论文将搜索空间从整体网络转化为卷积单元(cell),再按照设定堆叠成新的网络家族NASNet。不仅降低了搜索的复杂度,从原来的28天缩小到4天,而且搜索出来的结构具有扩展性,在小模型和大模型场景下都能使用更少的参数量和计算量来超越人类设计的模型,达到SOTA
来源:【晓飞的算法工程笔记】 公众号
论文: Learning Transferable Architectures for Scalable Image Recognition

- 论文地址:https://arxiv.org/abs/1707.07012
Introduction
论文作者在ICLR 2017使用强化学习进行神经网络架构搜索获得了很好的表现,但该搜索方法需要计算资源很多,在CIFAR-10上需要800块GPU搜索28天,几乎不可能在大型数据集上进行搜索。因此,论文提出在代理数据集(proxy dataset)上进行搜索,然后将网络迁移到ImageNet中,主要亮点如下:
- 迁移的基础在于搜索空间的定义,由于常见的网络都是重复的结构堆叠而成的,论文将搜索空间从整个网络改成单元(cell),再按设定将单元堆叠成网络。这样做不仅搜索速度快,而且相对而言,单元结构通用性更高,可迁移
- 论文搜索到的最好结构称为NASNet,达到当时的SOTA,在CIFAR-10提升了2.4%top-1准确率,而迁移到ImageNet提升了1.2%
- 通过堆叠不同数量的单元(cell)以及修改单元中的卷积核数量,可以得到适应各种计算需求的NASNets,最小的NASNet在ImageNet top-1准确率为74.0%,比最好的移动端模型高3.1%
- NASNets学习到的图片特征十分有用,并且能够迁移到其它视觉任务中。Faster-RCNN使用最大的NASNets能直接提高4%,达到SOTA 43.1%mAP
Method
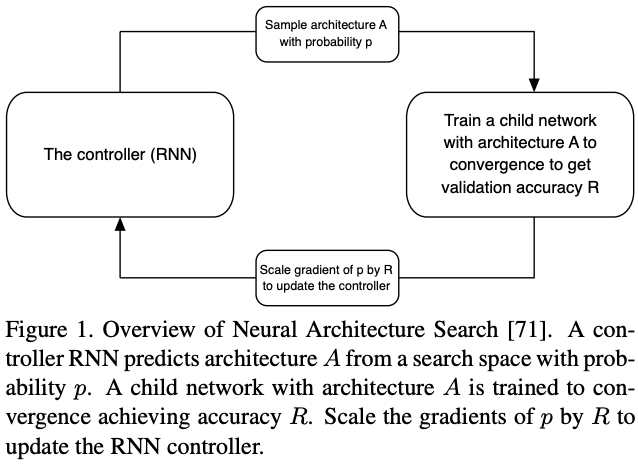
论文的神经网络搜索方法沿用了经典强化学习方法,具体可以看我之前的论文解读。流程如图1,简而言之就是使用RNN来生成网络结构,然后在数据集上进行训练,根据收敛后的准确率对RNN进行权重调整
论文的核心在于定义一个全新的搜索空间,称之为the NASNet search space。论文观察到目前优秀的网络结构,如ResNet和Inception,其实都是重复模块(cell)堆叠而成的,因此可以使用RNN来预测通用的卷积模块,这样的模块可以组合堆叠成一个系列模型,论文主要包含两种单元(cell):
- Normal Cell,卷积单元用来返回相同大小的特征图,
- Reduction Cell,卷积单元用来返回宽高缩小两倍的特征图
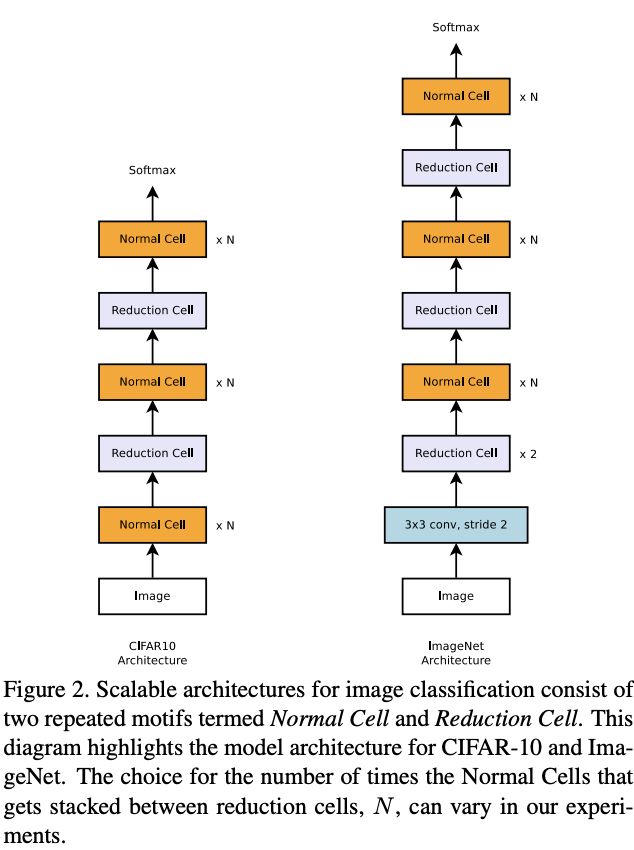
图2为CIFAR-10和ImageNet的网络框架,图片输入分别为32x32和299x299,Reduction Cell和Normal Cell可以为相同的结构,但论文发现独立的结构效果更好。当特征图的大小减少时,会手动加倍卷积核数量来大致保持总体特征点数量。另外,单元的重复次数N和初始的卷积核数量都是人工设定的,针对不同的分类问题
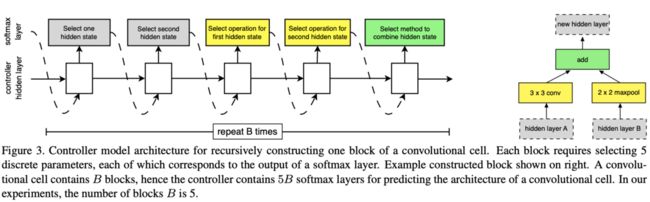
单元的结构在搜索空间内定义,首先选取前两个低层单元的输出$h_i$和$h_{i-1}$作为输入,然后the controller RNN预测剩余的卷积单元结构block,单个block预测如图3所示,每个单元(cell)由B个block组合成,每个block包含5个预测步骤,每个步骤由一个softmax分类器来选择对应的操作,block的预测如下:
- Step 1,在$h_i$,$h_{i-1}$和单元中之前的block输出中选择一个作为第一个隐藏层的输入
- Step 2,选择第二个隐藏层的输入,如Step 1
- Step 3,选择用于Step 1中的输入的操作
- Step 4,选择用于Step 2中的输入的操作
- Step 5,选择用于合并Step 3和Step 4输出的操作,并产生新的隐藏层,可供后面的block选择

Step 3和4中选择的操作包含了如上的一些主流的卷积网络操作,而Step 5的合并操作主要包含两种:1) element-wise addition 2) concatenation,最后,所有没有被使用的隐藏层输出会concatenated一起作为单元的输出。the controller RNN总共进行$2\times 5B$次预测,前$5B$作为Normal Cell,而另外$5B$则作为Reduction Cell
在RNN的训练方面,既可以用强化学习也可以用随机搜索,实验发现随机搜索仅比强化学习得到的网络稍微差一点,这意味着:
- NASNet的搜索空间构造得很好,因此随机搜索也能有好的表现
- 随机搜索是个很难打破的baseline
Experiments and Results
The controller RNN使用Proximal Policy Optimization(PPO)进行训练,以global workqueue形式对子网络进行分布式训练,实验总共使用500块P100来训练queue中的网络,整个训练花费4天,相比之前的版本800块K40训练28天,训练加速了7倍以上,效果也更好
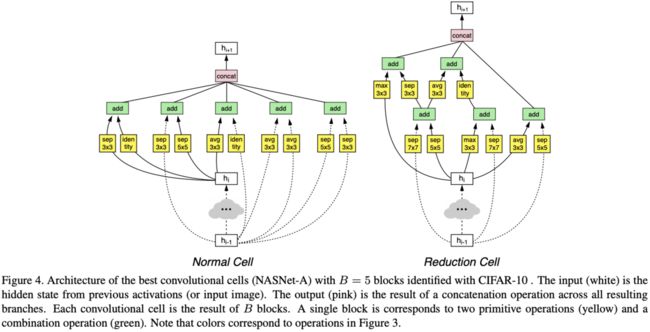
图4为表现最好的Normal Cell和Reduction Cell的结构,这个结构在CIFAR-10上搜索获得的,然后迁移到ImageNet上。在获得卷积单元后,需要修改几个超参数来构建最终的网络,首先上单元重复数N,其次上初始单元的卷积核数,例如$4@64$为单元重复4次以及初始单元的卷积核数为64
对于搜索的细节可以查看论文的Appendix A,需要注意的是,论文提出DropPath的改进版ScheduledDropPath这一正则化方法。DropPath是在训练时以一定的概率随机丢弃单元的路径(如Figure 4中的黄色框连接的边),但在论文的case中不太奏效。因此,论文改用ScheduledDropPath,在训练过程中线性增加丢弃的概率
Results on CIFAR-10 Image Classification
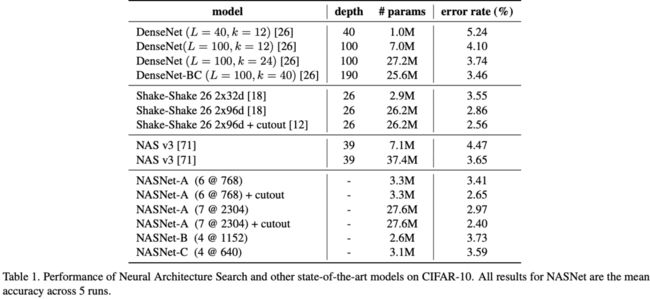
NASNet-A结合随机裁剪数据增强达到了SOTA
Results on ImageNet Image Classification
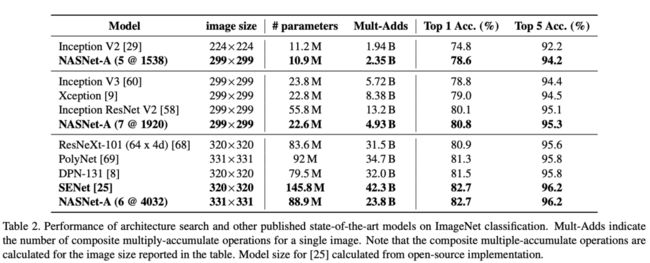
论文将在CIFAR-10上学习到的结构迁移到ImageNet上,最大的模型达到了SOTA(82.7%),与SENet的准确率一致,但是参数量大幅减少
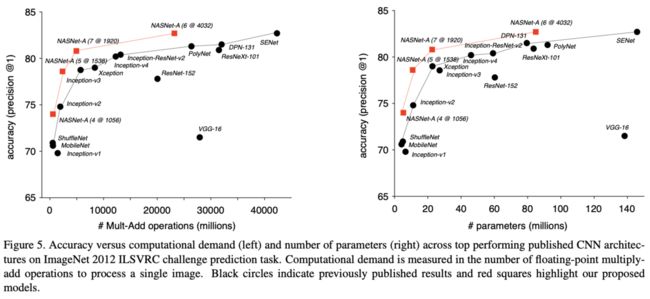
图5直观地展示了NASNet家族与其它人工构建网络的对比,NASNet各方面都比人工构建的网络要好
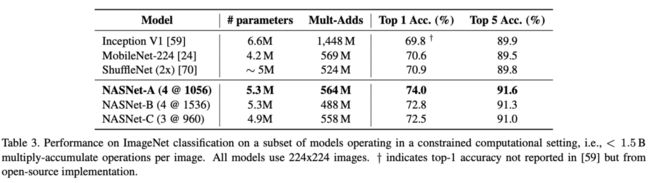
论文也测试了移动端配置的网络准确率,这里要求网络的参数和计算量要足够的小,NASNet依然有很抢眼的表现
Improved features for object detection
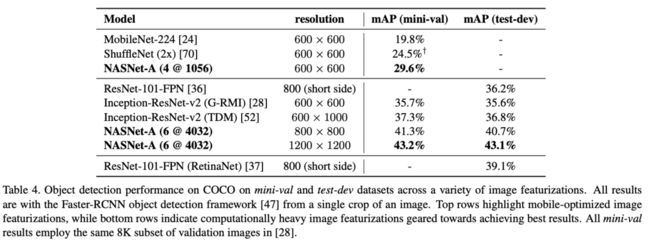
论文研究了NASNet在其它视觉任务中的表现,将NASNet作为Faster-RCNN的主干在COCO训练集上进行测试。对比移动端的网络,mAP达到29.6%mAP,提升了5.1%。而使用最好的NASNet,mAP则达到43.1%mAP,提升4.0%mAP。结果表明,NASNet能够提供更丰富且更通用的特征,从而在其它视觉任务也有很好的表现
Efficiency of architecture search methods
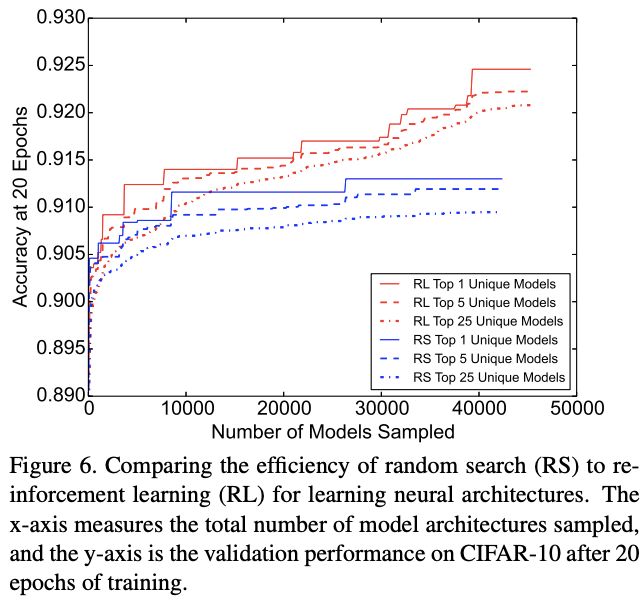
论文对比了网络搜索方法的性能,主要是强化学习方法(RL)和随机搜索方法(RS)。对于最好网络,RL搜索到的准确率整体要比RS的高1%,而对于整体表现(比如top-5和top-25),两种方法则比较接近。因此,论文认为尽管RS是可行的搜索策略,但RL在NASNet的搜索空间表现更好
CONCLUSION
论文基于之前使用强化学习进行神经网络架构搜索的研究,将搜索空间从整体网络转化为卷积单元(cell),再按照设定堆叠成新的网络NASNet。这样不仅降低了搜索的复杂度,加速搜索过程,从原来的28天缩小到4天,而且搜索出来的结构具有扩展性,分别在小模型和大模型场景下都能使用更少的参数量和计算量来超越人类设计的模型,达到SOTA
另外,由于搜索空间和模型结构的巧妙设计,使得论文能够将小数据集学习到的结构迁移到大数据集中,通用性更好。而且该网络在目标检测领域的表现也是相当不错的
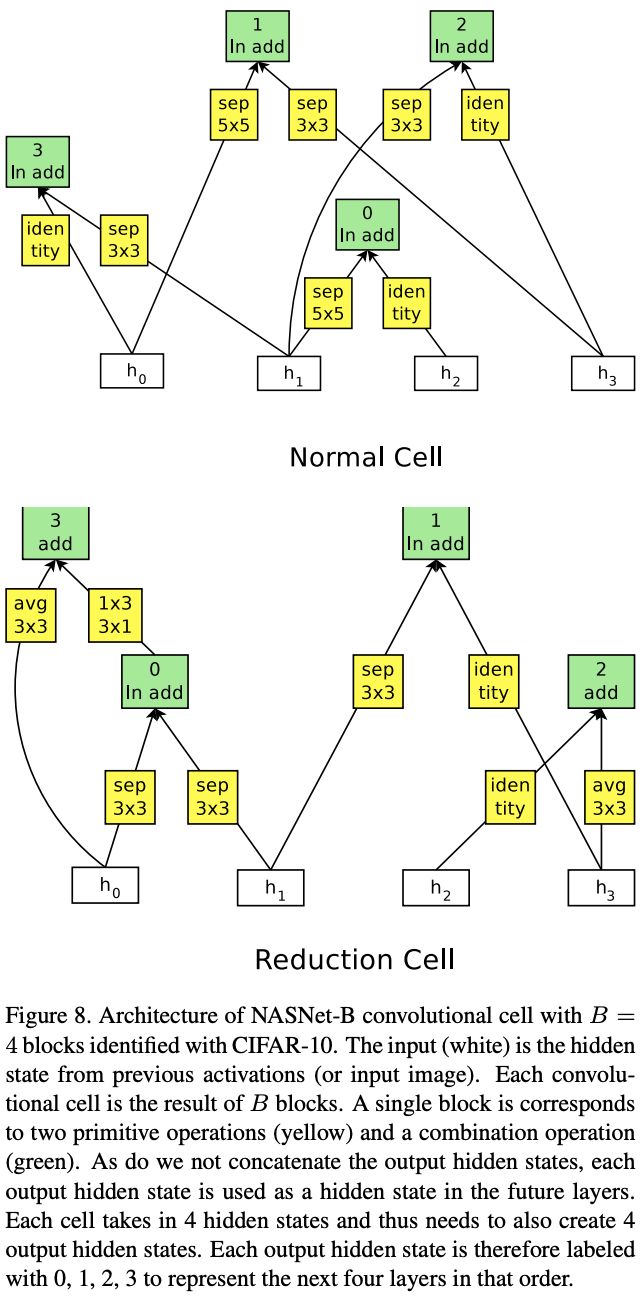
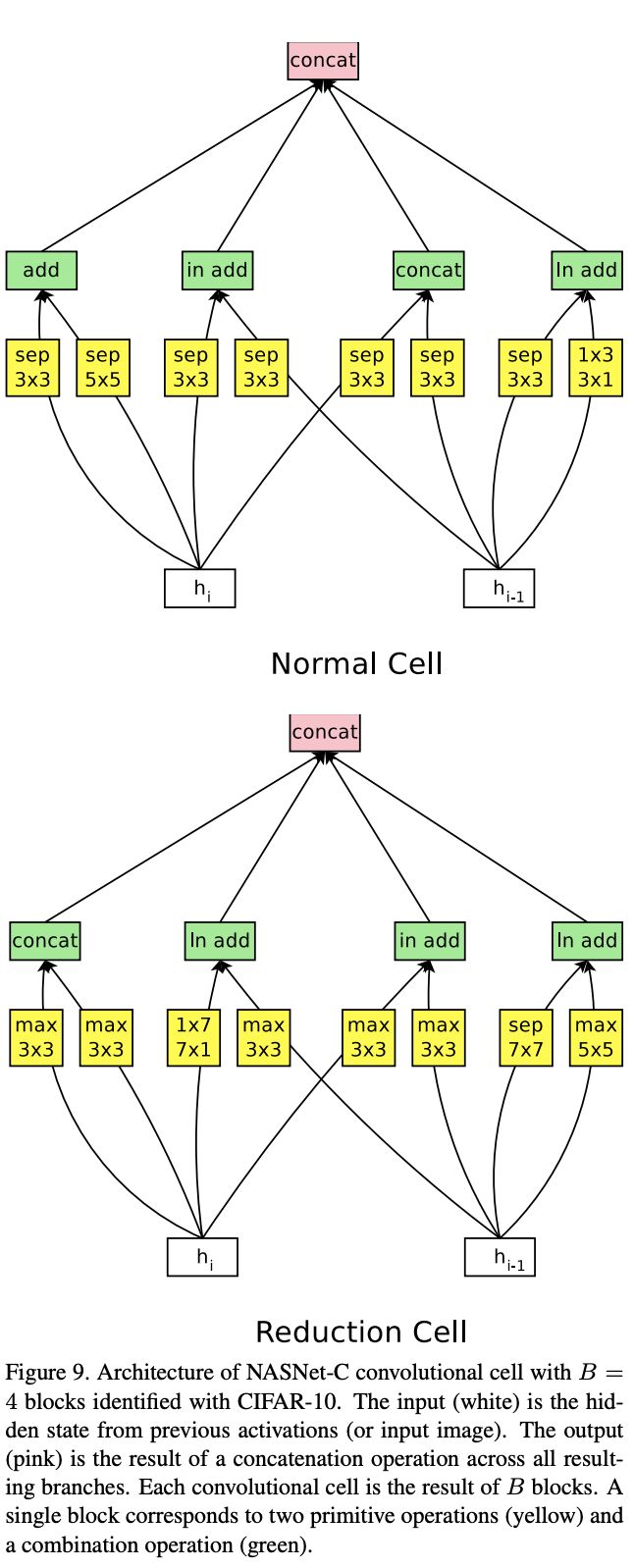
Appendix NASNet-B & NASNet-C
论文还有另外两种结构NASNet-B和NASNet-C,其搜索空间和方法与NASNet-A有点区别,有兴趣的可以去看看原文的Appendix
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
