# 1.爬取作者信息(头像/昵称/性别/年龄)
# 2.帖子内容,好笑数,评论数
# 3.存入 csv
# 翻页处理方式
# 1.分开处理 一页一页处理 (例:爬取当前页后直接存储)
# 2.翻页到结束处理 从首页翻页到尾页 (例:翻页到尾页后统一处理)
import csv
import pymysql
import requests
from bs4 import BeautifulSoup
#爬取一页的内容
def qb_spider1(page=1):
url_temp = "https://www.qiushibaike.com/text/page/{}/".format(page)
#print(url_temp)
rep=requests.get(url=url_temp)
soup=BeautifulSoup(rep.text,"lxml")
articles = soup.find_all("div", class_='article')
article_infos = []
datas=[]
for article in articles:
author_div=article.find("div",class_="author")
author_img=article.img
author_icon=author_img.attrs['src']
author_icon="https:"+author_icon
author_name = author_img.attrs['alt']
if "匿名用户" not in author_name:
article_gender = author_div.div
author_age = article_gender.text.strip()
article_gender_class = article_gender.attrs['class']
author_gender="man" if "man" in article_gender_class else "woman"
else:
author_age = -1
author_gender = "no"
article_content = article.find("div", class_='content')
article_stats = article.find_all("i", class_='number')
#print(article_stats)
article_content = article_content.span.text.strip()
stats_vote = article_stats[0].text.strip()
stats_comment = article_stats[1].text.strip()
#双列表存储
article_info = [author_icon, author_name, author_gender, author_age, article_content, stats_vote, stats_comment]
article_infos.append(article_info)
#存入字典在存入列表
item={}
item['头像']=author_icon
item['用户名'] =author_name
item['性别'] =author_gender
item['年龄'] =author_age
item['段子'] =article_content
item['好笑数'] =stats_vote
item['评论'] =stats_comment
datas.append(item)
next_tag=soup.find('span',class_='next')
has_next=False
if next_tag is None:
has_next=False
else:
has_next=True
return datas,has_next
# 2.翻页到结束处理 从首页翻页到尾页 (例:翻页到尾页后统一处理)
def qb_spider2(page=1):
url_temp = "https://www.qiushibaike.com/text/page/{}/".format(page)
# print(url_temp)
rep = requests.get(url=url_temp)
soup = BeautifulSoup(rep.text, "lxml")
articles = soup.find_all("div", class_='article')
article_infos = []
for article in articles:
author_div = article.find("div", class_="author")
author_img = article.img
author_icon = author_img.attrs['src']
author_icon = "https:" + author_icon
author_name = author_img.attrs['alt']
if "匿名用户" not in author_name:
article_gender = author_div.div
author_age = article_gender.text.strip()
article_gender_class = article_gender.attrs['class']
author_gender = "man" if "man" in article_gender_class else "woman"
else:
author_age = -1
author_gender = "no"
article_content = article.find("div", class_='content')
article_stats = article.find_all("i", class_='number')
# print(article_stats)
article_content = article_content.span.text.strip()
stats_vote = article_stats[0].text.strip()
stats_comment = article_stats[1].text.strip()
# 双列表存储
article_info = [author_icon, author_name, author_gender, author_age, article_content, stats_vote, stats_comment]
article_infos.append(article_info)
next_tag = soup.find('span', class_='next')
has_next = next_tag is not None
if has_next:
article_infos.extend(qb_spider2(page + 1)) #调用自己本身
return article_infos
#双列表写入csv
def list_write_to_csv(data_, filename):
with open(filename + '.csv', "w", newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerows(data_)
#列表存字典写入csv
def dict_write_to_csv(data_,filename):
with open(filename + '.csv','w',encoding='utf-8',newline='')as f:
writer=csv.writer(f)
writer.writerow(data_[0].keys())
for data in data_:
writer.writerow(data.values())
#存入数据库(提前建好表)
def write_to_mysql(item):
author_icon=item['头像']
author_name=item['用户名']
author_gender=item['性别']
author_age=item['年龄']
article_content=item['段子']
stats_vote= item['好笑数']
stats_comment=item['评论']
conn=pymysql.connect(host='192.168.169.157',user='root',passwd='123456',db='haha',port=3306,charset='utf8')
with conn:
cur=conn.cursor()
insert_sql="insert into qiubai (author_icon,author_name,author_gender,author_age,article_content,stats_vote,stats_comment) values(%s,%s,%s,%s,%s,%s,%s)"
cur.execute(insert_sql,(author_icon,author_name,author_gender,author_age,article_content,stats_vote,stats_comment))
conn.commit()
def main1():
articles=qb_spider1()
page=1
has_next=True
all_articles = []
while has_next:
articles, has_next = qb_spider1(page)
page += 1
all_articles.extend(articles)
# 用extend 不能用append
# 使用extend的时候,是将articles看作一个序列,将这个序列和all_articles序列合并,并放在其后面。【 】
# 使用append的时候,是将articles看作一个对象,整体打包添加到all_articles对象中。 【 【 】 】
print(has_next, page)
for item in all_articles:
print(item)
#dict_write_to_csv(all_articles,'qbpachong')
write_to_mysql(item)
def main2():
all_articles = qb_spider2()
list_write_to_csv(all_articles, "qiushibaike_text")
for item in all_articles:
print(item)
if __name__=="__main__":
main1()
自己常用的两种储存方式

字典写入csv.png
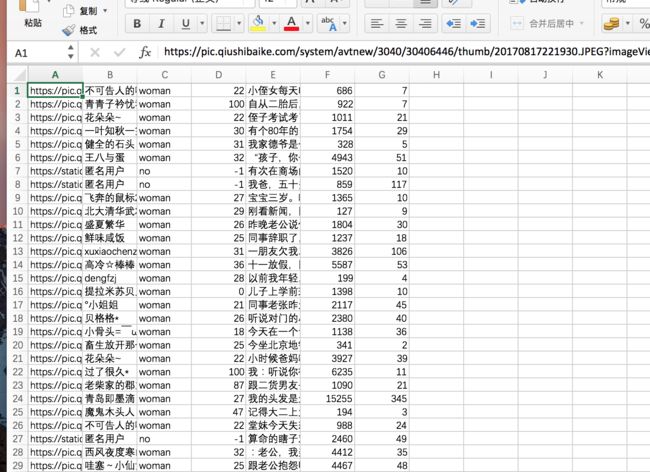
双列表形式写入csv.png
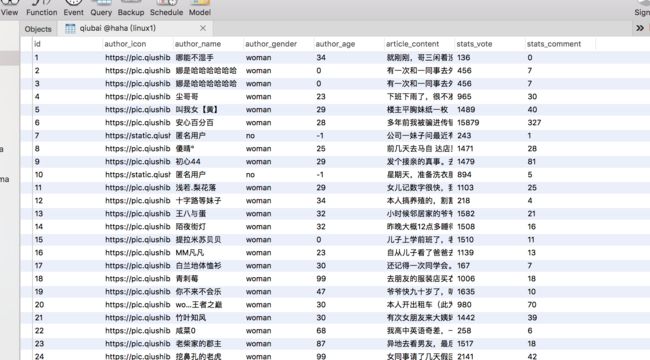
数据存储至MySQL.png