原文:http://tecdat.cn/?p=3703
RevoScaleR中的rxDTree函数使用基于分类的递归分区算法来拟合基于树的模型得到的模型类似于推荐的ř包rpart包产生的模型支持分类型树和回归型树。; 与rpart包一样,差异由响应变量的性质决定:因子响应生成分类树; 数字响应生成回归树。
rxDTree算法
决策树是广泛用于分类和回归的有效算法。构建决策树通常要求对所有连续变量进行排序,以便决定在何处拆分数据。在处理大数据时,此排序步骤变得时间和内存过高。已经提出了各种技术来克服排序障碍,其可以大致分为两组:执行数据预排序或使用数据的近似概要统计虽然预排序技术更接近标准决策树算法,但它们无法容纳非常大的数据集这些大数据决策树通常以各种方式并行化,以实现大规模学习:
该rxDTree算法是一种具有水平数据并行性的近似决策树算法,专门用于处理非常大的数据集。它使用直方图作为数据的近似紧凑表示,并以广度优先的方式构建决策树。该算法可以在并行设置中执行,例如多核机器或具有主 - 工程体系结构的分布式环境。每个工作者只获得数据观察的一个子集,但可以查看到目前为止构建的完整树。它根据它看到的观察结果构建直方图,它基本上将数据压缩到固定数量的内存。然后将该数据的近似描述发送给具有恒定的低通信复杂度的主设备,而与数据集的大小无关。主设备集成从每个工作人员接收的信息,并确定要拆分的终端树节点以及如何拆分。由于直方图是并行构建的,因此即使对于非常大的数据集也可以快速构建。
使用rxDTree,您可以通过指定直方图的最大二进制数来控制时间复杂度和预测精度之间的平衡。该算法在每个区间中构建具有大致相等数量的观察的直方图,并且将区间的边界作为终端树节点的候选分割。由于仅检查有限数量的分割位置,因此可能选择次优分割点使得整个树与由标准算法构造的树不同。但是,分析表明,并行树的错误率接近串行树的错误率,即使树不相同您可以在直方图中设置箱的数量,以控制准确度和速度之间的权衡:
当仓的数量等于或超过观察数量的整数预测值时,rxDTree算法产生与标准排序算法相同的结果。
一个简单的分类树
在之前的文章中,我们将简单的逻辑回归模型拟合为rpart包的驼背数据使用rxDTree ,如下所示:
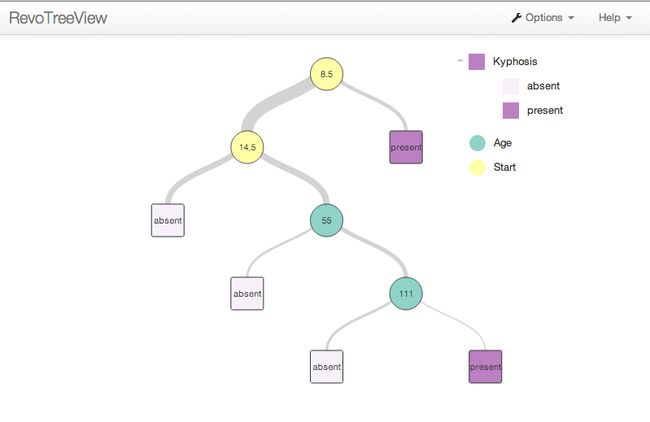
kyphTree rxDTree(公式=脊柱后凸〜年龄+开始+数字,数据=脊柱后凸, cp = 0.01) 数据:脊柱后凸 有效观察数:81 缺失观察数:0 树表示: n = 81 node),split,n,loss,yval,(yprob) *表示终端节点 1)根81 17缺席(0.79012346 0.20987654) 2)开始> = 8.5 62 6缺席(0.90322581 0.09677419) 4)开始> = 14.5 29 0缺席(1.00000000 0.00000000)* 5)开始<14.5 33 6缺席(0.81818182 0.18181818) 10)年龄<55 12 0缺席(1.00000000 0.00000000)* 11)年龄> = 55 21 6缺席(0.71428571 0.28571429) 22)年龄> = 111 14 2缺席(0.85714286 0.14285714)* 23)年龄<111 7 3(0.42857143 0.57142857)* 3)开始<8.5 19 8现在(0.42105263 0.57894737)*
回想一下我们之前用rxCube拟合这个模型的结论:术后并发症的概率如果开始是颈椎并且手术中涉及更多的椎骨,则脊柱后凸似乎更大类似地,似乎对年龄的依赖是非线性的:它首先随着年龄而增加,峰值在5-9范围内,然后再次减小。
rxDTree模型似乎证实了这些早期的结论 - 对于开始<8.5,19名观察对象中的11名发展为脊柱后凸,而29名受试者中没有一名患者开始> = 14.5。对于剩余的33名受试者,年龄是主要的分裂因素,正如我们之前观察到的,5至9岁的患者发生脊柱后凸的概率最高。
返回的对象kyphTree是类rxDTree的对象该rxDTree类是密切仿照rpart包包类,因此该类的对象rxDTree有一个最重要的组成部分rpart包包对象:框架,cptable,拆分等默认情况下,然而, rxDTree对象不从类继承rpart包包。但是,您可以使用rxAddInheritance函数将软件rpart继承添加到rxDTree对象。
一个简单的回归树
作为回归树的一个简单示例,考虑mtcars数据集,并使用置换(DISP)作为预测值来拟合汽油里程(MPG):
#一个简单的回归树 mtcarTree < - rxDTree(mpg~disp,data = mtcars) mtcarTree rxDTree(公式= mpg~disp,data = mtcars) 数据:mtcars 有效观察数:32 缺失观察数:0 树表示: n = 32 node),split,n,deviance,yval *表示终端节点 1)root 32 1126.0470 20.09063 2)disp> = 163.5 18 143.5894 15.99444 * 3)disp <163.5 14 292.1343 25.35714 *
大型汽车(发动机排量大于163.5立方英寸)和小型汽车之间存在明显的区别。
一个更大的回归树模型
作为一个更复杂的例子,我们返回人口普查员工数据我们使用perwt变量作为概率权重,创建一个回归树,根据年龄,性别和工作周数预测工资收入:
#一个更大的回归树模型 maxDepth = 3,minBucket = 30000,data = censusWorkers) incomeTree rxDTree( incwage~年龄+性别+ wkswork1,数据=人口普查工作者, pweights =“perwt”,minBucket = 30000,maxDepth = 3) 文件:C:\ Program Files \ Microsoft \ MRO-for-RRE \ 8.0 \ R-3.2.2 \ library \ RevoScaleR \ SampleData \ CensusWorkers.xdf 有效观察数:351121 缺失观察数:0 树表示: n = 351121 node),split,n,deviance,yval *表示终端节点 1)root 351121 1.177765e + 16 35788.47 2)性别=女161777 2.271425e + 15 26721.09 4)wkswork1 <51.5 56874 5.757587e + 14 19717.74 * 5)wkswork1> = 51.5 104903 1.608813e + 15 30505.87 10)年龄<34.5 31511 2.500078e + 14 25836.32 * 11)年龄> = 34.5 73392 1.338235e + 15 32576.74 * 3)性别=男性189344 9.008506e + 15 43472.71 6)年龄<31.5 48449 6.445334e + 14 27577.80 * 7)年龄> = 31.5 140895 8.010642e + 15 49221.82 14)wkswork1 <51.5 34359 1.550839e + 15 37096.62 * 15)wkswork1> = 51.5 106536 6.326896e + 15 53082.08 *
这里的主要分裂(鉴于我们对教程中的数据集的分析:用RevoScaleR分析美国人口普查数据,这并不奇怪)是性别; 女性平均收入大大低于男性额外的分裂也不足为奇。老年工人的收入高于年轻工人,而那些工作时间更长的人往往比那些工作时间更少的人赚得更多。
模型拟合
该rxDTree功能有许多用于控制模型的拟合选项.rpart用户熟悉这些控制参数中的大多数,但在某些情况下已修改默认值以更好地支持大型数据树模型。可以在rxDTree帮助文件中找到这些选项的完整列表,但在我们的测试中发现以下内容对于控制使用rxDTree拟合模型所需的时间最有用:
- XVAL:控制用于执行交叉验证的折叠数默认值为2允许进行一些修剪; 一旦你在模型中关闭,你可能想要增加最终拟合和修剪的值。
- MAXDEPTH:设置树的任何节点的最大深度随着深度的增加,计算量变得越来越快,因此我们建议MAXDEPTH为10到15。
- maxCompete:指定输出中保留的“竞争对手拆分”的数量默认情况下,rxDTree将此值设置为0,但设置为3或4可用于诊断目的,以确定选择特定拆分的原因。
- maxSurrogate:指定输出中保留的代理拆分数同样,默认情况下,rxDTree将此值设置为0。当该观察值缺少主要分割变量时,使用代理分割来分配观察值。
- maxNumBins:。控制每个变量使用的最大纸槽数管理仓的数量对于控制内存使用非常重要默认情况下,对于小到中等大小的数据集(最多约一百万个观测值),使用较大的101和观测数量的平方根,但对于较大的集合,使用1001个箱。对于具有连续预测变量的小数据集,您可能会发现需要增加maxNumBins以获得类似于rpart包的模型。
对于大型数据集(100000或更多观测值),您可能需要调整以下参数以获得有意义的模型:
- CP:。复杂性参数,并设置拆分在被接受之前必须降低复杂程度的标准我们将默认值设置为0,并建议使用MAXDEPTH和minBucket来控制树的大小如果要指定CP值,请从保守值开始,例如rpart包的0.01; 如果你没有看到足够数量的分裂,那么将cp减去10的幂,直到你这样做为止。对于我们的大型航空公司数据,我们发现有趣的模型以大约1e-4的cp开头。
- minSplit,minBucket:确定在尝试拆分之前节点中必须有多少观察值(minSplit)以及终端节点中必须保留多少观察值(minBucket)。
大数据树模型
使用rxDTree可以将决策树扩展为非常大的数据集,但应谨慎使用 - 错误选择模型参数很容易导致需要数小时或更长时间才能算算的模型,即使在分布式计算环境中也是如此。例如,在教程:使用RevoScaleR加载和分析大型航空公司数据集时,我们使用大型航空公司数据估算线性模型,并使用变量产地作为多个模型中的预测变量该产地变量是373级的水平,没有明显排序的因素变量将此变量合并到rxDTree中执行两级以上分类的模型很容易消耗数小时的计算时间为了防止这种意外后果,rxDTree有一个参数maxUnorderedLevels,默认为32。; 在原产地的情况下,此参数将标记错误。然而,按区域对原产机场进行分组的“区域”因子变量可能是一个有用的代理,并且可以构造成仅具有有限数量的级别。数字和有序因子预测器更容易合并到模型中。
作为大型数据分类树的示例,请使用完整航空公司数据的7%子样本考虑以下简单模型(使用变量ArrDel15表示到达延迟为15分钟或更长时间的航班):
默认的CP为0会产生大量的分裂; 指定cp = 1e-5会在此模型中生成更易于管理的拆分集:
airlineTree 呼叫: rxDTree(公式= ArrDel15~CRSDepTime + DayOfWeek,data = sampleAirData, maxDepth = 5,cp = 1e-05,blocksPerRead = 30) 文件:C:\ MRS \ Data \ AirOnTime7Pct.xdf 有效观察数:10186272 失踪观察次数:213483 树表示: n = 10186272 node),split,n,deviance,yval *表示终端节点 1)root 10186272 1630331.000 0.20008640 2)CRSDepTime <13.1745 4941190 642452.000 0.15361830 4)CRSDepTime <8.3415 1777685 189395.700 0.12123970 8)CRSDepTime> = 0.658 1717573 178594.900 0.11787560 16)CRSDepTime <6.7665 599548 52711.450 0.09740671 32)CRSDepTime> = 1.625 578762 49884.260 0.09526714 * 33)CRSDepTime <1.625 20786 2750.772 0.15698070 * 17)CRSDepTime> = 6.7665 1118025 125497.500 0.12885220 34)DayOfWeek = Sun 134589 11722.540 0.09638975 * 35)DayOfWeek =周一,周二,周三,周四,周五,周六983436 113613.80 0.13329490 * 9)CRSDepTime <0.658 60112 10225.960 0.21736090 18)CRSDepTime> = 0.2415 9777 1429.046 0.17776410 * 19)CRSDepTime <0.2415 50335 8778.609 0.22505220 * 5)CRSDepTime> = 8.3415 3163505 450145.400 0.17181290 10)CRSDepTime <11.3415 1964400 268472.400 0.16335320 20)DayOfWeek = Sun 271900 30839.160 0.13043400 40)CRSDepTime <9.7415 126700 13381.800 0.12002370 * 41)CRSDepTime> = 9.7415 145200 17431.650 0.13951790 * 21)DayOfWeek =周一,周二,周三,周四,周五,周六1692500 237291.300 0.16864170 42)DayOfWeek =星期二,星期三,星期六835355 113384.500 0.16196470 * 43)DayOfWeek =星期一,星期四,星期五857145 123833.200 0.17514890 * 11)CRSDepTime> = 11.3415 1199105 181302.000 0.18567180 22)DayOfWeek =周一,周二,周三,周六,周日852016 124610.900 0.17790390 44)DayOfWeek =周二,周日,太阳342691 48917.520 0.17250230 * 45)DayOfWeek =周一,周三,周六509325 75676.600 0.18153830 * 23)DayOfWeek = Thur,Fri 347089 56513.560 0.20474000 * 3)CRSDepTime> = 13.1745 5245082 967158.500 0.24386220 6)DayOfWeek =周一,周二,周三,周六,周日3708992 651771.300 0.22746990 12)DayOfWeek = Sat 635207 96495.570 0.18681000 24)CRSDepTime> = 20.2745 87013 12025.600 0.16564190 * 25)CRSDepTime <20.2745 548194 84424.790 0.19016990 * 13)DayOfWeek =周一,周二,周三,周日3073785 554008.600 0.23587240 26)CRSDepTime <16.508 1214018 203375.700 0.21281150 52)CRSDepTime <15.1325 709846 114523.300 0.20223400 * 53)CRSDepTime> = 15.1325 504172 88661.120 0.22770400 * 27)CRSDepTime> = 16.508 1859767 349565.800 0.25092610 54)DayOfWeek =周一,周二928523 168050.900 0.23729730 * 55)DayOfWeek = Wed,Sun 931244 181170.600 0.26451500 * 7)DayOfWeek = Thur,Fri 1536090 311984.200 0.28344240 14)CRSDepTime <15.608 445085 82373.020 0.24519140 28)CRSDepTime <14.6825 273682 49360.240 0.23609880 * 29)CRSDepTime> = 14.6825 171403 32954.030 0.25970960 * 15)CRSDepTime> = 15.608 1091005 228694.300 0.29904720 30)CRSDepTime> = 21.9915 64127 11932.930 0.24718140 * 31)CRSDepTime <21.9915 1026878 216578.100 0.30228620 62)CRSDepTime <17.0745 264085 53451.260 0.28182970 * 63)CRSDepTime> = 17.0745 762793 162978.000 0.30936830 *
查看拟合对象cptable组件,我们可以看看是否已经过度拟合模型:
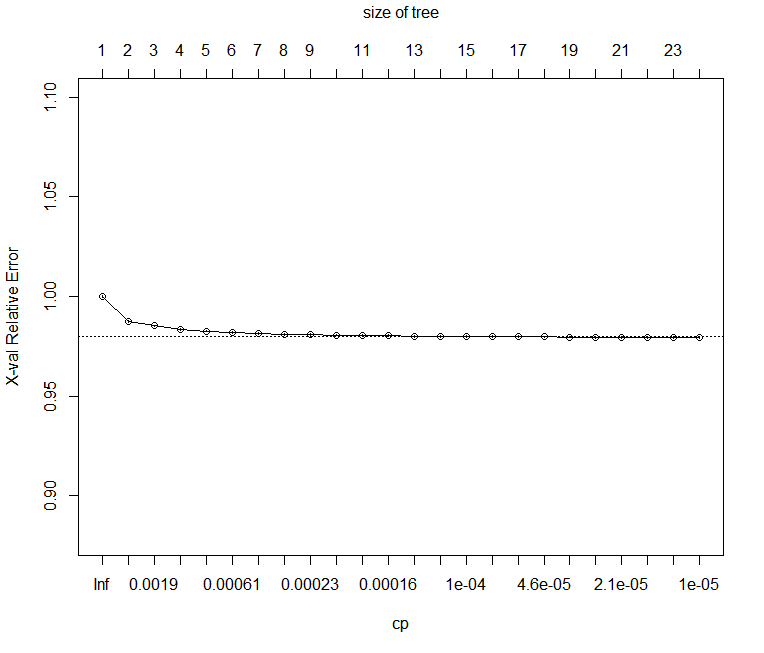
airlineTree $ cptable CP nsplit rel error xerror xstd 1 1.270950e-02 0 1.0000000 1.0000002 0.0004697734 2 2.087342e-03 1 0.9872905 0.9873043 0.0004629111 3 1.785488e-03 2 0.9852032 0.9852215 0.0004625035 4 7.772395e-04 3 0.9834177 0.9834381 0.0004608330 5 6.545095e-04 4 0.9826404 0.9826606 0.0004605065 6 5.623968e-04 5 0.9819859 0.9820200 0.0004602950 7 3.525848e-04 6 0.9814235 0.9814584 0.0004602578 8 2.367018e-04 7 0.9810709 0.9811071 0.0004600062 9 2.274981e-04 8 0.9808342 0.9808700 0.0004597725 10 2.112635e-04 9 0.9806067 0.9806567 0.0004596187 11 2.097651e-04 10 0.9803955 0.9804365 0.0004595150 12 1.173008e-04 11 0.9801857 0.9803311 0.0004594245 13 1.124180e-04 12 0.9800684 0.9800354 0.0004592792 14 1.089414e-04 13 0.9799560 0.9800354 0.0004592792 15 9.890134e-05 14 0.9798471 0.9799851 0.0004592187 16 9.125152e-05 15 0.9797482 0.9798766 0.0004591605 17 4.687397e-05 16 0.9796569 0.9797504 0.0004591074 18 4.510554e-05 17 0.9796100 0.9797292 0.0004590784 19 3.603837e-05 18 0.9795649 0.9796812 0.0004590301 20 2.771093e-05 19 0.9795289 0.9796383 0.0004590247 21 1.577140e-05 20 0.9795012 0.9796013 0.0004590000 22 1.122899e-05 21 0.9794854 0.9795671 0.0004589736 23 1.025944e-05 22 0.9794742 0.9795560 0.0004589678 24 1.000000e-05 23 0.9794639 0.9795455 0.0004589660
随着分裂数量的增加,我们看到交叉验证误差(xerror)稳步下降,但请注意,在大约nsplit = 11时,变化率会急剧减慢。最佳模型可能非常接近这里。(通过数据的总数)等于maxDepth + 3的基数加上xVal乘以(maxDepth + 2),其中xVal是交叉验证的折叠数,maxDepth是最大树深度。因此深度10个具有4倍交叉验证的树需要13 + 48或61个数据通过)。
要修剪树,请使用prune.rxDTree函数:
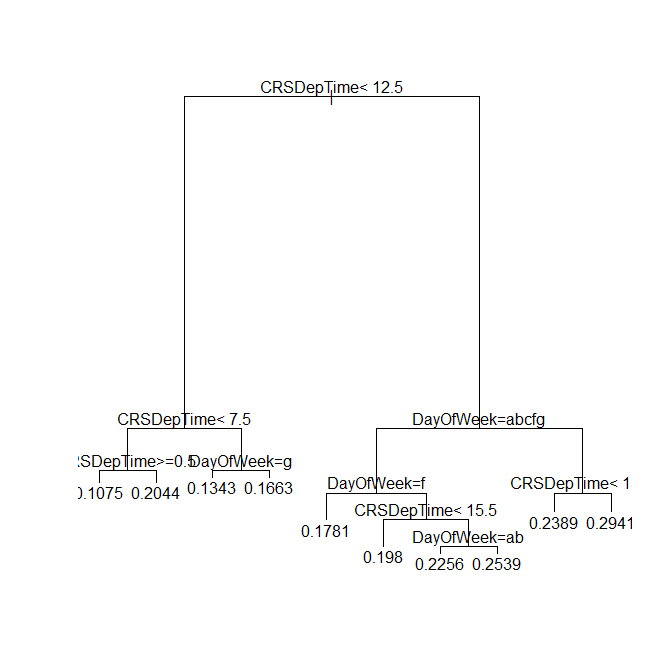
airlineTree4 呼叫: rxDTree(公式= ArrDel15~CRSDepTime + DayOfWeek,data = sampleAirData, maxDepth = 5,cp = 1e-05,blocksPerRead = 30) 文件:C:\ MRS \ Data \ AirOnTime7Pct.xdf 有效观察数:10186272 失踪观察次数:213483 树表示: n = 10186272 node),split,n,deviance,yval *表示终端节点 1)root 10186272 1630331.00 0.20008640 2)CRSDepTime <13.1745 4941190 642452.00 0.15361830 4)CRSDepTime <8.3415 1777685 189395.70 0.12123970 8)CRSDepTime> = 0.658 1717573 178594.90 0.11787560 16)CRSDepTime <6.7665 599548 52711.45 0.09740671 * 17)CRSDepTime> = 6.7665 1118025 125497.50 0.12885220 * 9)CRSDepTime <0.658 60112 10225.96 0.21736090 * 5)CRSDepTime> = 8.3415 3163505 450145.40 0.17181290 10)CRSDepTime <11.3415 1964400 268472.40 0.16335320 20)DayOfWeek = Sun 271900 30839.16 0.13043400 * 21)DayOfWeek =周一,周二,周三,周四,周五,周六1692500 237291.30 0.16864170 * 11)CRSDepTime> = 11.3415 1199105 181302.00 0.18567180 22)DayOfWeek =周一,周二,周三,周六,周日852016 124610.90 0.17790390 * 23)DayOfWeek = Thur,Fri 347089 56513.56 0.20474000 * 3)CRSDepTime> = 13.1745 5245082 967158.50 0.24386220 6)DayOfWeek =周一,周二,周三,周六,周日3708992 651771.30 0.22746990 12)DayOfWeek =周六635207 96495.57 0.18681000 * 13)DayOfWeek =周一,周二,周三,周日3073785 554008.60 0.23587240 26)CRSDepTime <16.508 1214018 203375.70 0.21281150 52)CRSDepTime <15.1325 709846 114523.30 0.20223400 * 53)CRSDepTime> = 15.1325 504172 88661.12 0.22770400 * 27)CRSDepTime> = 16.508 1859767 349565.80 0.25092610 54)DayOfWeek =周一,周二928523 168050.90 0.23729730 * 55)DayOfWeek = Wed,Sun 931244 181170.60 0.26451500 * 7)DayOfWeek = Thur,Fri 1536090 311984.20 0.28344240 14)CRSDepTime <15.608 445085 82373.02 0.24519140 * 15)CRSDepTime> = 15.608 1091005 228694.30 0.29904720 30)CRSDepTime> = 21.9915 64127 11932.93 0.24718140 * 31)CRSDepTime <21.9915 1026878 216578.10 0.30228620 *
如果安装了软件rpart,则prune.rxDTree充当剪枝函数的方法,因此您可以更简单地调用它:
对于符合2倍或更高交叉验证的模型,使用交叉验证标准错误(cptable组件的一部分)作为修剪指南很有用.rpart函数plotcp对此有用:
这产生以下图:
在此交互式树中,单击节点将展开并将节点折叠到该分支的最后一个视图。如果使用CTRL +单击,则树仅显示所选节点的子项。如果单击“ALT +单击”,树将显示所选节点下的所有级别。无法扩展称为叶子或终端节点的方形节点。
要获取其他信息,请将鼠标悬停在节点上以显示节点详细信息,例如其名称,下一个拆分变量,其值,N,预测值以及其他详细信息(如丢失或偏差)。
如果使用rxAddInheritance函数提供rpart继承,也可以将rpart plot和text方法与rxDTree对象一起使用:
提供以下图表:
有问题欢迎下方留言!