
上次给大家分享了《2017年最全的excel函数大全13—兼容函数(上)》,这次分享给大家兼容性函数(中),如果你使用的是 Excel 2007,则可以在“公式”选项卡上的统计或数学与三角函数类别中找到这些函数。
EXPONDIST 函数
描述
返回指数分布。 使用 EXPONDIST 可以建立事件之间的时间间隔模型,如银行自动提款机支付一次现金所花费的时间。 例如,可通过 EXPONDIST 来确定这一过程最长持续一分钟的发生概率。
有关新函数的详细信息,请参考EXPON.DIST 函数。
用法
EXPONDIST(x,lambda,cumulative)
EXPONDIST 函数用法具有下列参数:
X必需。 函数值。
Lambda必需。 参数值。
Cumulative必需。 逻辑值,用于指定指数函数的形式。 如果 cumulative 为 TRUE,则 EXPONDIST 返回累积分布函数;如果为 FALSE,则返回概率密度函数。
其他
如果 x 或 lambda 为非数值型,则 EXPONDIST 返回 错误值 #VALUE!。
如果 x < 0,则 EXPONDIST 返回 错误值 #NUM!。
如果 lambda ≤ 0,则 EXPONDIST 返回 错误值 #NUM!。
概率密度函数的公式为:
累积分布函数的公式为:
案例

FDIST 函数
描述
返回两个数据集的(右尾)F 概率分布(变化程度)。 使用此函数可以确定两组数据是否存在变化程度上的不同。 例如,分析进入中学的男生、女生的考试分数,来确定女生分数的变化程度是否与男生不同。
有关新函数的详细信息,请参考F.DIST 函数和F.DIST.RT 函数。
用法
FDIST(x,deg_freedom1,deg_freedom2)
FDIST 函数用法具有下列参数:
X必需。 用来计算函数的值。
Deg_freedom1必需。 分子自由度。
Deg_freedom2必需。 分母自由度。
其他
如果任一参数为非数值型,则 FDIST 返回 错误值 #VALUE!。
如果 x 为负数,则 FDIST 返回 错误值 #NUM!。
如果 deg_freedom1 或 deg_freedom2 不是整数,则将被截尾取整。
如果 deg_freedom1 < 1 或 deg_freedom1 ≥ 10^10,则 FDIST 返回 错误值 #NUM!。
如果 deg_freedom2 < 1 或 deg_freedom2 ≥ 10^10,则 FDIST 返回 错误值 #NUM!。
FDIST 的计算公式为 FDIST=P( F>x ),其中 F 为呈 F 分布且带有 deg_freedom1 和 deg_freedom2 自由度的随机变量。
案例
FINV 函数

描述
返回(右尾)F 概率分布函数的反函数值。 如果 p = FDIST(x,...),则 FINV(p,...) = x。
在 F 检验中,可以使用 F 分布比较两组数据中的变化程度。 例如,可以分析美国和加拿大的收入分布,判断两个国家/地区是否有相似的收入变化程度。
有关新函数的详细信息,请参考F.INV 函数和F.INV.RT 函数。
用法
FINV(probability,deg_freedom1,deg_freedom2)
FINV 函数用法具有下列参数:
Probability必需。 F 累积分布的概率值。
Deg_freedom1必需。 分子自由度。
Deg_freedom2必需。 分母自由度。
其他
如果任一参数为非数值型,则 FINV 返回 错误值 #VALUE!。
如果 probability < 0 或 probability > 1,则 FINV 返回 错误值 #NUM!。
如果 deg_freedom1 或 deg_freedom2 不是整数,则将被截尾取整。
如果 deg_freedom1 < 1 或 deg_freedom1 ≥ 10^10,则 FINV 返回 错误值 #NUM!。
如果 deg_freedom2 < 1 或 deg_freedom2 ≥ 10^10,则 FINV 返回 错误值 #NUM!。
FINV 可用于返回 F 分布的临界值。 例如,ANOVA 计算的结果常常包括 F 统计值、F 概率和显著水平参数为 0.05 的 F 临界值数据。 若要返回 F 的临界值,请将显著水平参数用作为 FINV 的 probability 参数。
如果已给定概率值,则 FINV 使用 FDIST(x, deg_freedom1, deg_freedom2) = probability 求解数值 x。 因此,FINV 的精度取决于 FDIST 的精度。 FINV 使用迭代搜索技术。 如果搜索在 100 次迭代之后没有收敛,则函数返回错误值 #N/A。
案例

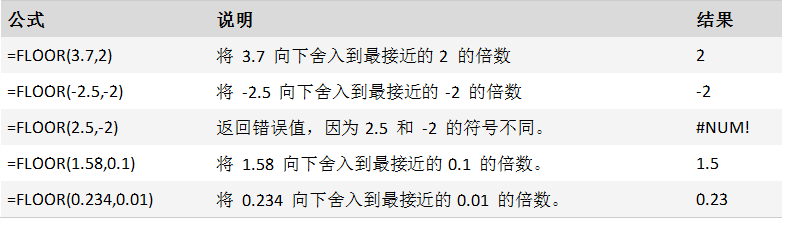
FLOOR 函数
描述
将参数 number 向下舍入(沿绝对值减小的方向)为最接近的 significance 的倍数。
用法
FLOOR(number, significance)
FLOOR 函数用法具有下列参数:
Number必需。 要舍入的数值。
significance必需。 要舍入到的倍数。
备注
如果任一参数为非数值型,则 FLOOR 返回 错误值 #VALUE!。
如果 number 为正值,significance 为负值,则 FLOOR 返回 错误值 #NUM!。
如果 number 的符号为正,则数值向下舍入,并朝零调整。 如果 number 的符号为负,则数值沿绝对值减小的方向向下舍入。 如果 number 正好是 significance 的倍数,则不进行舍入。
案例
FORECAST 函数
描述
根据现有值计算或预测未来值。 预测值为给定 x 值后求得的 y 值。 已知值为现有的 x 值和 y 值,并通过线性回归来预测新值。 可以使用该函数来预测未来销售、库存需求或消费趋势等。
注意: 在 Excel 2016 中,此函数已替换为 FORECAST.LINEAR,成为新预测函数的一部分。它仍然可用于后向兼容,但建议使用 Excel 2016 中的新函数。
用法
FORECAST(x, known_y's, known_x's)
FORECAST 函数用法具有下列参数:
X必需。 需要进行值预测的数据点。
Known_y's必需。 相关数组或数据区域。
Known_x's必需。 独立数组或数据区域。
备注
如果 x 为非数值型,则 FORECAST 返回 错误值 #VALUE!。
如果 known_y's 和 known_x's 为空或含有不同个数的数据点,函数 FORECAST 返回错误值 #N/A。
如果 known_x's 的方差为零,则 FORECAST 返回 错误值 #DIV/0!。
函数 FORECAST 的计算公式为 a+bx,式中:
且:
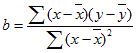
且其中 x 和 y 是样本平均值 AVERAGE(known_x's) 和 AVERAGE(known_y's)。
案例
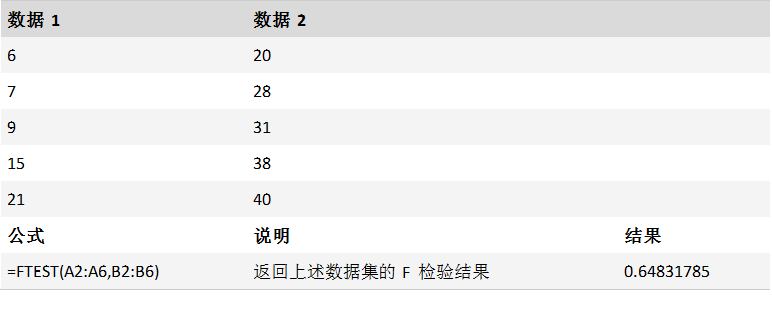
FTEST 函数

描述
返回 F 检验的结果 F 检验返回当 array1 和 array2 的方差无明显差异时的双尾概率。 使用此函数可确定两个案例是否有不同的方差。 例如,给定公立和私立学校的测验分数,可以检验各学校间测验分数的差别程度。
有关新函数的详细信息,请参考F.TEST 函数。
用法
FTEST(array1,array2)
FTEST 函数用法具有下列参数:
Array1必需。 第一个数组或数据区域。
Array2必需。 第二个数组或数据区域。
备注
参数可以是数字,或者是包含数字的名称、数组或引用。
如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。
如果 array1 或 array2 中数据点的个数少于 2 个,或者 array1 或 array2 的方差为零,则 FTEST 返回 错误值 #DIV/0!。
LINEST 函数返回的 F 检验值与 FTEST 函数返回的 F 检验值不同。 LINEST 返回 F 统计值,而 FTEST 返回概率。
案例
GAMMADIST 函数
描述
返回伽玛分布函数的函数值。 可以使用此函数来研究呈斜分布的变量。 伽玛分布通常用于排队分析。
有关新函数的详细信息,请参考GAMMA.DIST 函数。
用法
GAMMADIST(x,alpha,beta,cumulative)
GAMMADIST 函数用法具有下列参数:
X必需。 用来计算分布的数值。
Alpha必需。 分布参数。
Beta必需。 分布参数。 如果 beta = 1,则 GAMMADIST 返回标准伽玛分布。
Cumulative必需。 决定函数形式的逻辑值。 如果 cumulative 为 TRUE,则 GAMMADIST 返回累积分布函数;如果为 FALSE,则返回概率密度函数。
备注
如果 x、alpha 或 beta 为非数值型,则 GAMMADIST 返回 错误值 #VALUE!。
如果 x < 0,则 GAMMADIST 返回 错误值 #NUM!。
如果 alpha ≤ 0 或 beta ≤ 0,则 GAMMADIST 返回 错误值 #NUM!。
伽玛概率密度函数的计算公式如下:
标准伽玛概率密度函数为:
当 alpha = 1 时,GAMMADIST 使用下面的公式返回指数分布:
对于正整数 n,当 alpha = n/2、beta = 2 且 cumulative = TRUE 时,GAMMADIST 返回 (1 - CHIDIST(x)),自由度为 n。
如果 alpha 为正整数,则 GAMMADIST 也称为爱尔朗 (Erlang) 分布。
案例
GAMMAINV 函数

描述
返回伽玛累积分布函数的反函数值。 如果 p = GAMMADIST(x,...),则 GAMMAINV(p,...) = x。 使用此函数可以研究有可能呈斜分布的变量。
有关新函数的详细信息,请参考GAMMA.INV 函数。
用法
GAMMAINV(probability,alpha,beta)
GAMMAINV 函数用法具有下列参数:
Probability必需。 伽玛分布相关的概率。
Alpha必需。 分布参数。
Beta必需。 分布参数。 如果 beta = 1,则 GAMMAINV 返回标准伽玛分布。
备注
如果任一参数为文本型,则 GAMMAINV 返回 错误值 #VALUE!。
如果 probability < 0 或 probability > 1,则 GAMMAINV 返回 错误值 #NUM!。
如果 alpha ≤ 0 或 beta ≤ 0,则 GAMMAINV 返回 错误值 #NUM!。
如果已给定概率值,则 GAMMAINV 使用 GAMMADIST(x, alpha, beta, TRUE) = probability 求解数值 x。 因此,GAMMAINV 的精度取决于 GAMMADIST 的精度。 GAMMAINV 使用迭代搜索技术。 如果搜索在 100 次迭代之后没有收敛,则函数返回错误值 #N/A。
案例
HYPGEOMDIST 函数

描述
返回超几何分布。 如果已知样本量、总体成功次数和总体大小,则 HYPGEOMDIST 返回样本取得已知成功次数的概率。 HYPGEOMDIST 用于处理以下的有限总体问题,在该有限总体中,每次观察结果或为成功或为失败,并且已知样本量的每个子集的选取是等可能的。
有关新函数的详细信息,请参考HYPGEOM.DIST 函数。
用法
HYPGEOMDIST(sample_s,number_sample,population_s,number_pop)
HYPGEOMDIST 函数用法具有下列参数:
Sample_s必需。 样本中成功的次数。
Number_sample必需。 样本量。
Population_s必需。 总体中成功的次数。
Number_pop必需。 总体大小。
备注
所有参数都将被截尾取整。
如果任一参数为非数值型,则 HYPGEOMDIST 返回 错误值 #VALUE。
如果 sample_s < 0 或 sample_s 大于 number_sample 和 population_s 中的较小值,则 HYPGEOMDIST 返回 错误值 #NUM!。
如果 sample_s 小于 0 和 (number_sample - number_population + population_s) 中的较大值,则 HYPGEOMDIST 返回 错误值 #NUM!。
如果 number_sample ≤ 0 或 number_sample > number_population,则 HYPGEOMDIST 返回 错误值 #NUM!。
如果 population_s ≤ 0 或 population_s > number_population,则 HYPGEOMDIST 返回 错误值 #NUM!。
如果 number_population ≤ 0,则 HYPGEOMDIST 返回 错误值 #NUM!。
超几何分布的公式为:

其中:
x = sample_s
n = number_sample
M = population_s
N = number_population
HYPGEOMDIST 用于有限总体中的不放回抽样。
案例

LOGINV 函数
描述
返回 x 的对数累积分布函数的反函数值,此处的 ln(x) 是服从参数 mean 和 standard_dev 的正态分布。 如果 p = LOGNORMDIST(x,...),则 LOGINV(p,...) = x。
使用对数分布可分析经过对数变换的数据。
有关新函数的详细信息,请参考LOGNORM.INV 函数。
用法
LOGINV(probability, mean, standard_dev)
LOGINV 函数用法具有下列参数:
Probability必需。 与对数分布相关的概率。
Mean必需。 ln(x) 的平均值。
standard_dev必需。 ln(x) 的标准偏差。
其他
如果任一参数是非数值的,则 LOGINV 返回 错误值 #VALUE!。
如果 probability <= 0 或 probability >= 1,则 LOGINV 返回 错误值 #NUM!。
如果 standard_dev <= 0,则 LOGINV 返回 错误值 #NUM!。
对数分布函数的反函数为:
案例

LOGNORMDIST 函数
描述
返回 x 的对数累积分布函数的函数值,此处的 ln(x) 是服从参数 mean 和 standard_dev 的正态分布。 使用此函数可以分析经过对数变换的数据。
有关新函数的详细信息,请参考LOGNORM.DIST 函数。
用法
LOGNORMDIST(x,mean,standard_dev)
LOGNORMDIST 函数用法具有下列参数:
X必需。 用来计算函数的值。
Mean必需。 ln(x) 的平均值。
standard_dev必需。 ln(x) 的标准偏差。
备注
如果任一参数为非数值型,则 LOGNORMDIST 返回 错误值 #VALUE!。
如果 x ≤ 0 或 standard_dev ≤ 0,则 LOGNORMDIST 返回 错误值 #NUM!。
对数累积分布函数的公式为:
案例

以上是所有EXCEL的兼容性函数(中)描述用法以及使用案例。这次分享中存在哪些疑问或者哪些不足,可以在下面进行评论。如果觉得不错,可以分享给你的朋友,让大家一起掌握这些excel的兼容性函数(中)。