数据结构是 10 年前大学里学的一门课程,也是我北漂唯一携带的一本书。幸运的是,书还没有被孩子给撕碎。
为了让大家都能够搞懂「树」这个苦涩而硬核的知识,今天就重拾记忆,分享一下研发人员心中那些放不下的「树」。
不过,一定要冲好咖啡、沏壶好茶,心平气和去看文。

01. 「树」现实与虚拟的抽象
在「中华姓氏树」中寻找一片属于你的叶子,探寻一下家族的来源。

在脑海里尝试画一下「家谱树」。

看完现实中的树,那来看一看计算机的文件系统组织形式。

无论是现实的姓氏树、家谱树,还是计算机的文件系统,表现形式虽然不同,但是本质上却都是树。
那到底什么是树呢?
树是由 n(n≥0)个结点组成的有限集合。
当 n = 0 时,称为空树;
当 n > 0 时,有一个特殊的节点称为根结点(root),它没有前驱结点;其它结点分为 m 棵互不相交的子树。
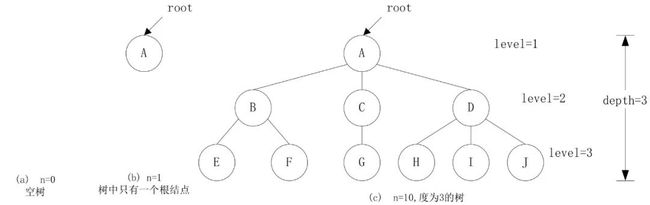
如图示意,(a)为空树;(b)为 1 个结点的树;(c)为 n 个结点的树。
知道了什么是树,上面「家谱树」以及「文件系统」用到的树表示法,有没有学名呢?稍微科普一下。
图示法:是树的直观表示法,主要用于描述树的逻辑结构,如上面提到的家谱树。
横向凹入表示法:是用逐层缩进方法表示结点之间的层次关系,主要用于树的屏幕显示和打印输出,如上面提到的文件系统。
知道了什么树以及树的部分表示法,但是猿有猿声,鸟有鸟语,树也有术语。
02.「树」有术语
节点 or 结点,别再傻傻分不清?
节点:线上一个节点扛不住压力,那就索性再加一个节点。所以节点一般被认为是一个有处理能力的实体,例如一台服务器;
结点:包含一个数据元素及若干指向其子树的分支,在树的图形表示中为一个圆圈,算法中的点一般指的都是结点。
有些老铁习惯用「节点」,有些喜欢用「结点」,到底用哪个?
之前也没太注意这个细节,本次分享就采用「结点」二字。
话又说回来,只要掌握了本领,打败敌人,到底用的是亢龙有悔还是飞龙在天,其实已经没啥意义啦。

父结点、孩子结点与兄弟结点?
父结点:若一个结点含有孩子结点,则这个结点称为其孩子结点的父结点;如上图所示,B、C、D 的父结点都是 A;
孩子结点:一个结点含有的子树的根结点称为该结点的孩子结点;定义还是比较拗口,还是直接看图吧,B 的孩子结点为 E、F;
兄弟节点:具有相同父结点的结点互称为兄弟结点;如上图所示,B、C、D 具有相同的父结点 A,所以 B、C、D 为兄弟结点;
什么是度?
结点的度:一个结点拥有子树的个数称为该结点的度;如上图所示,A 结点拥有 B、C、D 三棵子树,所以 A 结点的度为 3;
树的度:一棵树中,最大的结点度称为树的度;如上图所示,最大的结点度为 3,所以树的度为 3;
结点层次、树的深度或高度?
结点层次:从根开始算起,根为第 1 层,根的子节点为第 2 层,以此类推;如上图所示,E 结点层次为第 3 层;
树的深度或高度:树中结点的最大层次数;如上图所示,由于结点最大层次树为 3,所以树的深度或高度为 3;
啥是森林?
森林:由 m(m>=0)棵互不相交的树的集合称为森林。给森林加上一个根结点就变成一棵树,将树的根结点删除就变成森林。
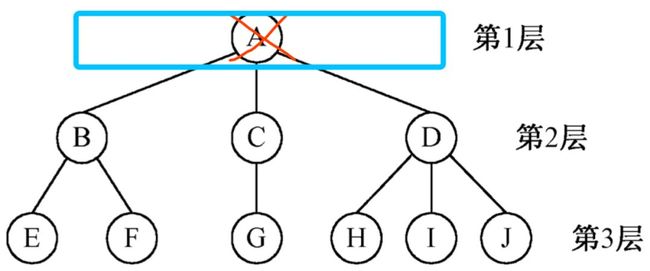
如图所示,把根结点 A 剔除,就会变成以 B、C、D 为根的 3 棵互不相关的树组成的森林。
了解完树的术语,万里长征才算刚迈第一步,接下来就一起看看树的分类。
03. 二叉「树」
啥是二叉树?
二叉树(binary tree)是 n(n≥0)个结点组成的有限集合。
n = 0 时称为空二叉树;
n > 0 的二叉树由一个根结点和两棵互不相交的、分别称为左子树和右子树的子二叉树构成。
另外,二叉树的子树有左、右之分,所以只有一个子树也要区分是左子树还是右子树。

如上图所示,二叉树主要有以下五种形态:
(a)空二叉树;
(b)只有一个根结点的二叉树;
(c)由根结点、非空的左子树和空的右子树组成的二叉树;
(d)由根结点、空的左子树和非空的右子树组成的二叉树;
(e)由根结点、非空的左子树和非空的右子树组成的二叉树。
满二叉树与完全二叉树?

当二叉树的每一层的结点数目都达到最大值,则称为满二叉树。若对满二叉树的结点进行连续编号,约定根结点的序号为 0,从根结点开始,自上而下,每层自左至右编号,如上图(a)所示。
完全二叉树相对满二叉树而言,节点数是任意的,从形式上去看,最后那一行可能是不完整的,可能右下角某个连续的部分缺失,如上图(b)所示。
另外,满二叉树一定是完全二叉树,而完全二叉树不一定是满二叉树,区别就在最后一层上。
04. 二叉排序「树」
啥是二叉排序树(Binary sort tree)?
二叉排序树可以是一棵空树,或者是具有如下性质的二叉树:
1. 每个结点都有一个作为查找依据的关键字,而且所有结点的关键字互不相同;
2. 结点,左子树元素均小于该结点,右子树元素均大于该结点;
3. 左、右子树也是二叉排序树。
二叉排序树怎么查找?
如果要在一棵二叉排序中,查找值为 value 的结点,算法描述如下:
第一步:从根结点开始,设 p 指向根结点;
第二步:若 key == p.data,则查找成功返回;若 key < p.data,则查找 p 的左子树;否则查找 p 的右子树;
第三步:重复执行第二步,直到 p 为空,查找不成功。
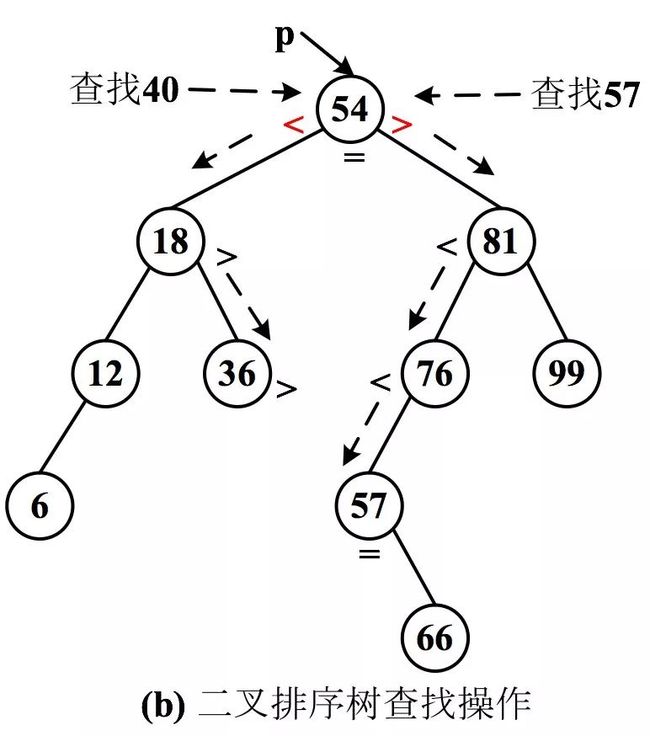
假如要查找 40,那么查找路径是(54,18,36),经过叶子结点 36,查找不成功。
假如要查找 57,那么查找路径是(54,81,76,57),到达结点 57,查找成功。
聪明的小伙伴应该已经看出,在二叉排序树中,一次查找经过从根结点到某结点的一条路径,而不需要遍历整棵树,若查找成功则到达指定结点,否则经过某个叶子结点。
由于二叉排序树能够提供快速查找功能,所以二叉排序树又称为二叉查找树(Binary search tree)。
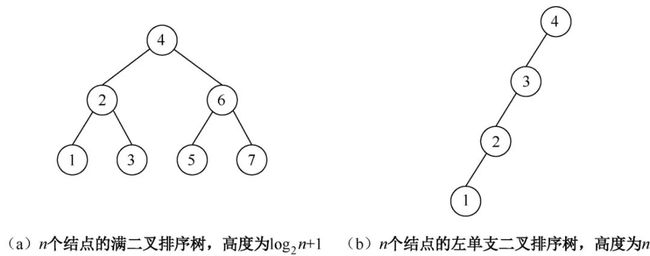
在图(a)中查找结点 1,那么查找路径为(4,2,1),但是在图(b)中的查找路径为(4,3,2,1)。
二叉排序树的查找效率与二叉树的高度有关,高度越低,查找效率越高。因此,提高二叉排序树查找效率的办法是尽量降低二叉排序树的高度,于是就有了平衡二叉树。
05. 平衡二叉「树」
啥是平衡二叉树?
平衡二叉树由两位前苏联数学家 G.M.Adel'sen-Velskii 和 E.M.Landis 于 1962 年提出,因此又被称为 AVL 树。
平衡二叉树的主要的特点:它的左子树与右子树的高度之差绝对值不超过 1;它的左子树和右子树都是平衡二叉树。
另外,结点的平衡因子 = 左子树的高度 – 右子树的高度,在平衡二叉树中任何一个结点的平衡因子只能是 -1、0 或 1。下图中每个结点旁边标出的数字是该节点的平衡因子。
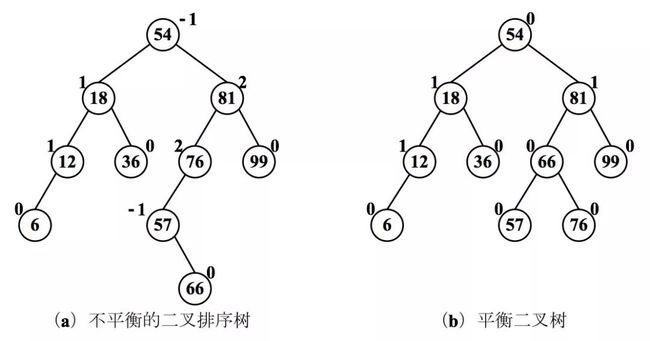
如图(a)所示的二叉排序树不平衡,因为结点 81、76 的平衡因子都是 2。
如图(b)所示的二叉树是平衡二叉树,因为每个结点的平衡因子绝对值都不超过 1。
但是,聪明的你们,肯定也会想到,在面对新结点加入时,可能会使平衡二叉树不平衡,那么就需要通过旋转来达到平衡。但是,无论怎么旋转,都无外乎 LL、RR、LR 和 RL 四种情形,下面一起来旋转一下,千万别转晕喽(旋转不明白也没关系,直接往下跳着看)。
LL 型调整(左子树的左边结点)
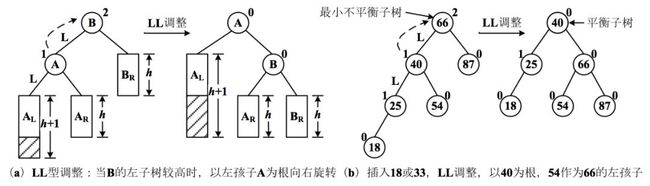
RR 型调整(右子树的右边结点)

LR 型调整(左子树的右边结点)

RL 型调整(右子树的左边结点)
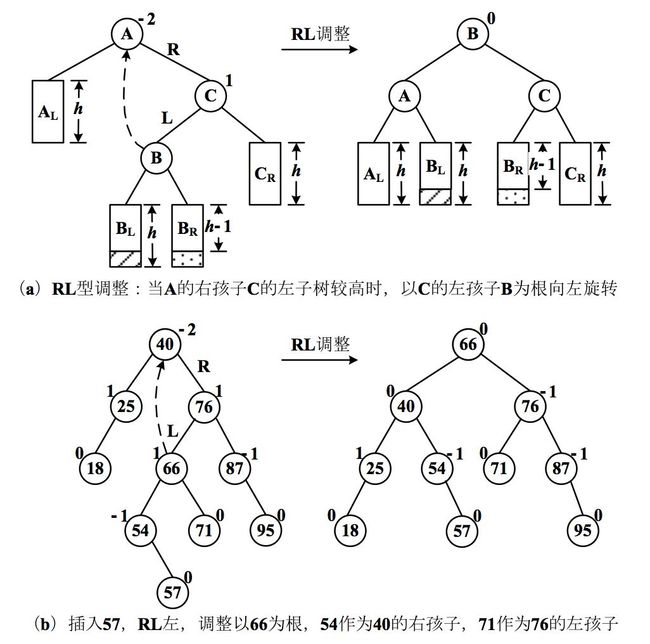
另外,若真有感兴趣的小伙伴,可以打开下面的链接去旋转,有动画的旋转。
https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
虽然平衡二叉树比排序二叉树多了一个自平衡功能,可以使二叉树的高度降低,提升查询效率。
不过这个存储结构在面对大数据量存储的时候,只能分两叉,那么二叉树的高度势必会越来越高,查询效率会越来越低,地基决定了高层建筑,那该怎么办?
只见 B-Tree 已经向我们招手,不过还是先看看二叉树的存储吧。
06. 二叉树的存储结构?
面对二叉树的存储,首先能想到的,便是将一棵完全二叉树的所有结点,按结点序号进行顺序存储的结构。
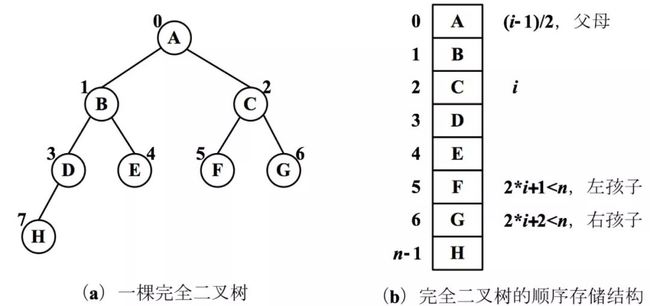
如图所示,逐个对完全二叉树的结点按照从上到下,从左到右的顺序进行编号,然后进行顺序存储后的结构图。
那么,对于一般的非完全二叉树,就需要通过补充空子树的方法,先将一棵二叉树变成完全二叉树,然后再进行顺序存储。
聪明的你,肯定会想到「补充空子树,存储空间会浪费很多,不太可行」,那该怎么办呢?
于是就改变设计,采用两条链分别连接左、右孩子,每个结点有三个域:data 存储数据元素,left、right 分别指向左、右孩子结点,结构如下。
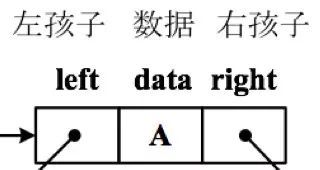
下图(a)示意了一棵 8 个结点的二叉树,对应的二叉链表存储结构,如下图(b)所示,其中 root 指向二叉链表的根结点。

但是,聪明的你肯定又会发现「采用二叉链表存储二叉树,只保存了结点到孩子结点的单向关系,而没有存储结点到父结点的关系,所以要想获得父结点,需要从根结点开始在二叉树中进行查找,那么花费的时间会较多」,那该怎么办呢?

于是,在二叉链表的基础之上,三叉链表增加一条链 parent 连接父母结点,如上图示意,这样就存储了父母结点与孩子结点的双向关系。
结论:二叉树的存储结构可以分为顺序存储和链式存储(二叉链表、三叉链表),另外二叉树通常采用链式存储结构。
07. B-Tree
B-Tree 又是啥树?
B-Tree 是多路搜索树,并不是二叉的树,是一种常见的数据结构。使用 B-Tree 结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度 —— 来自百度百科。
B-Tree 使用的场景?
1. B-Tree 索引是数据库中存取和查找记录的一种方法;
2. B-Tree 利用多个分支(称为子树)的结点,减少获取记录时所经历的结点数,从而达到节省存取时间的目的。

B-Tree 每层都存放大量的数据,这样树的高度会低,而且能够快速定位数据所在的位置,假如查找「一猿小讲」那么查询路径如下。

但是这样也存在,地基决定高层建筑的问题。由于数据存放在每层,那么范围查询虽然能支持,遍历树比较而已,但是查询起来应该相当繁琐;而且数据量较大时,也会增大查询时的磁盘 I/O 次数,进而也会影响查询效率。那该怎么办?
你看远方,B+Tree 已在向我们招手!
08. B+Tree
B+Tree 是在 B-Tree 基础上的一种改进,像 MySQL、SQLite 等数据库都使用了 B+Tree 算法来处理索引。原来重量级的「树」在这儿候着呢。
我们把同样的数据用 B+Tree 结构存一下,看看与 B-Tree 有什么不同?

蓦然发现,在 B+Tree 中与 B-Tree 明显的不同的是:所有数据都会存放在同一层的叶子节点上;并且叶子节点这层还有指向后面的指针。
这么一来,B+Tree 就能很好地进行范围查询,定位数据后,直接就可以用叶子节点那层的指针遍历了;另外也可以从根结点开始,随机查询啦。
09. 心中有「树」
平时业务研发中,很少去纠结「树」,而且这玩意看过也会忘,不过要知道「面试造火箭,入职拧螺丝」,所以建议还是多下点功夫。
当时数据结构这门课拿了快满分,那都是 10 年前的事啦。不过今天重拾一下,感觉记忆又回来啦。
最后,懂与不懂,建议都转发收藏,因为随着时间的推移,年龄的增长,我们不懂的东西会越来越少。
