加训练数据的实例(行)并不可能会构建更好的模型。
一般来说,处理高偏差和低方差方法如下:(1)在更多特征上训练,增加模型复杂度降低偏差;(2)正则化阻止了算法更好的拟合数据。减少正则化方差将会提高,偏差将会降低。
随机森林学习曲线—低偏差和高方差
用上述工作流绘制非规范化的随机森林回归的学习曲线,为了比较,还展示了上述线性回归模型的学习曲线。
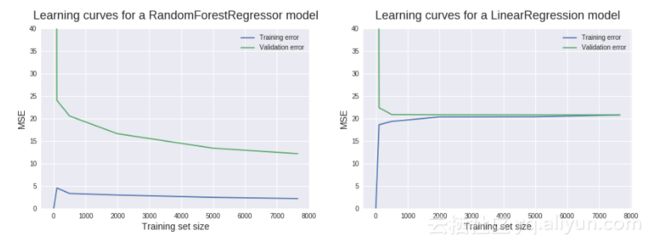
如上图所示,该模型具有低偏差,高方差。间隔较大、训练误差较低也表明这是一个过度拟合的问题:模型在训练集上表现良好,但是在验证集上表现很差。在这里,添加新的训练实例很可能构建更好地模型。验证曲线在最大训练集上没有趋于平缓,因此仍有潜力收敛到训练曲线,类似于线性回归的收敛。结论如下:
该算法(随机森林)具有高方差和低偏差,对训练数据过度拟合;该算法添加更多的训练实例可以构建更好的模型。
改进模型的方法如下:
·增加更多的机器学习训练实例。
·增加算法正则化。
·减少当前训练数据特征数量。
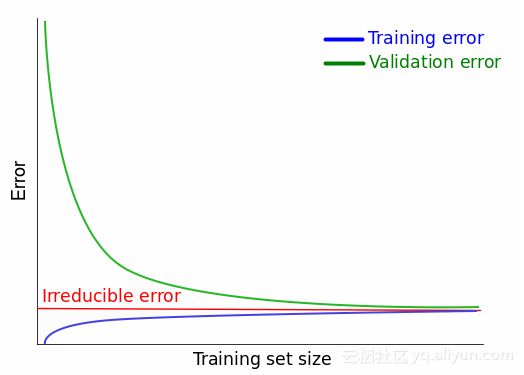
理想的学习曲线和不可约误差
学习曲线可以在机器学习工作流上的每个点快速检测模型。回归模型最完美的情况是两条曲线收敛到MSE=0,不论是在理论还是实践中都是不可能的,这是由于存在不可约误差(irreducible error)。
当我们建立一个模型来映射特征X和目标Y间关系时,首先假设存在这种关系。假定这个假设存在,则描述X和Y间的关系如下:
Y = f(X) + irreducible error(1)
这里存在一个误差是因为Y不仅是有限数量特征X的函数,可能还有很多其它特征影响Y的值(我们所没有的特征),也可能是X包含了测量误差。因此,除了X外,Y也是不可约误差的函数。
在用f^(X)估计f(X)时,引入了另一种误差,称为可约误差:
f(X) = hat{f}(X) + reducible error(2)
将公式(1)中的f(X)替换可得:
Y = hat{f}(X) + reducible error + irreducible error (3)
建立更好的模型能降低可约误差。如公式(2),若可约误差为0,估计模型f^(X)则为实际模型f(X)。但从公式(3)可知,即使可约误差为0,依然存在不可约误差。因此,不管我们的模型预测的有多好,都会存在一些无法降低的误差,这就是误差称为不可约的原因。
因此实际应用中,最好的学习曲线是收敛到某个不可约误差值,而不是理想误差值(MSE的理想误差值是0,其它误差度量有不同的理想误差值)。不可约误差的真实值几乎是未知的,我们还假定不可约误差与X无关,这意味着无法用X找到真正的不可约误差:irreducible error≠g(X)
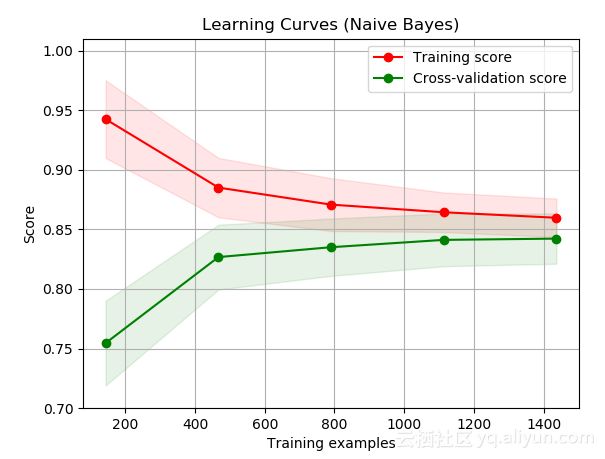
分类学习曲线
分类学习曲线和回归模型的工作流几乎完全相同,主要区别它有另外一个适合评估分类器性能的误差。如下图所示,训练误差高于验证误差的学习曲线,这是由于准确描述模型的好处:精确度越高越好。另一方面MSE描述了一个模型的糟糕程度:MSE越低越好。
描述模型有多差的误差度量,不可约误差给出一个下限:不能低于该下限值。描述模型有多好的误差度量,不可约误差给出一个上限:不能超出该上限值。在很多技术著作中,贝叶斯误差率通常用来指代分类器的最佳误差值,类似于不可约误差。
以上为译文。
本文由阿里云云栖社区组织翻译。
文章原标题《learning-curves-machine-learning》,译者:Mags,审校:袁虎