首先我们来看几个公式
variance公式:
covariance公式, 即:
当随机变量x和y相同时, covariance等同于variance:
如果协方差covariance等于0说明这两个随机变量不相关
协方差矩阵:
均值中心化(mean centering): 指得是将一系列的样本点的均值置0,也就是每个样本点的值减去所有样本点的均值, 这样新生成的所有样本点的均值即为0。
现在我们设z:
其中z的每一行都是mean centred后的特征向量feature vector, 此时, 之前的协方差矩阵就可表示为 (因为均值都变为0, 所以原来直接变为了x*y )
1. ****Principal axes of variation (变化主轴)
Principal axes of variation指的是对于高维数据而言, 变化率最显著的数据所在维度, 为了理解这一概念, 首先介绍基向量(basis)
一组基是由n维空间中n个线性独立的向量组成, 这些向量之间是垂直的, 它们构成了一个坐标系统, 而n维空间中有无限组基向量

**
**
第一主成分轴(****The first principal axis****):
第一主成分轴指的是对在n维空间中的数据点, 指向最大variance方向的轴
**
**
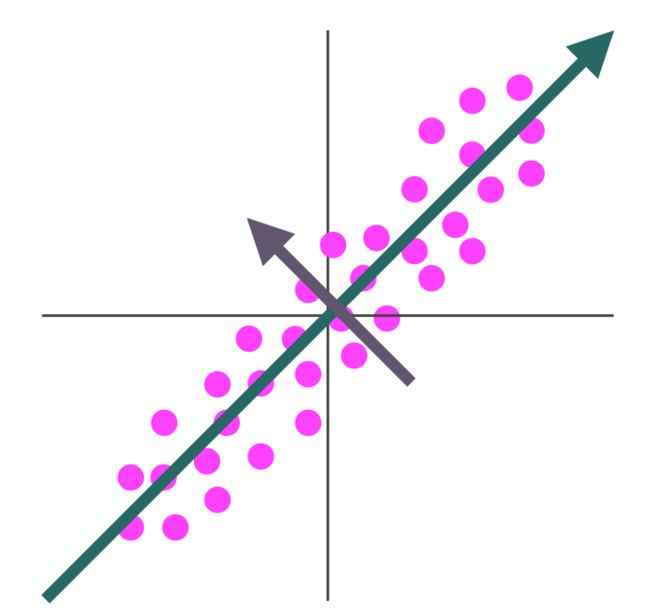
第二主成分轴是指垂直于第一主成分轴同时指向最大variance方向的轴
以此类推, 第三主成分轴是垂直于第一和第二的前提下, 指向有着最大variance的轴
2. ****特征向量和特征根
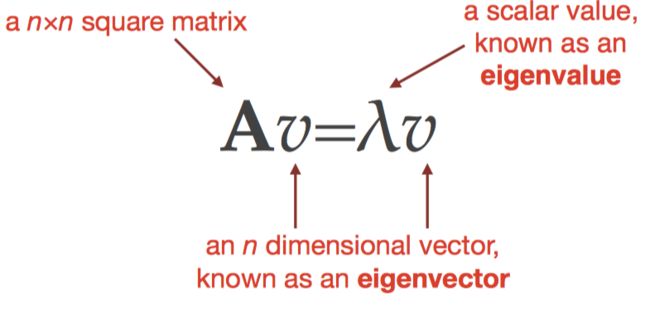
最多有n对 特征向量-特征根对
其中若A是对称矩阵(对于任何方形矩阵X,是对称矩阵)的话, 则特征向量的集合是正交的
如果A是协方差矩阵的话, 那这些特征根就是主成分坐标轴(principal axes)
对于的情况, 可以通过代数的方法解得特征根和特征方程。
但对于更大的矩阵, 就需要特征分解(Eigendecomposition,简写为EVD)了。
3. ****特征分解
特征值分解(EVD),在这里,选择一种特殊的矩阵——对称阵(酉空间中叫hermite矩阵即厄米阵)。对称阵有一个性质:它总能相似对角化,对称阵不同特征值对应的特征向量两两正交。一个矩阵能相似对角化即说明其特征子空间即为其列空间,若不能对角化则其特征子空间为列空间的子空间。现在假设存在mxm的满秩对称矩阵A,它有m个不同的特征值,设特征值为,对应的单位特征向量为
则有:
将上面的式子用矩阵形式表示, 进而:
令式子两边各除以一个U, 则有(由于对称阵特征向量两两正交,所以U为正交阵,正交阵的逆矩阵等于其转置):
这里假设A有m个不同的特征值,实际上,只要A是对称阵其均有如上分解。

如果A是对称矩阵(譬如协方差矩阵), 此时 (即特征向量是正交的), 所以此时
将eigenvector和对应的eigenvalue排序, PCA取前k个
要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵:
因为这个矩阵M乘以一个向量(x,y)的结果是:
它其实对应的线性变换是下面的形式:

上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换, 当矩阵不是对称的时候,假如说矩阵是下面的样子:
它所描述的变换是下面的样子:
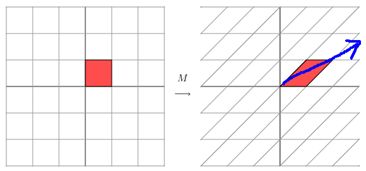
在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列), 当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。
总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么
4. ****PCA流程
输入:n维样本集,要降维到的维数n'.
输出:降维后的样本集
- 对所有的样本进行中心化:
- 计算样本的协方差矩阵, 注意, 协方差矩阵就等于
- 对矩阵进行特征值分解
- 取出最大的n'个特征值对应的特征向量, 将所有的特征向量标准化后,组成特征向量矩阵W。
- 对样本集中的每一个样本, 转化为新的样本
- 得到输出样本集
有时候,我们不指定降维后的n'的值,而是换种方式,指定一个降维到的主成分比重阈值t。这个阈值t在(0,1]之间。假如我们的n个特征值为, 则n'可以通过下式得到:
这里对PCA算法做一个总结。作为一个非监督学习的降维方法,它只需要特征值分解,就可以对数据进行压缩,去噪。因此在实际场景应用很广泛。为了克服PCA的一些缺点,出现了很多PCA的变种,比如第六节的为解决非线性降维的KPCA,还有解决内存限制的增量PCA方法Incremental PCA,以及解决稀疏数据降维的PCA方法Sparse PCA等。
PCA算法的主要优点有:
1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
2)各主成分之间正交,可消除原始数据成分间的相互影响的因素。
3)计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
2)方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
5. ****奇异值分解
奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵, 比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵, 此时即用到了奇异值分解, 奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
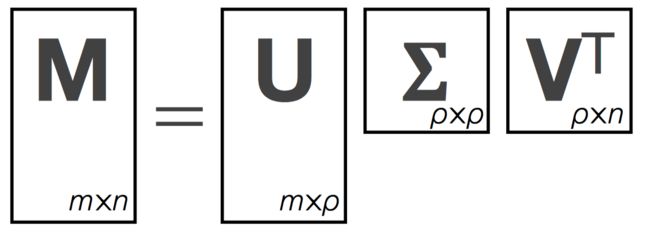
其中p是矩阵M的秩, 秩代表线性不相关的行或者列的数量
U是一个m * p的方阵(里面的向量是正交的,U里面的列向量称为左奇异向量),Σ是一个p * p的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个p * n的矩阵,里面的行向量也是正交的,V里面的向量称为右奇异向量。
左奇异向量集合是的特征向量集合
右奇异向量集合是的特征向量集合
The singular values are the square roots of the eigenvalues of the corresponding eigenvectors of and
如果M是mean centred的特征向量矩阵的话, V的列向量是的特征向量, 它们是M的主成分(principle components)。
那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵M的转置乘以M,将会得到一个方阵,我们用这个方阵求特征值可以得到:
这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量
奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
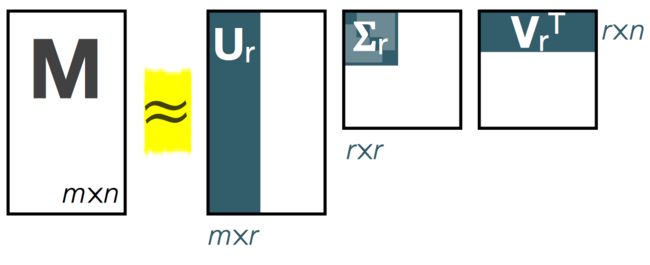
右边的三个矩阵相乘的结果将会是一个接近于M的矩阵,在这儿,r越接近于p,则相乘的结果越接近于M。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵M,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
SVD流程:

至于为什么要用基于SVD的PCA是因为:
计算可行性
SVD的速度比EVD更快
除此之外, SVD适用的场合有:
求伪逆(Pseudoinverse)
解homogeneous linear equations, 如Ax=0
数据挖掘: 如基于CF的推荐系统
SVD求伪逆的一个例子
A矩阵的伪逆代表其与A的乘积等于单位矩阵
我们来具体算一个矩阵A的伪逆:
易知,rank(A*A)=2。下面来求矩阵A*A的特征值,于是有
接下来求对应的特征向量,因为
所以可知当λ1=5时,对应的特征向量(注意结果要正交归一化):
同理还有当λ2=1时,对应的特征向量
如此便得到了SVD中需要的U矩阵
为了求出矩阵V,先求W:
于是可知
所以根据公式A的伪逆就是, 其中V*代表其转置矩阵
6. ****SVD和EVD的计算方法
普遍来说, 这些计算方法都是迭代的:
- Power Iteration
-Repeated for each E.V. by rotating and truncating the input to remove the effect of the previous E.V.
- “Arnoldi Iteration” and the “Lanczos Algorithm”
-Move efficient variants of Power Iteration
-use the “Gram-Schmidt” process to find the orthonormal basis of the top-r E.Vs