编程的乐趣和挑战之一,就是将体力活自动化,使效率成十倍百倍的增长。
需求
做一个项目,需要返回一个很大的 JSON 串,有很多很多很多字段,有好几层嵌套。前端同学给了一个 JSON 串,需要从这个 JSON 串建立对应的对象模型。
比如,给定 JSON 串:
{"error":0,"status":"success","date":"2014-05-10","extra":{"rain":3,"sunny":2},"recorder":{"name":"qin","time":"2014-05-10 22:00","mood":"good","address":{"provice":"ZJ","city":"nanjing"}},"results":[{"currentCity":"南京","weather_data":[{"date":"周六今天,实时19","dayPictureUrl":"http://api.map.baidu.com/images/weather/day/dayu.png","nightPictureUrl":"http://api.map.baidu.com/images/weather/night/dayu.png","weather":"大雨","wind":"东南风5-6级","temperature":"18"},{"date":"周日","dayPictureUrl":"http://api.map.baidu.com/images/weather/day/zhenyu.png","nightPictureUrl":"http://api.map.baidu.com/images/weather/night/duoyun.png","weather":"阵雨转多云","wind":"西北风4-5级","temperature":"21~14"}]}]}
解析出对应的对象模型:
@Data
public class Domain implements Serializable {
private Integer error;
private String status;
private String date;
private List results;
private Extra extra;
private Recorder recorder;
}
@Data
public class Extra implements Serializable {
private Integer rain;
private Integer sunny;
}
@Data
public class Recorder implements Serializable {
private String name;
private String time;
private String mood;
private Address address;
}
@Data
public class Address implements Serializable {
private String provice;
private String city;
}
@Data
public class Result implements Serializable {
private String currentCity;
private List weatherDatas;
}
@Data
public class WeatherData implements Serializable {
private String date;
private String dayPictureUrl;
private String nightPictureUrl;
private String weather;
private String wind;
private String temperature;
}
怎么办呢 ? 那么复杂的 JSON 串,手写的话,估计得写两个小时吧,又枯燥又容易出错。能否自动生成呢 ?
算法分析
显然,需要遍历这个 JSON ,分三种情形处理:
- 值为基本类型: 解析出对应的类型 type 和 字段名 name
- 值为 JSON 串: 需要递归处理这个 JSON 串
- 值为 List : 简单起见,取第一个元素,如果是基本类型,按基本类型处理,类型为 List[Type] ;如果是 JSON ,则类型为 List[ClassName],然后再递归处理这个 JSON。
一个代码实现
第一版程序如下,简单直接。这里用到了一些知识点:
- 递归处理: 在 parseMap 方法中实现了递归处理。递归处理需要设置合适的参数结构,当发现又遇到同样的参数结构,就可以递归调用自身。在递归函数中要注意设置条件退出。
- 函数编程: 在 parseMap 方法中传入 keyConverter 是为了处理下划线转驼峰。不传则默认不转换。
- JSON 转换为对象:
jsonSlurper.parseText(json) - 最简单的模板引擎: SimpleTemplateEngine
engine.createTemplate(tplText).make(binding).toString() - 字符串中的变量引用和方法调用:
"${indent()}private ${getType(v)} $k;\n"
JsonParser.groovy
package cc.lovesq.study.json
import groovy.json.JsonSlurper
import static cc.lovesq.study.json.Common.*
class JsonParser {
def jsonSlurper = new JsonSlurper()
def parse(json) {
def obj = jsonSlurper.parseText(json)
Map map = (Map) obj
parseMap(map, 'Domain', Common.&underscoreToCamelCase)
}
def parseMap(Map map, String namespace, keyConverter) {
def classTpl = classTpl()
def fields = ""
map.each {
k, v ->
if (!(v instanceof Map) && !(v instanceof List)) {
fields += "${indent()}private ${getType(v)} $k;\n"
}
else {
if (v instanceof Map) {
def className = getClsName(k)
fields += "${indent()}private $className $k;\n"
parseMap(v, convert(className, keyConverter), keyConverter)
}
if (v instanceof List) {
def obj = v.get(0)
if (!(obj instanceof Map) && !(obj instanceof List)) {
def type = getType(obj)
fields += "${indent()}private List<$type> ${type}s;\n"
}
if (obj instanceof Map) {
def cls = getClsName(k)
if (cls.endsWith('s')) {
cls = cls[0..-2]
}
def convertedClsName = convert(cls,keyConverter)
fields += "${indent()}private List<${convertedClsName}> ${uncapitalize(convertedClsName)}s;\n"
parseMap(obj, convertedClsName, keyConverter)
}
}
}
}
print getString(classTpl, ["Namespace": namespace, "fieldsContent" : fields])
}
}
Common.groovy
package cc.lovesq.study.json
class Common {
def static getType(v) {
if (v instanceof String) {
return "String"
}
if (v instanceof Integer) {
return "Integer"
}
if (v instanceof Boolean) {
return "Boolean"
}
if (v instanceof Long) {
return "Long"
}
if (v instanceof BigDecimal) {
return "Double"
}
"String"
}
def static getClsName(String str) {
capitalize(str)
}
def static capitalize(String str) {
str[0].toUpperCase() + (str.length() >= 2 ? str[1..-1] : "")
}
def static uncapitalize(String str) {
str[0].toLowerCase() + (str.length() >= 2 ? str[1..-1] : "")
}
def static classTpl() {
'''
@Data
public class $Namespace implements Serializable {
$fieldsContent
}
'''
}
def static indent() {
' '
}
def static getString(tplText, binding) {
def engine = new groovy.text.SimpleTemplateEngine()
return engine.createTemplate(tplText).make(binding).toString()
}
def static convert(key, convertFunc) {
convertFunc == null ? key : convertFunc(key)
}
def static underscoreToCamelCase(String underscore){
String[] ss = underscore.split("_")
if(ss.length ==1){
return underscore
}
return ss.collect { capitalize(it) }.join("")
}
}
构建与表示分离
第一版的程序简单直接,但总感觉有点粗糙。整个处理混在一起,后续要修改恐怕比较困难。能不能更清晰一些呢 ?
可以考虑将构建与表示分离开。
表示
仔细再看下对象模型,可以归结出三个要素:
- 一个类是一个类节点 ClassNode,有一个名字空间 namespace (类名);
- 有一系列属性,每个属性有属性名与属性类型,可称为叶子节点 LeafNode;
- 有一系列子节点类 ClassNode,子节点类可以递归处理。
实际上,对象模型符合树形结构。如图所示:
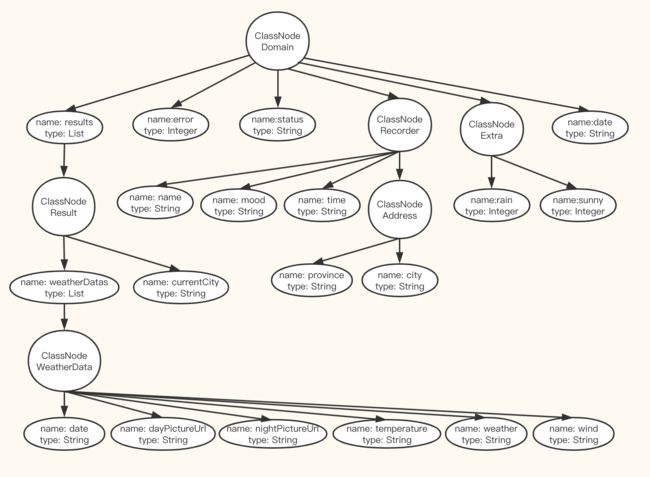
节点
可以定义一个节点接口。节点只有一个行为 desc() ,就是描述自己 。 LeafNode 和 ClassNode 分别实现自己的 desc() 。
interface Node {
String desc()
}
叶子节点
叶子节点比较简单,只有属性名和属性类型。isList 表示是否是 List 类型,比如 List[String]。List 类型的渲染略有不同。
class LeafNode implements Node {
String type
String name
Boolean isList = false
@Override
String desc() {
isList ? Common.getString("private List<$type> $name;", ["type": type, "name": name]) :
Common.getString("private $type $name;", ["type": type, "name": name])
}
}
类节点
类节点包含一系列叶子节点和子节点类(递归特性)。 在描述自身的时候,还要递归描述所包含的子节点类。 这里用到了 findAll {} , collect {} 闭包特性,可以使代码实现更加简洁一些。
class ClassNode implements Node {
String className = ""
List leafNodes = []
List classNodes = []
Boolean isInList = false
@Override
String desc() {
def clsTpl = Common.classTpl()
def fields = ""
fields += leafNodes.collect { indent() + it.desc() }.join("\n")
def classDef = getString(clsTpl, ["Namespace": className, "fieldsContent" : fields])
if (CollectionUtils.isEmpty(classNodes)) {
return classDef
}
fields += "\n" + classNodes.findAll { it.isInList == false }.collect { "${indent()}private ${it.className} ${uncapitalize(it.className)};" }.join("\n")
def resultstr = getString(clsTpl, ["Namespace": className, "fieldsContent" : fields])
resultstr += classNodes.collect { it.desc() }.join("\n")
return resultstr
}
boolean addNode(LeafNode node) {
leafNodes.add(node)
true
}
boolean addNode(ClassNode classNode) {
classNodes.add(classNode)
true
}
}
这样,就完成了对象模型的表示。
接下来,需要完成 ClassNode 的构建。这个过程与第一版的基本类似,只是从直接打印信息变成了添加节点。
构建
构建 ClassNode 的实现如下。有几点值得提一下:
- 策略模式。分离了三种情况(基本类型、Map, List)的处理。当有多重 if-else 语句,且每个分支都有大段代码达到同一个目标时,就可以考虑策略模式处理了。
- 构建器。将 ClassNode 的构建单独分离到 ClassNodeBuilder 。
- 组合模式。树形结构的处理,特别适合组合模式。
- 命名构造。使用命名构造器,从而免写了一些构造器。
ClassNodeBuilder.groovy
package cc.lovesq.study.json
import groovy.json.JsonSlurper
import static cc.lovesq.study.json.Common.*
class ClassNodeBuilder {
def jsonSlurper = new JsonSlurper()
def build(json) {
def obj = jsonSlurper.parseText(json)
Map map = (Map) obj
return parseMap(map, 'Domain')
}
def static parseMap(Map map, String namespace) {
ClassNode classNode = new ClassNode(className: namespace)
map.each {
k, v ->
getStratgey(v).add(classNode, k, v)
}
classNode
}
def static plainStrategy = new AddLeafNodeStrategy()
def static mapStrategy = new AddMapNodeStrategy()
def static listStrategy = new AddListNodeStrategy()
def static getStratgey(Object v) {
if (v instanceof Map) {
return mapStrategy
}
if (v instanceof List) {
return listStrategy
}
return plainStrategy
}
interface AddNodeStrategy {
def add(ClassNode classNode, k, v)
}
static class AddLeafNodeStrategy implements AddNodeStrategy {
@Override
def add(ClassNode classNode, Object k, Object v) {
classNode.addNode(new LeafNode(type: getType(v), name: k))
}
}
static class AddMapNodeStrategy implements AddNodeStrategy {
@Override
def add(ClassNode classNode, Object k, Object v) {
v = (Map)v
def className = getClsName(k)
classNode.addNode(parseMap(v, className))
}
}
static class AddListNodeStrategy implements AddNodeStrategy {
@Override
def add(ClassNode classNode, Object k, Object v) {
v = (List)v
def obj = v.get(0)
if (!(obj instanceof Map) && !(obj instanceof List)) {
def type = getType(obj)
classNode.addNode(new LeafNode(type: "$type", name: "${type}s", isList: true))
}
if (obj instanceof Map) {
def cls = getClsName(underscoreToCamelCase(k))
if (cls.endsWith('s')) {
cls = cls[0..-2]
}
classNode.addNode(new LeafNode(type: "${cls}", name: "${uncapitalize(cls)}s", isList: true))
def subClassNode = parseMap(obj, cls)
subClassNode.isInList = true
classNode.addNode(subClassNode)
}
}
}
}
细节优化
文章写成之后,往往要经过一些“润色”。 程序实现之后,也要进行一些细节优化。 有哪些优化点呢 ? 注意到,JSON 数据可能是不可靠的,比如含有 null ,空数组,JSON 中的字段参差不齐等。
健壮性
注意到,添加 List 元素时,有个 get(0) 操作。 如果列表为空会怎样,显然会抛出越界异常了。 因此,需要做判空处理。
字段补全
假设天气数据 weather_datas 是如下所示。
[{},{"date":"周六今天,实时19","dayPictureUrl":"http://api.map.baidu.com/images/weather/day/dayu.png","nightPictureUrl":"http://api.map.baidu.com/images/weather/night/dayu.png","weather":"大雨","temperature":"18"},{"date":"周日","dayPictureUrl":"http://api.map.baidu.com/images/weather/day/zhenyu.png","nightPictureUrl":"http://api.map.baidu.com/images/weather/night/duoyun.png","wind":"西北风4-5级","temperature":"21~14"}]
取第一个的话,是空对象,这样,WeatherData 对象就解析不出来了;取第二个的话,少了个 wind 字段;取第三个的话,少了个 weather 。无论取哪一个,生成的 WeatherData 都是不完整的。
怎么办呢 ? 此时,就不能取第一个对象,而是要遍历所有的对象,加入所有在 json 中存在的字段。
主要是对 AddListNodeStrategy 进行优化。 如果 JSON 数据是规范的,每个对象都是相同的字段,那么 isTravelFull = false ,取第一个对象解析即可; 如果 JSON 数据是不规范的,则 isTravelFull = true , 需要补全所有的字段。
补全算法:
STEP1:初始化最终的完整对象 full ;
STEP2:遍历所有的对象以及这些对象里的所有 key, value : 如果 full 里没有这个 key ,那么加入这个 key 和 value ;如果 full 里已经有了这个 key, 则取出已有的值 exist 和 当前的值 subv 进行比较和合并,并加入 key 和 合并后的值。 直到所有的对象及对象里的 key , value 处理完毕。
合并两个值,分三种情况:
-
是基本类型,任取一个值;
-
是列表类型,如果已有的为空,当前的非空,则用当前的替代已有的。因为空列表无法解析出列表里的对象。
-
是对象类型,如果两个对象大小一样,任取一个;如果两个对象的大小不一样,递归合并两个对象。
代码如下所示。
static class AddListNodeStrategy implements AddNodeStrategy {
/* 是否要遍历列表中的所有元素来拼接成一个完整的对象,适用于 json 的返回数据字段可能有不全的情形 */
private static isTravelFull = true
@Override
def add(ClassNode classNode, Object k, Object v) {
v = (List)v
if (CollectionUtils.isEmpty(v)) {
return
}
def obj = v.get(0)
if (!(obj instanceof Map) && !(obj instanceof List)) {
def type = getType(obj)
classNode.addNode(new LeafNode(type: "$type", name: "${type}s", isList: true))
}
if (obj instanceof Map) {
def cls = getClsName(underscoreToCamelCase(k))
if (cls.endsWith('s')) {
cls = cls[0..-2]
}
classNode.addNode(new LeafNode(type: "${cls}", name: "${uncapitalize(cls)}s", isList: true))
addSubClassNode(classNode, v, cls)
}
}
private void addSubClassNode(ClassNode classNode, v, cls) {
def subObj = v.get(0)
if (isTravelFull) {
subObj = mergeToFull(v)
}
def subClassNode = parseMap(subObj, cls)
subClassNode.isInList = true
classNode.addNode(subClassNode)
}
private Map mergeToFull(List看来,策略分离还是很有益的。需要做优化或扩展时,只需要有针对性改一处即可。
小结
JSON 是一种具有任意嵌套结构的数据交换格式。要解析 JSON, 通常要用到递归算法。JSON 通常又可以对应到一个对象模型,对象模型可以用树形结构来表示。树形结构同样具有递归特性。
在完成总体设计和实现后 , 往往要进行细节优化。细节的完善决定了实现的完善度。
通过编写程序,从 JSON 串中自动生成对应的对象模型,使得这个过程自动化,让类似事情的效率成倍的增长了。原来可能要花费十几分钟甚至一个小时之多,现在不到三秒。
让效率成倍增长的有效之法就是提升代码和方案的复用性,自动化手工处理。在日常工作中,是否可以想到办法,让手头事情的处理效率能够十倍百倍的增长呢 ? 这个想法看似有点疯狂,实际上,更多的原因是我们很少这么思考过吧。