1. BAM
BAM全程是bottlenect attention module,与CBAM很相似的起名,还是CBAM的团队完成的作品。
CBAM被ECCV18接受,BAM被BMVC18接收。
CBAM可以看做是通道注意力机制和空间注意力机制的串联(先通道后空间),BAM可以看做两者的并联。
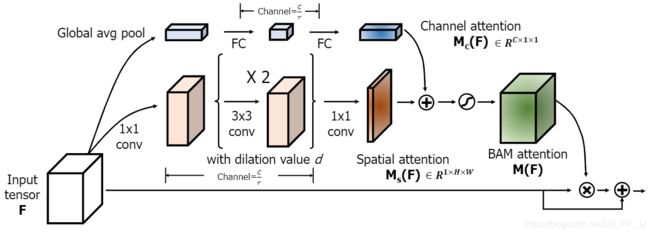
这个模块之所以叫bottlenect是因为这个模块放在DownSample 也就是pooling layer之前,如下图所示:
由于改论文与上一篇:CBAM的理论部分极为相似,下边直接进行实现部分。
2. 通道部分的实现
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channel, reduction_ratio=16, num_layers=1):
super(ChannelGate, self).__init__()
self.gate_c = nn.Sequential()
self.gate_c.add_module('flatten', Flatten())
gate_channels = [gate_channel] # eg 64
gate_channels += [gate_channel // reduction_ratio] * num_layers # eg 4
gate_channels += [gate_channel] # 64
# gate_channels: [64, 4, 4]
for i in range(len(gate_channels) - 2):
self.gate_c.add_module(
'gate_c_fc_%d' % i,
nn.Linear(gate_channels[i], gate_channels[i + 1]))
self.gate_c.add_module('gate_c_bn_%d' % (i + 1),
nn.BatchNorm1d(gate_channels[i + 1]))
self.gate_c.add_module('gate_c_relu_%d' % (i + 1), nn.ReLU())
self.gate_c.add_module('gate_c_fc_final',
nn.Linear(gate_channels[-2], gate_channels[-1]))
def forward(self, x):
avg_pool = F.avg_pool2d(x, x.size(2), stride=x.size(2))
return self.gate_c(avg_pool).unsqueeze(2).unsqueeze(3).expand_as(x)
看上去代码要比CBAM中的ChannelAttention模块要多很多,贴上ChannelAttention代码方便对比:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
首先讲ChannelGate的处理流程:
-
使用avg_pool2d测试
>>> import torch.nn.functional as F >>> import torch >>> x = torch.ones((12, 8, 64, 64)) >>> x.shape torch.Size([12, 8, 64, 64]) >>> F.avg_pool2d(x,x.size(2), stride=x.size(2)).shape torch.Size([12, 8, 1, 1]) >>>其效果与AdaptiveAvgPool2d(1)是一样的。
-
然后经过gate_c模块,里边先经过Flatten将其变为[batch size, channel]形状的tensor, 然后后边一大部分都是Linear模块,进行线性变换。(ps:虽然代码看上去多,但是功能也就那样)这个部分与SE模块有一点相似,但是要更丰富一点。
-
最终按照输入tensor x的形状进行扩展,得到关于通道的注意力。
然后讲一下与CBAM中的区别:
- CBAM中使用的是卷积实现的通道处理,这里使用的是线性变换Linear,但是背后的数学原理应该是一致的,区别在于计算量上
- CBAM中激活函数使用sigmoid, BAM中的通道部分使用了ReLU,还添加了BN层
3. 空间注意力机制
class SpatialGate(nn.Module):
def __init__(self,
gate_channel,
reduction_ratio=16,
dilation_conv_num=2,
dilation_val=4):
super(SpatialGate, self).__init__()
self.gate_s = nn.Sequential()
self.gate_s.add_module(
'gate_s_conv_reduce0',
nn.Conv2d(gate_channel,
gate_channel // reduction_ratio,
kernel_size=1))
self.gate_s.add_module('gate_s_bn_reduce0',
nn.BatchNorm2d(gate_channel // reduction_ratio))
self.gate_s.add_module('gate_s_relu_reduce0', nn.ReLU())
# 进行多个空洞卷积,丰富感受野
for i in range(dilation_conv_num):
self.gate_s.add_module(
'gate_s_conv_di_%d' % i,
nn.Conv2d(gate_channel // reduction_ratio,
gate_channel // reduction_ratio,
kernel_size=3,
padding=dilation_val,
dilation=dilation_val))
self.gate_s.add_module(
'gate_s_bn_di_%d' % i,
nn.BatchNorm2d(gate_channel // reduction_ratio))
self.gate_s.add_module('gate_s_relu_di_%d' % i, nn.ReLU())
self.gate_s.add_module(
'gate_s_conv_final',
nn.Conv2d(gate_channel // reduction_ratio, 1, kernel_size=1))
def forward(self, x):
return self.gate_s(x).expand_as(x)
这里可以看出,代码量相比CBAM中的spatial attention要大很多,依然进行对比:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)
这个部分空间注意力处理就各有特色了,先说一下BAM中的流程:
- 先经过一个conv+bn+relu模块,通道缩进,信息进行压缩
- 然后经过了两个dilated conv+bn+relu模块,空洞率设置为4(默认)
- 最后经过一个卷积,将通道压缩到1
- 最终将其扩展为tensor x的形状
区别在于:
- CBAM中通过通道间的max,avg处理成通道数为2的feature, 然后通过卷积+Sigmoid得到最终的map
- BAM中则全部通过卷积或者空洞卷积完成信息处理,计算量更大一点, 但是融合了多感受野,信息更加丰富。
4. BAM融合
class BAM(nn.Module):
def __init__(self, gate_channel):
super(BAM, self).__init__()
self.channel_att = ChannelGate(gate_channel)
self.spatial_att = SpatialGate(gate_channel)
def forward(self, x):
att = 1 + F.sigmoid(self.channel_att(x) * self.spatial_att(x))
return att * x
最终融合很简单,需要注意的就是两者是相乘的,并且使用了sigmoid进行归一化。
后记:感觉BAM跟CBAM相比有一点点复杂,没有CBAM的那种简洁美。这两篇都是坐着在同一时期进行发表的,所以并没有互相的一个详细的对照,但是大概看了一下,感觉CBAM效果好于BAM。