.Azkaban工作流引擎和Flume数据采集
Azkaban介绍
一、Azkaban简介
Azkaban是由Linkedin开源的一个**批量工作流任务调度器**。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。简而言之就是一个工作流调度系统。
为什么需要工作流调度系统?
因为一个完整的数据分析系统通常都是由大量任务单元组成:shell脚本程序,java程序,mapreduce程序、hive脚本等
而各任务单元之间存在时间先后及前后依赖关系
为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
常见工作流调度系统
在hadoop领域,常见工作流调度系统有:Oozie, Azkaban,Cascading,Hamake
下面的表格对上述四种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考
|
特性
|
Hamake
|
Oozie
|
Azkaban
|
Cascading
|
|
工作流描述语言
|
XML
|
XML (xPDL based)
|
text file with key/value pairs
|
Java API
|
|
依赖机制
|
data-driven
|
explicit
|
explicit
|
explicit
|
|
是否要web容器
|
No
|
Yes
|
Yes
|
No
|
|
进度跟踪
|
console/log messages
|
web page
|
web page
|
Java API
|
|
Hadoop job调度支持
|
no
|
yes
|
yes
|
yes
|
|
运行模式
|
command line utility
|
daemon
|
daemon
|
API
|
|
Pig支持
|
yes
|
yes
|
yes
|
yes
|
|
事件通知
|
no
|
no
|
no
|
yes
|
|
需要安装
|
no
|
yes
|
yes
|
no
|
|
支持的hadoop版本
|
0.18+
|
0.20+
|
currently unknown
|
0.18+
|
|
重试支持
|
no
|
workflownode evel
|
yes
|
yes
|
|
运行任意命令
|
yes
|
yes
|
yes
|
yes
|
|
Amazon EMR支持
|
yes
|
no
|
currently unknown
|
yes
|
其中比较常用的为Azkaban和Oozie。
Azkaban功能特点
1 Web用户界面
2 方便上传工作流
3 方便设置任务之间的关系
4 调度工作流
5 认证/授权(权限的工作)
6 能够杀死并重新启动工作流
7 模块化和可插拔的插件机制
8 项目工作区
9 工作流和任务的日志记录和审计
二、Azkaban使用
Azkaban有web界面,输入[https://localhost:8443](https://localhost:8443/) (注意是https)可以访问Azkaban的用户界面。如图:
[图片上传失败...(image-b8de71-1535698211232)]
首页有四个菜单
- projects:最重要的部分,创建一个工程,所有flows将在工程中运行。
- scheduling:显示定时任务
- executing:显示当前运行的任务
- history:显示历史运行任务
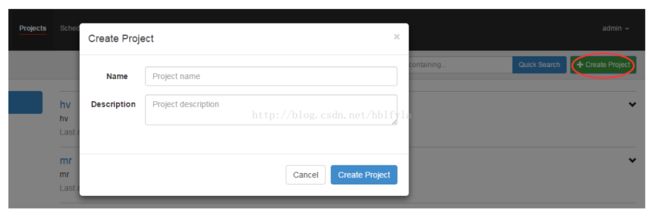
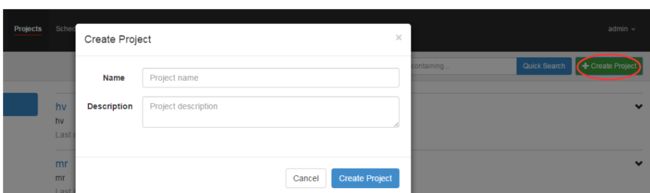
2.1 创建工程
一个工程包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是简单的linux命令,可是java程序,也可以是复杂的shell脚本,当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。点击右上角的create project,在弹出的窗口中填写工程名和描述即可创建工程。
2.2 创建job
创建job很简单,只要创建一个以.job结尾的文本文件就行了。比如:
# foo.jobtype=commandcommand=echo foo
如果是多个job并且有依赖关系,可以使用dependencies参数指定依赖关系。如:
# bar.jobtype=commanddependencies=foocommand=echo bar
这样job就创建好了。
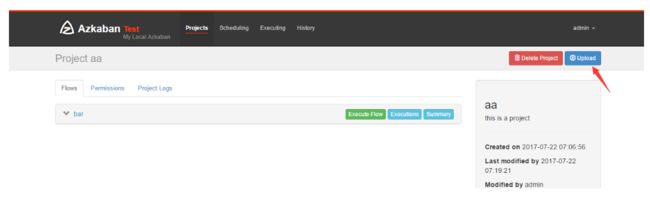
2.3 将工作流打包上传
将上面两个job打成zip包,在页面上点击update上传。上传之后如图:
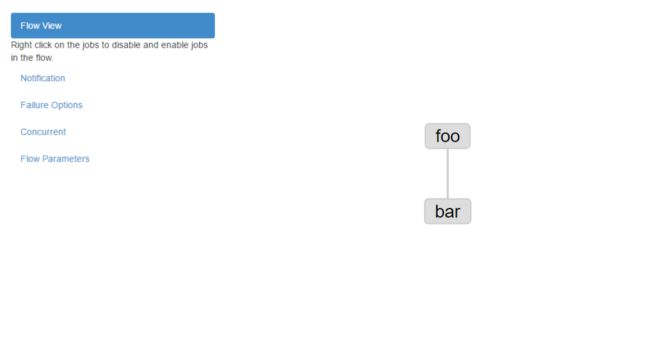
2.4 运行
之后点击绿色的Execute Flow,弹出窗口:
左边的选项卡依次为:
Flow view:流程视图。可以禁用,启用某些job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个job失败,剩下的job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置。
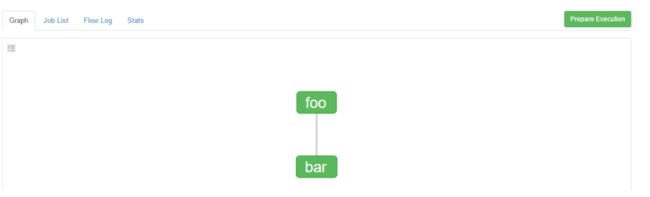
左下角的Schedule是设置调度时间,右下角的Execute为直接运行,点击Execute。运行之后在Graph可以看到:
在job List中可以看到个job运行的起始终止时间。
这样工作流的调度就执行完了,Azkaban的使用还是挺简单的吧。
Azkaban安装部署
Azkaban安装
1、准备工作
Azkaban Web服务器
azkaban-web-server-2.5.0.tar.gz
Azkaban执行服务器
azkaban-executor-server-2.5.0.tar.gz
MySQL
目前azkaban只支持 mysql,需安装mysql服务器,本文档中默认已安装好mysql服务器,并建立了 root用户,密码 root.
azkaban下载地址:http://azkaban.github.io/downloads.html
2、安装
将安装文件上传到集群,最好上传到安装 hive、sqoop的机器上,方便命令的执行
在合适的位置新建azkaban目录,用于存放azkaban运行程序
azkaban web服务器安装
解压azkaban-web-server-2.5.0.tar.gz
命令: tar –zxvf azkaban-web-server-2.5.0.tar.gz
将解压后的azkaban-web-server-2.5.0 移动到 azkaban目录中,并重新命名 webserver
命令: mv azkaban-web-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-web-server-2.5.0 server
azkaban 执行服器安装
解压azkaban-executor-server-2.5.0.tar.gz
命令:tar –zxvf azkaban-executor-server-2.5.0.tar.gz
将解压后的azkaban-executor-server-2.5.0 移动到 azkaban目录中,并重新命名 executor
命令:mv azkaban-executor-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-executor-server-2.5.0 executor
azkaban数据库脚本导入
解压: azkaban-sql-script-2.5.0.tar.gz
命令:tar –zxvf azkaban-sql-script-2.5.0.tar.gz
将解压后的mysql 脚本,导入到mysql中:
进入mysql
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source /home/hadoop/azkaban-2.5.0/create-all-sql-2.5.0.sql;
创建SSL配置
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor的密码及相应信息,输入的密码请劳记,信息如下:
输入keystore密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore 考贝到 azkaban web服务器根目录中的bin目录下.如:cp keystore azkaban/webserver/bin
配置文件
注:先配置好服务器节点上的时区
1、先生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 即可
2、拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3.配置文件的修改
azkaban web服务器配置
进入azkaban web服务器安装目录 conf目录
修改azkaban.properties文件
命令vi azkaban.properties
内容说明如下:
#Azkaban Personalization Settings
azkaban.name=Test #服务器UI名称,用于服务器上方显示的名字
azkaban.label=My Local Azkaban #描述
azkaban.color=#FF3601 #UI颜色
azkaban.default.servlet.path=/index #
web.resource.dir=web/ #默认根web目录
default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类
user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文
#Loader for projects
executor.global.properties=conf/global.properties # global配置文件所在位置
azkaban.project.dir=projects #
database.type=mysql #数据库类型
mysql.port=3306 #端口号
mysql.host=hadoop03 #数据库连接IP
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=root #数据库密码
mysql.numconnections=100 #最大连接数
# Velocity dev mode
velocity.dev.mode=false
# Jetty服务器属性.
jetty.maxThreads=25 #最大线程数
jetty.ssl.port=8443 #Jetty SSL端口
jetty.port=8081 #Jetty端口
jetty.keystore=keystore #SSL文件名
jetty.password=123456 #SSL文件密码
jetty.keypassword=123456 #Jetty主密码 与 keystore文件相同
jetty.truststore=keystore #SSL文件名
jetty.trustpassword=123456 # SSL文件密码
# 执行服务器属性
executor.port=12321 #执行服务器端口
# 邮件设置
[email protected] #发送邮箱
mail.host=smtp.163.com #发送邮箱smtp地址
mail.user=xxxxxxxx #发送邮件时显示的名称
mail.password=********** #邮箱密码
[email protected] #任务失败时发送邮件的地址
[email protected] #任务成功时发送邮件的地址
lockdown.create.projects=false #
cache.directory=cache #缓存目录
azkaban 执行服务器配置
进入执行服务器安装目录conf,修改azkaban.properties
vi azkaban.properties
#Azkaban
default.timezone.id=Asia/Shanghai #时区
# Azkaban JobTypes 插件配置
azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置
#Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
#数据库设置
database.type=mysql #数据库类型(目前只支持mysql)
mysql.port=3306 #数据库端口号
mysql.host=192.168.20.200 #数据库IP地址
mysql.database=azkaban #数据库实例名
mysql.user=azkaban #数据库用户名
mysql.password=oracle #数据库密码
mysql.numconnections=100 #最大连接数
# 执行服务器配置
executor.maxThreads=50 #最大线程数
executor.port=12321 #端口号(如修改,请与web服务中一致)
executor.flow.threads=30 #线程数
用户配置
进入azkaban web服务器conf目录,修改azkaban-users.xml
vi azkaban-users.xml 增加 管理员用户
#添加下面这行
4、启动
web服务器
在azkaban web服务器目录下执行启动命令
bin/azkaban-web-start.sh
注:在web服务器根目录运行
执行服务器
在执行服务器目录下执行启动命令
bin/azkaban-executor-start.sh ./
注:只能要执行服务器根目录运行
启动完成后,在浏览器(建议使用谷歌浏览器)中输入https://服务器IP地址:8443 ,即可访问azkaban服务了.在登录中输入刚才新的户用名及密码,点击 login.
启动可能出现的问题:
启动azkaban时出现User xml file conf/azkaban-users.xml doesn’t exist问题或登录页没有样式:修改配置文件里面的内容为绝对路径;
启动azkaban时报错mysql无法连接,但配置文件都填的无误:mysql没有开放外网访问权限。
使用实例
一、command类型单一job
1 创建job描述文件
#command.job
type=command
command=echo 'hello'
2 将job打包成zip文件
zip command.job
3 通过azkaban网页创建project并将job压缩包上传
4 启动job
二、command类型多job工作流flow
1 创建有依赖关系的多个job描述
第一个job
#foo.job
type=command
command=echo foo
第二个job:bar.job依赖foo.job
type=command
dependencies=foo
command=echo bar
2 将所有的job资源文件打包到一个zip文件中
3 在azkaban的web管理界面创建工程并上传zip包
4 启动工作流flow
三、HDFS操作任务
1 创建job描述文件
# fs.job
type=command
command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop fs -mkdir /azaz
2 将job资源文件打包成zip文件
3、通过azkaban的web管理平台创建project并上传job压缩包
4、启动执行该job
四、MAPREDUCE任务
Mr任务依然可以使用command的job类型来执行
1 创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
# mrwc.job
type=command
command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout
2 将所有job资源文件打到一个zip包中
3 在azkaban的web管理界面创建工程并上传zip包
4 启动job
五、HIVE脚本任务
1 创建job描述文件和hive脚本
Hive脚本: test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
Job描述文件:hivef.job
# hivef.job
type=command
command=/home/hadoop/apps/hive/bin/hive -f 'test.sql'
2 将所有job资源文件打到一个zip包中
3 在azkaban的web管理界面创建工程并上传zip包
4 启动job
Azkaban应用
一、业务场景
在广告追踪系统中,我们通过提供SDK给用户,把各种各样的用户数据采集到我们的服务器中,然后通过MR计算,统计各种输出。在本文中,笔者将抽取其中一种业务场景:计算用户留存和付费LTV。
为了计算以上两个指标,需要采集三类数据:账户的激活、在线、付费记录。其中用户留存和付费LTV的计算过程如下:
1、用户留存:把用户今天在线的数据,与一个月内的用户激活数据做对比,找出今天在线的用户,是在那天激活的,并计算出差别的天数,这就是用户留存的计算方法。
2、付费LTV:找出今天哪些用户付费了,把这些用户,与一个月内的用户激活数据做对比,找出今天付费的用户,是在那天激活的,并计算出差别的天数,然后把今天付费的总额,除以差别的天数,得出付费LTV。
出于对公司数据安全考虑,这里不会贴出任何数据和计算代码,只会把与Azkaban相关的job信息和思路写出来,读者可以作为参考。
二、处理思路
1、原始的用户数据是混合在一起的,都放在按天分区的hdfs的指定目录下,这样,我们就需要写一个作为数据清洗的MR类,把原始日志中的在线,激活,付费三类数据分别输出到独立的文件中。这在hadoopMR中可以通过输出文件后缀的方式进行区分。
2、完成第一步后,我们需要把三类数据分别进行统计,比如按照appid进行统计,币别需要转换,激活时间需要从时间戳转换为日期等步骤。
3、第三步就需要把这三类数据分别入库到hive中,供后面的hiveSQL进行join操作。
4、把在线数据与激活数据做join,得出用户留存;把付费数据与激活数据做join,得出付费LTV。这两类数据计算完成后,需要入库到新的表中。
5、最后在kylin中进行计算,用户就可以在kylin中查询统计结果了。
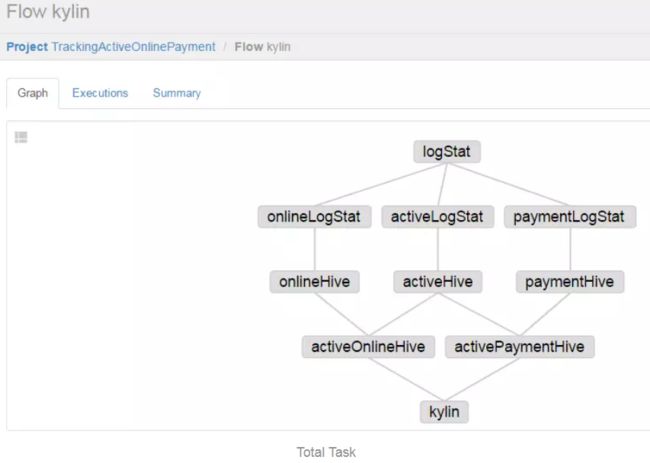
总的数据处理流程如下:
三、具体job编写
1、logStat.job:数据拆分
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
tmpjars=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/ad-tracker-mr2-1.0.0-SNAPSHOT-jar-with-dependencies.jar
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD-1}/*/input/self-event*
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat
calculate.date=all
job.class=com.dataeye.tracker.mr.mapred.actionpay.LogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.LogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.LogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=com.dataeye.tracker.mr.common.SuffixMultipleOutputFormat
2、onlineLogStat.job:在线数据清洗
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat/*TRACING_ACTIVE_LOG_ONLINE
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtOnlineLogStat
calculate.date=${DD:YYYY}-${DD:MM}-${DD:DD}
job.class=com.dataeye.tracker.mr.mapred.actionpay.OnlineLogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.OnlineLogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.OnlineLogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=org.apache.hadoop.io.Text
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
dependencies=logStat
3、activeLogStat.job:激活数据清洗
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat/*TRACING_ACTIVE_LOG_ACTIVE,/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD-1}/00/adtActiveLogStat
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtActiveLogStat
calculate.date=${DD:YYYY}-${DD:MM}-${DD:DD}
job.class=com.dataeye.tracker.mr.mapred.actionpay.ActiveLogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.ActiveLogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.ActiveLogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=org.apache.hadoop.io.Text
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
dependencies=logStat
4、paymentLogStat.job:付费数据清洗
type=hadoopJava
job.extend=true
force.output.overwrite=true
mapred.mapper.new-api=true
mapred.reducer.new-api=true
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
input.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/TrackingLogStat/*TRACING_ACTIVE_LOG_PAYMENT
output.path=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtPaymentLogStat
calculate.date=${DD:YYYY}-${DD:MM}-${DD:DD}
job.class=com.dataeye.tracker.mr.mapred.actionpay.PaymentLogStatMapper
mapreduce.map.class=com.dataeye.tracker.mr.mapred.actionpay.PaymentLogStatMapper
mapreduce.reduce.class=com.dataeye.tracker.mr.mapred.actionpay.PaymentLogStatReducer
mapred.mapoutput.key.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.mapoutput.value.class=com.dataeye.tracker.mr.common.OutFieldsBaseModel
mapred.output.key.class=org.apache.hadoop.io.Text
mapred.output.value.class=org.apache.hadoop.io.NullWritable
mapreduce.inputformat.class=org.apache.hadoop.mapreduce.lib.input.TextInputFormat
mapreduce.outputformat.class=org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
dependencies=logStat
5、onlineHive.job:在线数据入库
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_online.sql
dataPath=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtOnlineLogStat
day_p=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=onlineLogStat
hive_online.sql:
use azkaban;
load data inpath '${dataPath}' overwrite into table adt_logstat_online PARTITION(day_p='${day_p}');
6、activeHive.job:激活数据入库
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_active.sql
dataPath=hdfs://de-hdfs/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtActiveLogStat
day_p=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=activeLogStat
hive_active.sql
use azkaban;
alter table adt_logstat_active_ext set location '${dataPath}';
INSERT overwrite TABLE adt_logstat_active PARTITION (day_p='${day_p}') SELECT appid,channel,compaign,publisher,site,country,province,city,deviceId,activeDate FROM adt_logstat_active_ext;
7、paymentHive.job:付费数据入库
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_payment.sql
dataPath=/user/tracking/event_logserver/${DD:YYYY}/${DD:MM}/${DD:DD}/00/adtPaymentLogStat
day_p=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=paymentLogStat
hive_payment.sql
use azkaban;
load data inpath '${dataPath}' overwrite into table adt_logstat_payment PARTITION(day_p='${day_p}');
8、activeOnlineHive.job:用户留存统计
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_active_online.sql
now_day=${DD:YYYY}-${DD:MM}-${DD:DD-1}
bef_day=${DD:YYYY}-${DD:MM}-${DD:DD-3}
dependencies=activeHive,onlineHive
hive_active_online.sql
use azkaban;
INSERT overwrite TABLE user_retain_roll PARTITION (day_p='${now_day}') SELECT av.appid as appid, ol.channel as channel,ol.compaign as compaign,ol.publisher as publisher,ol.site as site, count(av.deviceId) AS total FROM adt_logstat_online AS ol INNER JOIN adt_logstat_active AS av ON ol.deviceId = av.deviceId and ol.appid = av.appid WHERE ol.day_p = '${now_day}' AND av.activeDate BETWEEN '${bef_day}' AND '${now_day}' GROUP BY av.appid, ol.channel,ol.compaign,ol.publisher,ol.site,av.activeDate;
9、activePaymentHive.job:付费LTV统计
type=hive
user.to.proxy=azkaban
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
azk.hive.action=execute.query
hive.script = res/hive_active_payment.sql
now_day=${DD:YYYY}-${DD:MM}-${DD:DD-1}
bef_day=${DD:YYYY}-${DD:MM}-${DD:DD-3}
dependencies=activeHive,paymentHive
hive_active_payment.sql
use azkaban;
INSERT overwrite TABLE user_retain_ltv PARTITION (day_p='${now_day}') select av.appid as appid, py.channel as channel,py.compaign as compaign,py.publisher as publisher,py.site as site, py.deviceId as deviceId, py.paymentCount AS payment from adt_logstat_payment as py inner join adt_logstat_active as av on av.deviceId = py.deviceId and av.appid = py.appid where py.day_p = '${now_day}' and av.day_p = '${now_day}';
10、kylin.job:kylin计算
type=hadoopJava
job.extend=false
job.class=com.dataeye.kylin.azkaban.JavaMain
classpath=./lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/lib/*,/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/extlib/*
jvm.args=-Dlog4j.log.dir=/home/hadoop2/azkaban/azkaban-solo-server-3.0.0/logs
kylin.url=http://mysql8:7070/kylin/api
cube.name=user_retain_roll_cube,user_retain_ltv_cube
cube.date=${DD:YYYY}-${DD:MM}-${DD:DD-1}
dependencies=activeOnlineHive,activePaymentHive
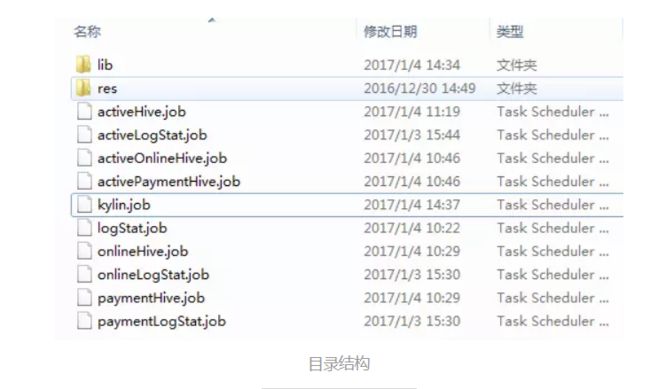
四、打包运行
打包过程与之前一致,最终的目录结构如下:
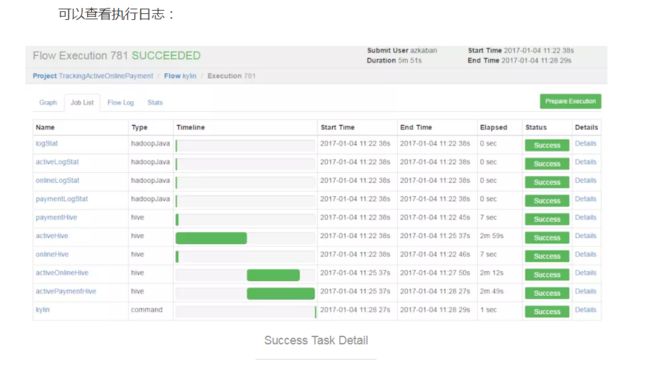
运行结果如下:
可以查看执行日志:
Flume介绍
一、Flume简介
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。
但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.9.4. 中,日
志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以
及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
备注:Flume参考资料
官方网站: http://flume.apache.org/
用户文档: http://flume.apache.org/FlumeUserGuide.html
开发文档: http://flume.apache.org/FlumeDeveloperGuide.html
Flume安装
Flume安装
系统要求:
需安装JDK 1.7及以上版本
1、 下载二进制包
下载页面:http://flume.apache.org/download.html
1.7.0下载地址:http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
2、解压
$ cp ~/Downloads/apache-flume-1.7.0-bin.tar.gz ~
$ cd
$ tar -zxvf apache-flume-1.7.0-bin.tar.gz
$ cd apache-flume-1.7.0-bin
3、创建flume-env.sh文件
$ cp conf/flume-env.sh.template conf/flume-env.sh
Flume内部原理
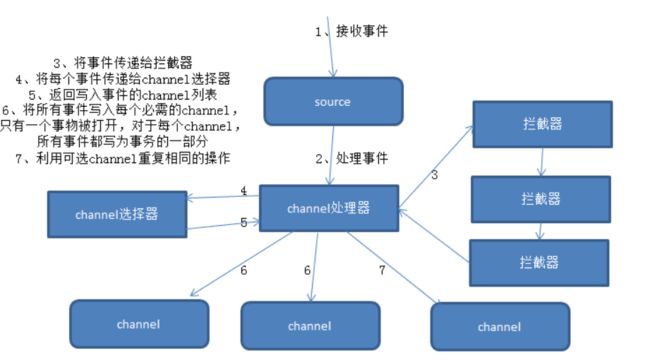
每个flume agent包含三个主要组件:source、channel、sink。
source是从一些其他产生数据的应用中接收数据的活跃组件,有自己产生数据的source,不过这些source通常用于测试目的,source可以监听一个或者多个网络端口,用于接收数据或者可以从本地文件系统读取数据,每个source必须至少连接一个channel,基于一些标准,一个source可以写入几个channel,复制事件到所有或某些channel。
一般来说,channel是被动组件(虽然它们可以为了清理或者垃圾回收运行自己的线程),缓冲agent已经接收,但尚未写出到另一个agent或者存储系统的数据,channel的行为像队列,source写入到它们,sink从它们中读取,多个source可以安全地写入到相同channel,并且多个sink可以从相同的channel进行读取,可是一个sink只能从一个channel读取,如果多个sink从相同的channel读取,它可以保证只有一个sink将会从channel读取一个指定特定的事件,
sink连续轮询各自的channel来读取和删除事件,sink将事件推送到下一阶段,或者最终目的地。一旦在下一阶段或其目的地中数据是安全的,sink通过事务提交通知channel,可以从channel中删除这些事件。
flume本身不限制agent中source、channel和sink的数量,因此flume source可以接收事件,并可以通过配置将事件复制到多个目的地,这使得source通过channel处理器、拦截器和channel选择器,写入数据到channel成为可能
每个source都有自己的channel处理器,每次source将数据写入channel,它是通过委派该任务到其channel处理器来完成的,然后,channel处理器将这些事件传到一个或多个source配置的拦截器中,
拦截器是一段代码,可以基于某些它完成的处理来读取事件和修改或删除事件,基于某些标准,如正则表达式,拦截器可以用来删除事件,为事件添加新报头或移除现有的报头等,每个source可以配置成使用多个拦截器,按照配置中定义的顺序被调用,将拦截器的结果传递给链的下一个单元,这就是所谓的责任链的设计模式,一旦拦截器处理完事件,拦截器链返回的事件列表传递到channel列表,即通过channel选择器为每个事件选择channel。
source可以通过处理器-拦截器-选择器路由写入多个channel,channel选择器的决定每个事件必须写入到source附带的哪个channel的组件。因此拦截器可以用来插入或删除事件中的数据,这样channel选择器可以应用一些条件在这些事件上,来决定事件必须写入哪些channel,channel选择器可以对事件应用任意过滤条件,来决定每个事件必须写入哪些channel,以及哪些channel是必须的或可选的。
写入到必需的channel失败将会导致channel处理器抛出channelexception,表明source必须重新重试该事件,而未能写入可选channel失败仅仅忽略它,一旦写出事件,处理器会对source指示成功状态,可能发送确认给发送该事件的系统,并继续接受更多的事件。
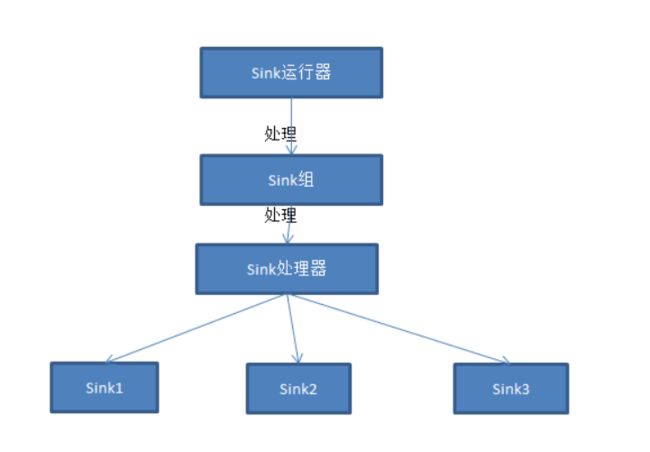
sink运行器运行一个sink组,sink组可含有一个或多个sink,如果组中只存在一个sink,那么没有组将更有效率,sink运行器仅仅是一个询问sink组来处理下一批事件的线程,每个sink组有一个sink处理器,处理器选择组中的sink之一去处理下一个事件集合,每个sink只能从一个channel获取数据,尽管多个sink可以从同一个channel获取数据,选定的sink从channel中接收事件,并将事件写入到下一阶段或最终目的地。
Source、Channel、Sink
Source、Channel、Sink有哪些类型
Flume Source
Source类型 | 说明
Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持
Thrift Source | 支持Thrift协议,内置支持
Exec Source | 基于Unix的command在标准输出上生产数据
JMS Source | 从JMS系统(消息、主题)中读取数据
Spooling Directory Source | 监控指定目录内数据变更
Twitter 1% firehose Source| 通过API持续下载Twitter数据,试验性质
Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入
Sequence Generator Source | 序列生成器数据源,生产序列数据
Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议
HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式
Legacy Sources | 兼容老的Flume OG中Source(0.9.x版本)
Flume Channel
Channel类型 说明
Memory Channel | Event数据存储在内存中
JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby
File Channel | Event数据存储在磁盘文件中
Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件
Pseudo Transaction Channel | 测试用途
Custom Channel | 自定义Channel实现
Flume Sink
Sink类型 说明
HDFS Sink | 数据写入HDFS
Logger Sink | 数据写入日志文件
Avro Sink | 数据被转换成Avro Event,然后发送到配置的RPC端口上
Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上
IRC Sink | 数据在IRC上进行回放
File Roll Sink | 存储数据到本地文件系统
Null Sink | 丢弃到所有数据
HBase Sink | 数据写入HBase数据库
Morphline Solr Sink | 数据发送到Solr搜索服务器(集群)
ElasticSearch Sink | 数据发送到Elastic Search搜索服务器(集群)
Kite Dataset Sink | 写数据到Kite Dataset,试验性质的
Custom Sink | 自定义Sink实现
Flume应用案例
案例1、 A simple example
http://flume.apache.org/FlumeUserGuide.html#a-simple-example
配置文件
############################################################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
############################################################
启动flume
flume-ng agent -n a1 -c conf -f simple.conf -Dflume.root.logger=INFO,console 指定配置目录
flume-ng agent -n a1 -f op5 -Dflume.root.logger=INFO,console 不用指定配置目录,将上诉source,channel,sink的文件起名为a1,同时指定这个文件在哪
安装telnet
yum install telnet
退出 ctrl+] quit
Memory Chanel 配置
capacity:默认该通道中最大的可以存储的event数量是100,
trasactionCapacity:每次最大可以source中拿到或者送到sink中的event数量也是100
keep-alive:event添加到通道中或者移出的允许时间
byte**:即event的字节量的限制,只包括eventbody
案例2、两个flume做集群(第一个agent的sink作为第二个agent的source)
node01服务器中,配置文件
############################################################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = node1
a1.sources.r1.port = 44444
# Describe the sink
# a1.sinks.k1.type = logger
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node2
a1.sinks.k1.port = 60000
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
############################################################
node02服务器中,安装Flume(步骤略)
配置文件
############################################################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = node2
a1.sources.r1.port = 60000
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
############################################################
先启动node02的Flume
flume-ng agent -n a1 -c conf -f avro.conf -Dflume.root.logger=INFO,console
再启动node01的Flume
flume-ng agent -n a1 -c conf -f simple.conf2 -Dflume.root.logger=INFO,console
打开telnet 测试 node02控制台输出结果
案例3、Exec Source(监听一个文件)
http://flume.apache.org/FlumeUserGuide.html#exec-source
配置文件
############################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/flume.exec.log
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
############################################################
启动Flume
flume-ng agent -n a1 -c conf -f exec.conf -Dflume.root.logger=INFO,console
创建空文件演示 touch flume.exec.log
循环添加数据
for i in {1..50}; do echo "$i hi flume" >> flume.exec.log ; sleep 0.1; done
案例4、Spooling Directory Source(监听一个目录)
http://flume.apache.org/FlumeUserGuide.html#spooling-directory-source
配置文件
############################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/logs
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
############################################################
启动Flume
flume-ng agent -n a1 -c conf -f spool.conf -Dflume.root.logger=INFO,console
拷贝文件演示
mkdir logs
cp flume.exec.log logs/
案例5、hdfs sink
http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
配置文件
############################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/logs
a1.sources.r1.fileHeader = true
# Describe the sink
***只修改上一个spool sink的配置代码块 a1.sinks.k1.type = logger
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://sxt/flume/%Y-%m-%d/%H%M
##每隔60s或者文件大小超过10M的时候产生新文件
# hdfs有多少条消息时新建文件,0不基于消息个数
a1.sinks.k1.hdfs.rollCount=0
# hdfs创建多长时间新建文件,0不基于时间
a1.sinks.k1.hdfs.rollInterval=60
# hdfs多大时新建文件,0不基于文件大小
a1.sinks.k1.hdfs.rollSize=10240
# 当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重命名成目标文件
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
时间参数一定要带上 true
a1.sinks.k1.hdfs.useLocalTimeStamp=true
## 每五分钟生成一个目录:
# 是否启用时间上的”舍弃”,这里的”舍弃”,类似于”四舍五入”,后面再介绍。如果启用,则会影响除了%t的其他所有时间表达式
a1.sinks.k1.hdfs.round=true
# 时间上进行“舍弃”的值;
a1.sinks.k1.hdfs.roundValue=5
# 时间上进行”舍弃”的单位,包含:second,minute,hour
a1.sinks.k1.hdfs.roundUnit=minute
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1(将source,channel,sink关联)
############################################################
创建HDFS目录
hadoop fs -mkdir /flume
启动Flume
flume-ng agent -n a1 -c conf -f hdfs.conf -Dflume.root.logger=INFO,console
查看hdfs文件
hadoop fs -ls /flume/...
hadoop fs -get /flume/...