NVIDIA官网提供四大类的帮助文档,其中本文以这四类为基础提供有可能在高性能计算上使用的library。
1. CUDA Toolkit Documentation
==========================
1.1 AmgX
AmgX提供了一个简单路径来加速对英伟达 GPU核心solver技术。它是一种高性能、以及包括柔性 state-of-the-art函数库求解器的组合系统 ,用户可以轻松地构建复杂的嵌套迭代法求解等。AmgX库提供很多优化方法,灵活地选择solver的构造方法,而且通过基于C的并行API来加速。通过使用AmgX库的method和tool,开发者能够很容易地创建指定的solver。
1.2 cuDNN
NVIDIA CUDA Deep Neural Network library(cuDNN)原始是一个为深度神经网络(deep neuralnetworks)的GPU加速库。它强调性能、易用性和低内存开销。NVIDIAcuDNN可以集成到更高级别的机器学习框架中,如加州大学伯克利分校的流行CAFFE软件。简单的,插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是调整性能,同时还可以在GPU上实现高性能现代并行计算。
1.3 cuFFT
NVIDIA CUDA Fast Fourier Transform library(cuFFT) 可提供一个简单的接口,让计算 FFT的速度最高提升 10 倍。 通过利用英伟达 GPU 中数以百计的处理器核心,cuFFT让开发者无需开发自己的定制 GPU FFT 软件,即可实现 GPU 的浮点性能。
1.4 NPP
NVIDIA Performance Primitives library (NPP)是一系列 GPU 加速的图像、视频以及信号处理函数,与同级别的纯 CPU函数相比,这些函数最高可实现 5 - 10 倍性能提升。 利用 NPP,开发者能够利用 (CUDA4.1 中) 2000多个图像处理与信号处理基元,在数小时之内即可实现应用程序的大幅性能提升。
无论用 GPU 加速的版本代替 CPU 基元还是将 NPP 基元与现有的 GPU加速流水线相结合,NPP 都能够实现极高的性能,同时可缩短开发时间。
1.5 CHOLMOD
CHOLMOD是一个针对sparse Choleskyfactorization的高性能库,CHOLMOD是线性代数SuiteSparse包的一部分,在工业界和学术界已经非常普遍的使用SuiteSparse和CHOLMOD。
1.6 cuBLAS-XT
cuBLAS-XT是一款 GPU 加速版本的完整标准BLAS 库,与最新的 MKL BLAS 相比,可实现 6 - 17 倍性能提升。CULA Tools 和 MAGMA等异构 LAPACK 库是在 cuBLAS 库中 GPU 加速 BLAS例程的基础上开发的,因而开发者也能够使用到这些内容。
1.7 CULA
CULA是一个基于GPU加速的线性代数库,其利用CUDA并行计算框架来提升对复杂的数学运算速度。因为它不需要cuda编程经验,所以CULA很容易使用。CULA有三个版本:Basic, Premium,Commercial。每个版本提供的功能、特性和支持都不相同。
1.8 MAGMA
MAGMA是下一代线性代数例程的一个合集。这些例程专为异构 GPU 架构而设计。 支持当前的 LAPACK 和 BLAS 标准。
1.9 IMSL
IMSL Fortran Numerical Library是由RogueWave 开发,能够将计算工作移交给 GPU 的一套广泛的数学与统计函数。
1.10 cuSPARSE
[CUDA Sparse Matrix library(https://developer.nvidia.com/cusparse) (cuSPARSE)可提供一整套用于稀疏矩阵的基本线性代数子例程,这些子例程与最新的 MKL相比最高可实现 8 倍性能提升。 cuSPARSE 库的设计目的是让开发者从 C 或 C++进行调用,最新版本包含一个稀疏三角解算器。
1.11 cuRAND
[CUDA Random Number Generation library(https://developer.nvidia.com/curand)(cuRAND) 可执行高质量的 GPU 加速随机数字生成任务,比仅使用 CPU 的一般代码快 8倍以上。
1.12 Thrust
Thrust是一款功能强大且开放源码的库,其中包含了诸多并行算法和数据结构。只需区区几行代码即可执行GPU加速的排序、扫描、转换以及约减等操作。
1.13 NVBIO
NVBIO是一款基于C++框架的GPU加速库,其能够对短和长读一致性进行高吞吐量的序列分析,并且其模块库中包含数据结构、算法和使用的应用程序。通过NVBIO可以在CPU-GPU和CPU-only上建立复杂的计算基因组学。
2. NVIDIA GameWorks Documentation
==============================
2.1 GameWorks Library
NVAPI是NVIDIA的core软件开发kit,通过其可以直接访问NVIDIA的GPU和驱动,但其只能在
Microsoft Windows平台。NVIAPI提供的功能包括如下:
Driver Management: Initialization and driver version controls.
GPU Management: Enumeration of physical and logical GPUs. Thermal and
Cooling controls.Display Management: Enumeration of NVDIA displays, display postion and
timings controls.System Management: Ability to query chipset and system specific
information.Connecting and Configuring Monitors: Ability to set views on multiple
target monitors.
其中与高性能计算有关的API是在GPU APIs子目录下的GPU Performance State
Interface。
2.2 Developer Tools
NVIDIA Developer
Tools根据在不同平台的开发需要,提供了三种工具,分别是:
NVIDIA Nsight Visual Studio Edition:适用于windows平台;
Linux Graphics Debugger:显然是适用于Linux平台;
Mobile Developer Tools:适用于移动开发。
2.3 SLI
SLI是Scalable
Link
Interface的缩写,是一种多GPU配置结构,其通过增加多个GPU负载来提高表现性能。对于拥有多个GPU的计算机可能应用这种技术可以提供相应的性能。其中SLI拥有如下的五种模型,具体内容可以参考NVIDIA官网。
Alternate Frame Rendering (AFR)
Split Frame Rendering (SFR)
Boost Performance Hybrid SLI
SLIAA
Compatibility mode
3. GPU Management & Deployment Documentation
=========================================
3.1 NVML API
NVIDIA Management Library
(NVML)是一个基于C的接口库,通过其可以管理和监控GPU的多种状态,并且NVML在多线程编程中是一种线程安全的调用。
- 支持的操作系统
Windows: Windows Server 2008 R2 64-bit, Windows Server 2012 R2 64bit,
Windows 7-8 64-bitLinux: 32-bit and 64-bit
- 支持的产品
Full Support
NVIDIA Tesla Line:
S2050, C2050, C2070, C2075,
M2050, M2070, M2075, M2090,
X2070, X2090,
K8, K10, K20, K20X, K20Xm, K20c, K20m, K20s, K40c, K40m, K40t, K40s, K40st,
K40d, K80NVIDIA Quadro Line:
410, 600, 2000, 4000, 5000, 6000, 7000, M2070-Q
K2000, K2000D, K4000, K5000, K6000
NVIDIA GRID Line:
K1, K2, K340, K520
NVIDIA GeForce Line: None
Limited Support
NVIDIA Tesla Line: S1070, C1060, M1060 and all other previous generation
Tesla-branded partsNVIDIA Quadro Line: All other current and previous generation Quadro-branded
partsNVIDIA GeForce Line: All current and previous generation GeForce-branded
parts
- 相关API
NVML API可以分为五类:
Support Methods:
Initialization and Cleanup
Query Methods:
System Queries
Device Queries
Unit Queries
Control Methods:
Unit Commands
Device Commands
Event Handling Methods:
Event Handling Methods
Error reporting Methods
Error Reporting
其中本文将与高性能计算有关的API列在表中。
表 1
| method | Description |
|---|---|
| nvmlDeviceGetAPIRestriction | 查询指定API的root/admin权限。 |
| nvmlDeviceGetAutoBoostedClocksEnabled | 查询当前auto boosted clocks的状态,auto boosted clocks允许在理论值条件下运行比较高的时钟频率,从而最大率的提供性能。 |
| nvmlDeviceGetBrand | 查询设备的型号。 |
| nvmlDeviceGetClockInfo | 查询当前设备的时钟频率。 |
| nvmlDeviceGetComputeRunningProcesses | 查询运行状态的进程数量,返回的信息是动态变化的。 |
| nvmlDeviceGetCount | 查询当前系统中GPU的数量。 |
| nvmlDeviceGetDecoderUtilization | 查询Decoder的当前的使用率。 |
| nvmlDeviceGetEncoderUtilization | 查询Encoder的当前的使用率。 |
| nvmlDeviceGetFanSpeed | 查询设备的fan速。 |
| nvmlDeviceGetGraphicsRunningProcesses | 查询当前设备上下文的与graphics有关的进程。 |
| nvmlDeviceGetMaxClockInfo | 查询设备的最大时钟频率。 |
| nvmlDeviceGetMemoryInfo | 查询设备上已被使用、可被使用和总共的存储空间数量。 |
| nvmlDeviceGetMinorNumber | 查询设备的minor数量, |
| nvmlDeviceGetMultiGpuBoard | 查询主板是否支持多GPU。 |
| nvmlDeviceGetPerformanceState | 查询当前设备的性能状态。 |
| nvmlDeviceGetPersistenceMode | 查询当前设备的持久化模型。 |
| nvmlDeviceGetSupportedMemoryClocks | 查询可以使用的memory时钟。 |
| nvmlDeviceGetTemperature | 查询当前设备的温度。 |
| nvmlDeviceGetTemperatureThreshold | 查询设备的温度极限。 |
| nvmlDeviceGetUtilizationRates | 查询设备主要子系统的当前利用率。 |
| nvmlDeviceResetApplicationsClocks | 重置设备的应用时钟。 |
| nvmlUnitGetCount | 查询系统的units数量。 |
| nvmlUnitGetFanSpeedInfo | 查询unit的fan速。 |
| nvmlDeviceSetAPIRestriction | 改变root/admin对指定API的限制。 |
| nvmlDeviceSetComputeMode | 设置设备的计算模型。 |
| nvmlDeviceSetDriverModel | 设置设备的驱动模型。 |
| nvmlDeviceSetPersistenceMode | 设置设备的持久化模型。 |
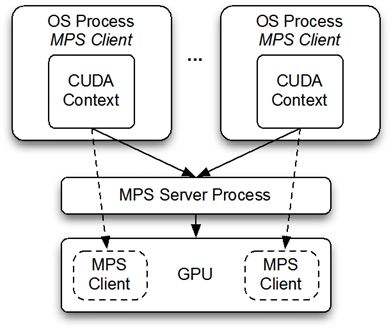
3.2 Multi-Process Service
Multi-Process Service
(MPS)是一个可选的、二进制兼容的CUDA
API实现。MPS运行框架的设计是为了支持交互式的多进程CUDA应用程序,特别是MPI工作,并且为了在最新版本的GPU上利用Hyper-Q能力。Hyper-Q允许CUDA核函数能在同一块GPU设备上并发执行,这样可以提供GPU的计算性能。如图
1所示。