本文为原创文章,转载请注明出处。
在讲述这BGD、SGD和MBGD几个算法之前,需要先说明一下梯度下降算法中的几个概念:
①epoch:
训练回合,也即完整的前向传播与反向传播的组合,两个过程相继走完。
epoch的次数 = 训练集个数 / batch_size
②iterations:
一次epoch过程中需要完成batch_size个数据样本的前向传播。
③batch_size:
训练集大小N小于2000个,则利用BGD算法更好;
训练集规模很大,则用MBGD算法更好,batch_size的取值通常为64,128,256,512,这与CPU/GPU的数据存储位数有关系。
1.批量梯度下降法(Batch Gradient Descent,BGD)
批量梯度下降,是每个epoch过程中把所有样本数据集都迭代了一遍,
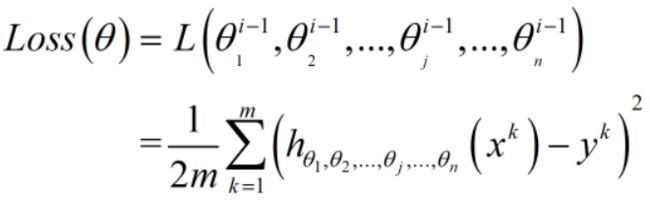
整体表示数据集中m个数据样本的loss求均值,m表示训练集的样本容量,i表示当前样本
一般情况下,输入一个样本输出只会有一个,所有没有再次求累积的情况,但是如果要求中间隐藏层的损失函数则必然有累积,因为隐藏层有很多个。
如果把一个数据集中的所有样本都进行一次epoch,则BGD算法更新一次权重的公式:
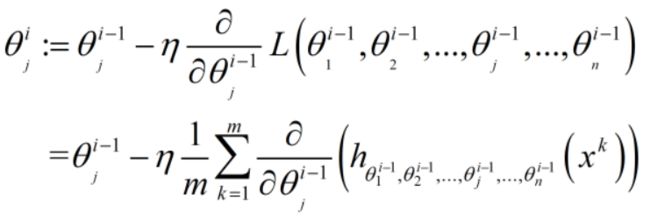
上式,权重j在当前第i轮epoch更新中的值 = (第i-1轮epoch的权重j值) -
(学习率) × (第i-1轮更新的权重在输入的m个样本数据的Loss于权重j的梯度)。
其中,j表示第j个权重,i表示第i个epoch,n表示n个权重,m表示m个样本的数据集,k表示m个样本中的第k个样本
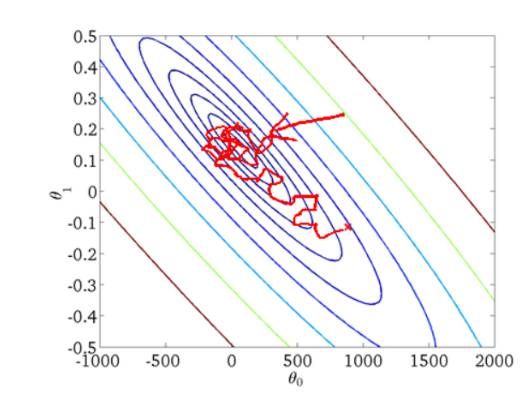
BGD算法的收敛图:

2. 随机梯度下降(Stochastic Gradient Descent, SGD)
随机梯度下降每次的权重更新只利用数据集中的一个样本来完成,也即一个epoch过程只有一次迭代和一个更新数据。
则Loss Function函数公式:
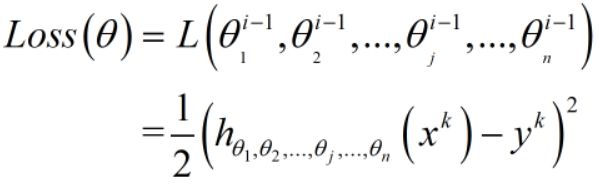
则利用Loss函数来更新权重参数的公式:

随机梯度下降算法在online场景下用的比较多
但是,SGD算法由于每次epoch过程只用一个数据样本,很容易受到单个数据的影响,如果单个样本是离群点或噪声,SGD算法也依然会得到更新,这使得SGD算法的每次更新迭代有可能不朝全局最优解方向走,也可能导致不收敛。
SGD算法的收敛图:
3.小批量梯度下降法(Mini-batch Gradient Descent,MBGD)
小批量梯度下降法在BGD算法和SGD算法之间找了一个trade-off,即加快更新速度,并减少噪声的影响,从而减少训练时间和提高准确率。
特点:每次不选择所有的样本也不只选择一个样本,而是选择l(L的小写)个样本,也即bach_size。
则Loss Function函数公式:
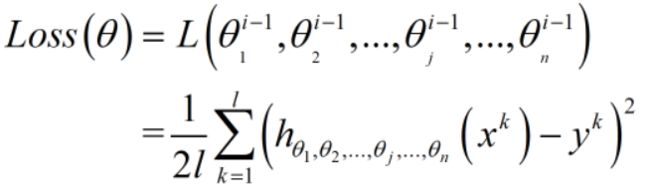
则利用Loss函数来更新权重参数的公式:
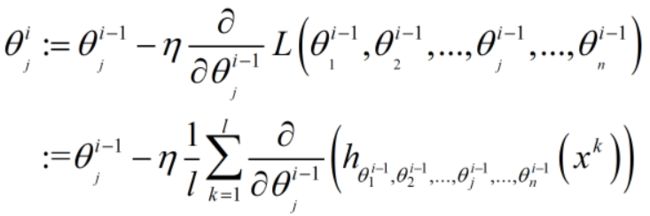
参考文献:
[1] 训练一个神经网络1-- epoch,batch_size,iteration