本篇由两个部分组成:
一概述默认信用风险的区别与联系;
- Z计分模型用最简单的线性模型计算分数的阈值区间,判断企业违约的可能性。
- Credit Risk+模型用来猜想预期损失是多少,核心思想是计算泊松分布,推断银行应该准备多少准备金(预期损失),对非预期对损失心中有数。
- KMV模型是计算违约可能性,核心思想是计算违约距离判断其可能性。
- Credit Metrics模型是当“损失也知道了”,“违约可能性也知道”情况下,根据信用评价,推算未来(1年或者多年)损失当情况。
二神经网络如何和信用风险评估做补充。
信用风险由两个部分组成:
一是借款人不愿或者无力承担约定款项而违约导致损失的可能性;
二是由于借款人信用评级的变化引起信用价差的变化而导致损失的可能性。
一、四大信用风险评估模型
1、Z计分模型
得到Z值(经过各种数理统计后得到5个变量并确定相关系数的一个著名5变量模型,Z = 0.012 * X1 + 0.014 * X2 + 0.033 * X3 + 0.006 * X4 + 0.999 * X5)来判定企业经营的状况(违约或破产的可能性)。阿尔特曼经过统计分析和计算最后确定了借款人违约的临界值Zo=2.675。如果Z<2.675,借款人被划入违约组;反之,如果Z≥2.675,则借款人被划入非违约组。当1.81
优点:
(1)由Z评分模型所计算出的z值可以较为明确地反映借款人(企业)在一定时期内的信用状况(违约或不违约、破产或不破产),因此,他可以作为借款人经营前景好坏的早期预警系统。
(2)便捷性,只要通过财务数据的分析就可以得到该公司的风险状况,成为当代预测企业违约或破产的核心分析方法之一。
局限性:
(1)该模型缺少对市场数据的分析使该模型的预测结果存在滞后性,不能及时反映评价公司的信用变化。
(2)该模型仅考虑了两个比较极端的情况(违约与不违约),而对于负债重整或是虽然发生违约但是回收率很高的情况就没有做另外较详细的分类。
(3)该模型的理论基础不强,比如为什么这几个财变量值得考虑而另外一些因素则不值得考虑。虽然该模型在实证上得到了一定的支持,但是并不能在理论上给出合理的解释。
(4)权数显然不是固定的,必须经常调整。就算调整,那又该多长时间调整,调整的频率如何确定这些问题模型本身无法给出合理的答案。同时这种调整需要较大的数据库作为支撑,而这又是一件很费时效的工作。
(5)该模型没有考虑系统性风险的影响,该模型根本无法预测像2008年的金融危机这样的系统风险,而这种危机显然会对企业的违约率造成不同程度的影响。
优化策略:
(1)z值的判断范围
在不改变相关指标系数的前提下,根据不同行业的经营环境对Z值的判断范围进行调整,确定在一段时期内适用的判断范围。这样就能充分考虑不同行业的风险水平。调整思路为:①研究样本选取。选取一定数量的“财务危机 ”企 业和与之相对应的同样数量的 “正常 ”企业作为研究总样本 。②给样本组财务状况预警得打分 ,即 Z值。然后排序并选择分割点 ,确 定Z临界值,设置预 警区间 。将样本组企业标准化后的财务指标得到的各主成分的数据,再根据改进后预警函数模型计算得到企业财务状况的预警分值 。对预警分值按从高到低进行排序 。③ 用样本组企业检验修正预警模型的有效程度 。对上述从估计样本组企业财务数据进行检验,得出测试样本组企业的正确预测率 ,从而评价修改后的财务预警模型的预测能力。
(2)对财务指标进行调整
X4指标应改为总资产现金回收率,即经营现金净流量/资产总额 ;同时,剔除X5指标 。因为对中国而言,经营现金净流量比股价和销售收入更能真实客观的反映企业资产的质量、周转情况以及现金偿债能力。这样可以避免我国由于受股价异常变动或者虚假的报表信而使预测结果不够准确的情况,而剔 除X5指标是因为不同行业的资产周转率相差较大。这样做可以使预测结果受行业影响降至最低,从而增强了Z计分模型的适用性,能更好的发挥其财务预警的作用 。
2、Credit Risk+
得到贷款组合的预期损失分布(由各频段级贷款违约数量的概率分布和违约损失的概率分布得到)。
Credit Risk+模型属于信用违约风险度量模型,因为它仅仅考虑了违约风险,而没有考虑信用等级降级风险。
优点:
(1)传统的模型一般都是单期、单因素模型,而CreditRisk+模型可以扩展到多期(即组合)。
(2)违约率可看作是许多背景因素综合作用的结果,可以用随机变量Xk来表示,每个债务人的平均违约率可以作是背景因素Xk的线性函数,这些因素是相互独立的。
(3)需要的输入信息简单,很容易计算边际风险贡献
局限性:
(1)每个债务的敞口固定不变,不依赖于发行人信用质量的最终变化和利率的变化而变化
(2)这一模型不能处理非线性产品。
优化策略:
(1)违约损失率
违约损失率的大小直接表现为违约时各笔贷款损失程度的高低。Credit Risk+假定违约损失率为常数,但它其实容易受到宏观经济波动的影响。所以在现有研究中,对贷款违约率的估计往往是先采用历史数据,测量出同种贷款的历史平均违约损失率的均值与方差,然后假定贷款的违约损失率服从某一偏峰厚尾的分布,通常假定其服从Beta分布,对数正态分布等,在此基础上,确定每笔贷款违约损失率的分布。
3、KMV
得到公司的预期违约概率EDF(股权价值VE、股权收益率波动率σE——>资产价值VA、资产收益率波动率σA——>违约距离DD——>预期违约概率EDF)。这是一个动态模型,采用的主要是股票市场的数据。
KMV模型属于违约法,即在贷款期限内,信贷资产损失的计量取决于是否发生违约。因此信贷资产的损失要么是零(未发生违约),要么是贷款面值与可能回收价值的现值之差(发生违约),公司股价和资产负债表中的数据能够被诠释为隐含的违约风险。
优点:
(1)KMV 是一种动态的模型,可以及时反映信用风险的变化。上市公司的股价每个交易日都发生变化,且每季度公布财务报表。KMV可以据此更新模型的输入参数,及时反映市场预期。
(2)KMV是一种前瞻性的模型,克服了依赖历史数据向后看的数理统计模型(历史变化可以在未来重现)的缺陷。EDF来自于对股票价格的实时分析,股价不仅反映了该企业历史和当前的发展状况,还反映了投资者对该企业信用状况未来发展趋势的判断。
(3)EDF指标在本质上是一种对风险的基数衡量法。序数衡量法只能反映企业间信用风险的高低顺序,如BB级高于B级,不能明确说明高到什么程度。而基数衡量法不仅可以反映风险水平的高低顺序,而且可以反映风险水平差异的程度,因而更加准确。
局限性:
(1)KMV适用于对上市公司的信用风险进行评估,而对非上市公司进行评估则会遇到困难。
(2)EDP的计算给予企业资产价值服从正态分布的假设。但在现实中,并非所有借款企业的资产价值都服从正态分布。
(3)KMV无法分辨长期债务的不同类型。如果不区分长期债务的类别:优先偿还顺序、是否担保、是否可转化,可能造成违约点的计算不准确。
(4)KMV没有考虑税收的影响。负债可以带来抵税的好处,增加企业的价值,因此在为负债企业估值时,应该把抵税效果考虑进去。
优化策略:
(1)违约点DPT
kmv公司根据经验将违约点设在dp=sd+0.5ld,国内学者普遍认为不适合中国国情。中国上市公司失信状况比较严重,违约点的设定应提高。在将违约点设为公司债务函数的研究中,出现了各种尝试:
A、主观设定一个固定违约点,通常高于kmv模型违约点。如张智梅和章仁俊设定违约点dp=sd+0.75ld。这种方法主观性较强,未充分论证违约点设定的理论依据,因此略显粗糙。
B、主观设立多个固定的违约点,通过实证研究选择使样本的违约组和非违约组违约概率差异最大的违约点。如张玲、杨贞柿、陈收设立了三个违约点进行对比:sd、sd+0.5ld、sd+0.75ld,结果表明违约点设在最高的sd+0.75ld时模型的信用风险差异识别能力最强,设在最低的时识别能力最差[13]。赵建卫按长期负债等差变化设立了五个违约点,分别是sd、sd+0.25ld、sd+0.5ld、sd+0.75ld、sd+ld,实证结果表明五个违约点中最高的违约点使kmv模型最有效[14]。从这些研究者的结论来看,在中国违约点的设定应明显高于kmv公司的经验违约点,从实证上支撑了中国失信状况严重的理论预期。
C、在一定范围内改变短期负债和长期负债的系数组合,尝试各种匹配下的模型效果。如李磊宁、张凯设违约点为dp=sd+mld,0≤m≤1,m在取值范围内以0.1为步长,共设定了11个违约点,但其结论显示只有当m为0.1和0.2时模型才能通过显著性检验,在两者之中又以m=0.1效果略好,这个结论显示中国的违约点较低,与中国失信严重的理论预期有一定差异[15]。
D、章文芳、吴丽美、崔小岩设定违约点为dp=ald+bsd,采用穷举法在(a,b)=[(0,0),(10,10)]的正方形内尝试,在考察期内,如果公司资产价值撞击违约点和公司随后被st处理的事件没有同时发生即为错判,用最小错判法寻求最优的参数组合(a,b),最终测定dp=1.2ld+3.05sd时错判率最低,正确率最高,并将此违约点与kmv公司的经验违约点sd+0.5ld的模型效果做了对比,表明kmv公司的违约点测出的st和非st公司的违约距离都大于0,用来度量中国公司的违约情况失效,而新违约点只有非st公司的违约距离大于0,与实际符合。
(2)违约距离DD
计算违约距离dd时使用了公司的预期资产价值,部分学者对资产的预期增长率进行了研究。李磊宁和张凯用公司近三年净收益增长率的算术平均值近似预期增长率。笔者认为,公司资产的增长率在实际中随时间而变化,尤其对违约公司,在从正常状态发展到违约的过程中,理论上应该是增长率下降甚至负增长,因此简单假定资产的预期增长率为零显然会对计算结果造成误差。
关于这些模型所用到的特征参数的调优论文还有很多,比如说使用遗传算法对违约触发点的进一步选择优化来提高KMV模型的准确率、或者使用BP-神经网络处理国内的一些未上市公司的财政报告中的特征并融合到KMV模型来对国内未上市公司的预测违约率。
4、Credit Metrics
得到VaR(在某一给定的置信水平下,资产组合在未来特定的一段时间内可能遭受的最大损失)。Credit Metrics不仅考虑了违约风险(违约回收率)还考虑了信用等级降级风险(远期折现率、信用等级转化矩阵)。
CreditMetrics模型属于盯市法,即信贷资产的市值直接受借款人的信用等级及其变化情况的影响,即使是借款人并未违约,只要信用等级降低,信贷资产的价值也相应降低,这样合理反映了信贷资产在违约发生前其价值潜在的损失状况。
优点:
(1)运用该模型可以定量描述某一信用敞口对风险的边际贡献,从而判断是否将该敞口引入组合,提高识别、衡量和管理风险的能力
(2)可以迫使银行收集信息,更明确地确定限额,更精确地基于风险和绩效进行评价,使银行的经济资本分配更合理;可以更好地对客户进行盈利分析,基于风险进行定价,更好地做好组合管理。
局限性:
(1)所有的预测和计算都以信用等级转移概率、违约概率为基础的,这两个历史统计数据库的可能性引起了一些专家的质疑。
(2)只要处于同一等级,所有企业的违约率都一样。
(3)实际违约率等于历史平均违约率。
(4)信用等级等同于信贷质量,信用等级与违约率是同义词,对担保因素考虑不够。
(5)信用等级的变化是独立的。这一假设存在一定问题,因为贷后的等级变化具有关联性,在同一行业、同一地区的企业,关联性大一些。在经济萧条时期,贷款的信用价
值普遍变小,信用等级普遍变低,不同贷款的变化方向一致。
优化策略:
(1)构造企业信用等级动态变化矩阵
以原有的AAA、AA、A、BBB、BB、B、CCC 七个等级分别为纵轴和横轴建立基础企业信用等级动态变化矩阵。一方面, 将原来的各等级静态的系数, 转化为动态变化的数据,使最终的风险值也处于随时变化的状态, 精确风险防范; 另一方面, 以客观历史数据为基础, 最大剔除原有系数中的人为主观干扰, 保证模型的客观性。
(2)构造贷款形态损失率矩阵
贷款的不同形态给银行带来的风险主要是银行花费在该款项上的管理成本和用于再投资的机会收益的损失上。 因此,单一的各等级( 正常贷款、逾期贷款、呆滞贷款和呆账贷款)的风险系数不能将损失状况表现清楚。 通过公式:

Ri——各等级下第 i 类贷款的损失变化率; ri——第i类贷款的利率收益; Ii——第 i 类贷款的投资收益; ci——第i类贷款的管理成本 ; Rar——各等级间的等级 变化风险值 , 如 , 正常贷款→逾期贷款风险值为 1.5, 逾期贷款→呆滞贷款风险值为2,呆滞贷款→呆账贷款风险值为 2.5.这样, 就能得出各类贷款当其贷款形态发生变化的时候的损失程度。由于我国银行的呆坏账占信贷的比例较大, 不能仅仅计算正常贷款下信用风险的变动, 还需要计算逾期、呆、滞账款的风险和损失 , 才能真实反映银行信贷的真实信用风险程度。保留和改进贷款形态因子正是出于对我国银行实际情况的考虑。
二、基于BP神经网络的信用风险评估模型
1、BP神经网络在信用风险评估应用的优势及可行性分析
(1)BP神经网络有自学习和自适应能力,简单来说是向环境获取知识学习并改进自身性能。内部有大量的可调参数,因此使系统灵活性更强。
(2)BP神经网络实质上是输入到输出的映射,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性映射关系。我国的个人信用等级评估起步比较迟,相关信息残缺不全。BP网络逼近任意非线性映射关系的能力对于解决几乎没有规则、多约束条件或数据不完全的问题是非常适合的。
(3)BP神经网络的后天学习能力使之能够随环境的变化而不断学习。在进行信用等级评估与预测时,受到评估数据带有模糊性的特点制约,能够从未知模式的大量复杂数据中发现规律,与传统的评价方法相比,表现出更强的功能。
(4)BP神经网络方法是一种自然的非线性建模过程。它克服了传统分析过程的复杂性及选择适当模型函数形式的困难,无需分清存在何种非线性关系,给建立模型与分析带来了极大的方便。
(4)BP神经网络方法较好地保证了评估与预测结果的客观性。在传统的个人信用风险评估中,大部分的决定因素是信贷员个人主观的判断,而BP神经网络可以再现专家的经验、知识和直觉思维,较好地保证了评估与预测结果的客观性。
2、案例运用
先选择模型指标参数并取值(归一化至[0,1])作为样本数据,如下图,然后通过BP网络来训练并对训练生成的的神经网络模型的预测结果进行验证。

模型构建:
设计了三层神经网络模拟信用风险评估过程,其中,输入层节点数为3,分别对应信用风险评估选择的3个指标:收入、存款、失信;隐层节点数为4;输出层节点数为1,其输出值为模型预测信用额度。
BP网络训练的流程:
有监督学习,包括前向传播和反向传播。即在(0,1)范围内先初始化连接权和阈值,然后训练样本,得到模型输出结果后更新连接权和阈值(链式求导)使得损失函数最小化(均方误差最小)。具体如下:

代码:
import pandas as pd
import numpy as np
data_dict = {
"序号": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27],
"收入指标": [1, 1, 1, 1, 1, 1, 1, 1, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 1, 0.5],
"存款指标": [1, 1, 0.5, 0.5, 0.1, 0.1, 0.5, 0.1, 1, 1, 0.5, 0.5, 1, 0.1, 0.1, 0.1, 1, 0.5, 1, 0.5, 0.1, 0.1, 0.5, 0.1,
1, 1, 0.1],
"失信指标": [1, 0.1, 1, 0.1, 1, 0.1, 0.5, 0.5, 1, 0.1, 1, 0.5, 0.5, 0.5, 0.5, 0.1, 1, 1, 0.5, 0.5, 1, 0.1, 0.1, 0.5,
0.1, 0.5, 0.1],
"信用额度": [1, 0.8, 0.8, 0.6, 0.8, 0.4, 0.6, 0.6, 0.8, 0.6, 0.6, 0.4, 0.6, 0.4, 0.4, 0.2, 0.8, 0.6, 0.6, 0.4, 0.4, 0.2,
0.2, 0.2, 0.4, 0.8, 0.6]
}
dataset_df = pd.DataFrame(data_dict)
del dataset_df['序号']
dataset = dataset_df
dataset = np.array(dataset)
m, n = np.shape(dataset)
trueY = dataset[:, 0]
X = dataset[:, 1:]
m, n = np.shape(X)#(27,3)
# 初始化参数
import random
d = n # 输入向量的维数
l = 1 # 输出向量的维数
q = d+1 # 隐层节点的数量,这里用的是d+1,这个个数目前没有定论,通常是靠试错法来决定,几个结点表现好,就用几个
theta = [random.random() for i in range(l)] # 输出神经元的阈值
gamma = [random.random() for i in range(q)] # 隐层神经元的阈值
# v size= d*q .输入和隐层神经元之间的连接权重
v = [[random.random() for i in range(q)] for j in range(d)]
# w size= q*l .隐藏和输出神经元之间的连接权重
w = [[random.random() for i in range(l)] for j in range(q)]
eta = 0.5 # 训练速度
maxIter = 80000 # 最大训练次数
import math
def sigmoid(iX,dimension): # 激活函数,iX is a matrix with a dimension
if dimension == 1:
for i in range(len(iX)):
iX[i] = 1 / (1 + math.exp(-iX[i]))
else:
for i in range(len(iX)):
iX[i] = sigmoid(iX[i], dimension-1)
return iX
# 标准BP
while(maxIter > 0):
maxIter -= 1
sumE = 0# 累计误差
# 对于每一个样本,更新
for i in range(m):
# 1计算当前样本的输出
alpha = np.dot(X[i], v) # 隐层神经元的输入,1*d·d*q=1*q
b = sigmoid(alpha-gamma, 1) # 隐层神经元的输出b=f(alpha-gamma),1*q
beta = np.dot(b, w) # 输出层神经元的输入,1*l
predictY = sigmoid(beta-theta, 1) # 输出层神经元的预测输出,1*l,p102--5.3
E = sum((predictY-trueY[i]) * (predictY-trueY[i])) / 2 # 均方误差,p102--5.4
sumE += E # 累计误差,多个样本(xi,yi)p104--5.16
# 2计算当前样本的输出层神经元梯度项、隐层神经元梯度项
g = predictY * (1-predictY) * (trueY[i]-predictY) # 输出层神经元梯度项,1*l,p103--5.10
e = b * (1 - b) * ((np.dot(w, g.T)).T) # 隐层神经元梯度项,1*q,p104--5.15
# 3更新连接权和阈值
w += eta*np.dot(b.reshape((q, 1)), g.reshape((1, l))) # w更新,q*1·1*l=q*l,p104--5.11
theta -= eta*g # theta更新,p104--5.12
v += eta*np.dot(X[i].reshape((d, 1)), e.reshape((1, q))) # v更新,d*1·1*q=d*q,p104--5.13
gamma -= eta*e # gamma更新,p104--5.14
# print(sumE)
def predict(iX):
alpha = np.dot(iX, v) # m*q
b = sigmoid(alpha- gamma, 2) # b=f(alpha-gamma),m*q
beta = np.dot(b, w) # m*q·q*l=m*l
predictY = sigmoid(beta - theta, 2) # m*l
return predictY
result = predict(X)
compare = np.concatenate((result, true_Y),axis=1)
compare = pd.DataFrame(compare)
print(compare)
结果输出(左边为模型预测结果,右边为真实结果):
0 1
0 0.953519 1.0
1 0.815795 0.8
2 0.820138 0.8
3 0.554622 0.6
4 0.787117 0.8
5 0.440197 0.4
6 0.646845 0.6
7 0.576809 0.6
8 0.834012 0.8
9 0.589760 0.6
10 0.585079 0.6
11 0.400388 0.4
12 0.584876 0.6
13 0.392659 0.4
14 0.392659 0.4
15 0.398677 0.2
16 0.816912 0.8
17 0.607129 0.6
18 0.614901 0.6
19 0.382922 0.4
20 0.395699 0.4
21 0.199170 0.2
22 0.244092 0.2
23 0.243235 0.2
24 0.396517 0.4
25 0.808622 0.8
26 0.398677 0.6
BP算法应用的优化策略:
(1)学习因子η的优化,采用变步长法根据输出误差大小自动调整学习因子,来减少迭代次数和加快收敛速度。
(2)隐层节点数的优化。当隐节点数太多时,会导致网络学习时间过长,甚至不能收敛;而当隐节点数过小时,网络的容错能力差。利用逐步回归分析法并进行参数的显著性检验来动态删除一些线性相关的隐节点。节点删除的标准:当由该节点出发指向下一层节点的所有权值和阀值均落在死区(通常取±0.1、 ±0.05等区间)之中,则该节点可删除。最佳隐节点数L可参考下面公式计算:
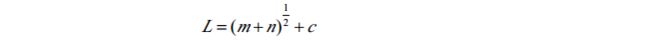
式中: m为输入节点数, n为输出节点数, c为介于1~10的常数。
(3)输入和输出神经元的确定。利用多元回归分析法对神经网络的输入参数进行处理,删除相关性强的输入参数,来减少输入节点数。