开题:
关于车牌定位分割自己网上找一大堆资料总结后,发布出来还望取之于网友,总结后在公布给网友,能够共同学习,刚接触python没多久,不乏有很多错误和不足,还望指正。
关于本文TensorFlow模型训练部分,来源于
https://blog.csdn.net/shadown1ght/article/details/78571187#comments
也是很感谢此博主的无私开源精神,大家可以前往学习。
代码是最好的老师,所有关于文章的全部代码资源会再文末网盘给出。
2019.4.25更新,更多关于多模型加载方案,请前往csdn博客查看这里不做同步更新了,谢谢理解
博客地址:https://blog.csdn.net/yang1159/article/details/88303461
首先说
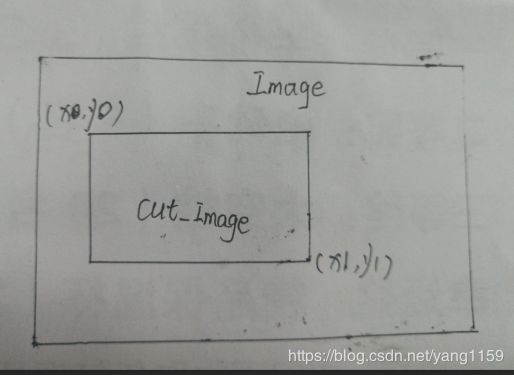
1.python 用opencv的图片切割
cut_img = image[y:y+h, x:x+w] # 裁剪坐标为[y0:y1, x0:x1]
image为源图片,cut_image为切割后的图片
坐标(x0,y0) (x1,y1)关系如图:
2.python 对图片的压缩处理,有两种
第一种是 用的opencv 库的threshold
cv.threshold(src_img, 100, 100, cv.THRESH_BINARY_INV, dec_img)
src_img为源图片,dec_img为压缩后的图片,但我用这种方法处理后保存的图片大小并不是100*100,网上查资料也发现有网友和我一样的情况,或许我没用对,有清楚的还请指正,谢谢。
第二种 用 PIL库处理
from PIL import Image
im = Image.open("./py_car_num_tensor/num_for_car.jpg")
size = 720, 180
mmm = im.resize(size, Image.ANTIALIAS)
mmm.save("./py_car_num_tensor/num_for_car.jpg", "JPEG", quality=95)
这种方法可以直接获取到设定大小的图片
3.opencv对识别到车牌切割后做二值化处理
这里也尝试了三种方法:
第一次使用
img = cv2.imread("./py_car_num_tensor/num_for_car.jpg") # 读取图片
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换了灰度化
cv2.imshow('gray', img_gray) # 显示图片
cv2.waitKey(0)
# 2、将灰度图像二值化,设定阈值是100
img_thre = img_gray
# 灰点 白点 加错
cv2.threshold(img_gray, 130, 255, cv2.THRESH_BINARY_INV, img_thre)
cv2.imshow('threshold', img_thre)
cv2.imwrite('./py_car_num_tensor/wb_img.jpg', img_thre)
cv2.waitKey(0)
src=cv2.imread("./py_car_num_tensor/wb_img.jpg")
height, width, channels = src.shape
print("width:%s,height:%s,channels:%s" % (width, height, channels))
for row in range(height):
for list in range(width):
for c in range(channels):
pv = src[row, list, c]
src[row, list, c] = 255 - pv
cv2.imshow("AfterDeal", src)
在车牌整洁、光照角度合适理想情况下确实可以,但遇到一些带泥水、曝光角度不对时,二值化后会有很多干扰源如:


第二次使用opencv文档说自动阈值 调节的
# 二值化处理 自适应阈值 效果不理想
img_thre = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
效果同样不太理想
第三次使用高斯除噪后在处理,效果堪称完美
# 高斯除噪 二值化处理
blur = cv2.GaussianBlur(img_gray,(5,5),0)
ret3,img_thre = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)


更多opencv 图片处理见opencv中文社区文档(翻译后)http://www.cnblogs.com/Undo-self-blog/p/8423851.html
4.对单个字符的剪切、压缩称制定比例
压缩上面已经将介绍了怎么压缩成指定大小,重点是识别字符坐标后的剪切,这一点在代码里也有很详细说明。
全部代码如下: 关于cascade.xml 获取 见下方网盘
'''
车牌框的识别 剪切保存
'''
# 使用的是HyperLPR已经训练好了的分类器
import os
import cv2
from PIL import Image
import test_province
import test_letters
import test_digits
import time
import numpy as np
import tensorflow as tf
from pip._vendor.distlib._backport import shutil
def find_car_num_brod():
watch_cascade = cv2.CascadeClassifier('D:\PyCharm\Test213\py_car_num_tensor\cascade.xml')
# 先读取图片
image = cv2.imread("D:\PyCharm\Test213\py_car_num_tensor\capture_img\car31.jpg")
resize_h = 1000
height = image.shape[0]
scale = image.shape[1] / float(image.shape[0])
image = cv2.resize(image, (int(scale * resize_h), resize_h))
image_gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
watches = watch_cascade.detectMultiScale(image_gray, 1.2, 2, minSize=(36, 9), maxSize=(36 * 40, 9 * 40))
print("检测到车牌数", len(watches))
for (x, y, w, h) in watches:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 1)
cut_img = image[y + 5:y - 5 + h, x + 8:x - 15 + w] # 裁剪坐标为[y0:y1, x0:x1]
cut_gray = cv2.cvtColor(cut_img, cv2.COLOR_RGB2GRAY)
cv2.imwrite("D:\PyCharm\Test213\py_car_num_tensor\\num_for_car.jpg", cut_gray)
im = Image.open("D:\PyCharm\Test213\py_car_num_tensor\\num_for_car.jpg")
size = 720, 180
mmm = im.resize(size, Image.ANTIALIAS)
mmm.save("D:\PyCharm\Test213\py_car_num_tensor\\num_for_car.jpg", "JPEG", quality=95)
break
'''
剪切后车牌的字符单个拆分保存处理
'''
def cut_car_num_for_chart():
# 1、读取图像,并把图像转换为灰度图像并显示
img = cv2.imread("D:\PyCharm\Test213\py_car_num_tensor\\num_for_car.jpg") # 读取图片
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换了灰度化
cv2.imshow('gray', img_gray) # 显示图片
cv2.waitKey(0)
# 2、将灰度图像二值化,设定阈值是100 转换后 白底黑字 ---》 目标黑底白字
img_thre = img_gray
# 灰点 白点 加错
# cv2.threshold(img_gray, 130, 255, cv2.THRESH_BINARY_INV, img_thre)
# 二值化处理 自适应阈值 效果不理想
# th3 = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
# 高斯除噪 二值化处理
blur = cv2.GaussianBlur(img_gray, (5, 5), 0)
ret3, th3 = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
cv2.imshow('threshold', th3)
cv2.imwrite('D:\PyCharm\Test213\py_car_num_tensor\wb_img.jpg', th3)
cv2.waitKey(0)
# src = cv2.imread("D:\PyCharm\Test213\py_car_num_tensor\wb_img.jpg")
# height, width, channels = src.shape
# print("width:%s,height:%s,channels:%s" % (width, height, channels))
# for row in range(height):
# for list in range(width):
# for c in range(channels):
# pv = src[row, list, c]
# src[row, list, c] = 255 - pv
# cv2.imshow("AfterDeal", src)
# cv2.waitKey(0)
#
# # 3、保存黑白图片
# cv2.imwrite('D:\PyCharm\Test213\py_car_num_tensor\wb_img.jpg', src)
# img = cv2.imread("D:\PyCharm\Test213\py_car_num_tensor\wb_img.jpg") # 读取图片
# src_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换了灰度化
# src_img = src_gray
# 4、分割字符
white = [] # 记录每一列的白色像素总和
black = [] # ..........黑色.......
height = th3.shape[0]
width = th3.shape[1]
white_max = 0
black_max = 0
# 计算每一列的黑白色像素总和
for i in range(width):
s = 0 # 这一列白色总数
t = 0 # 这一列黑色总数
for j in range(height):
if th3[j][i] == 255:
s += 1
if th3[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
print(str(s) + "---------------" + str(t))
print("blackmax ---->" + str(black_max) + "------whitemax ------> " + str(white_max))
arg = False # False表示白底黑字;True表示黑底白字
if black_max > white_max:
arg = True
n = 1
start = 1
end = 2
temp = 1
while n < width - 2:
n += 1
if (white[n] if arg else black[n]) > (0.05 * white_max if arg else 0.05 * black_max):
# 上面这些判断用来辨别是白底黑字还是黑底白字
# 0.05这个参数请多调整,对应上面的0.95
start = n
end = find_end(start, white, black, arg, white_max, black_max, width)
n = end
# 车牌框检测分割 二值化处理后 可以看到明显的左右边框 毕竟用的是网络开放资源 所以车牌框定位角度真的不准,
# 所以我在这里截取单个字符时做处理,就当亡羊补牢吧
# 思路就是从左开始检测匹配字符,若宽度(end - start)小与20则认为是左侧白条 pass掉 继续向右识别,否则说明是
# 省份简称,剪切,压缩 保存,还有一个当后五位有数字 1 时,他的宽度也是很窄的,所以就直接认为是数字 1 不需要再
# 做预测了(不然很窄的 1 截切 压缩后宽度是被拉伸的),shutil.copy(A,B)这个函数就是当检测 #到1时,从训练图片集里面复制一张标准的1的图片给当前这个temp位置的字符,不用再做压缩处理了
if end - start > 5: # 车牌左边白条移除
print(" end - start" + str(end - start))
if temp == 1 and end - start < 20:
pass
elif temp > 3 and end - start < 20:
# 认为这个字符是数字1 copy 一个 32*40的 1 作为 temp.bmp
shutil.copy(os.path.join("D:\\PyCharm\\Test213\\py_car_num_tensor\\tf_car_license_dataset\\train_images\\"
"training-set\\1", "111.bmp"),
os.path.join("D:\PyCharm\Test213\py_car_num_tensor\img_cut", str(temp)+'.bmp'))
pass
else:
cj = th3[1:height, start:end]
cv2.imwrite("D:\PyCharm\Test213\py_car_num_tensor\img_cut_not_3240\\" + str(temp) + ".jpg", cj)
im = Image.open("D:\PyCharm\Test213\py_car_num_tensor\img_cut_not_3240\\" + str(temp) + ".jpg")
size = 32, 40
mmm = im.resize(size, Image.ANTIALIAS)
mmm.save("D:\PyCharm\Test213\py_car_num_tensor\img_cut\\" + str(temp) + ".bmp", quality=95)
# cv2.imshow('裁剪后:', mmm)
# cv2.imwrite("./py_car_num_tensor/img_cut/"+str(temp)+".bmp", cj)
temp = temp + 1
# cv2.waitKey(0)
# 分割图像
def find_end(start_, white, black, arg, white_max, black_max, width):
end_ = start_ + 1
for m in range(start_ + 1, width - 1):
if (black[m] if arg else white[m]) > (0.95 * black_max if arg else 0.95 * white_max): # 0.95这个参数请多调整,对应下面的0.05
end_ = m
break
return end_
'''
车牌号码 省份检测:粤 [粤G .SB250]
'''
SIZE = 1280
WIDTH = 32
HEIGHT = 40
# NUM_CLASSES = 7
PROVINCES = ("京", "闽", "粤", "苏", "沪", "浙", "豫")
nProvinceIndex = 0
time_begin = time.time()
# 定义输入节点,对应于图片像素值矩阵集合和图片标签(即所代表的数字)
x = tf.placeholder(tf.float32, shape=[None, SIZE])
y_ = tf.placeholder(tf.float32, shape=[None, 7])
x_image = tf.reshape(x, [-1, WIDTH, HEIGHT, 1])
# 定义卷积函数
def conv_layer(inputs, W, b, conv_strides, kernel_size, pool_strides, padding):
L1_conv = tf.nn.conv2d(inputs, W, strides=conv_strides, padding=padding)
L1_relu = tf.nn.relu(L1_conv + b)
return tf.nn.max_pool(L1_relu, ksize=kernel_size, strides=pool_strides, padding='SAME')
# 定义全连接层函数
def full_connect(inputs, W, b):
return tf.nn.relu(tf.matmul(inputs, W) + b)
def province_test():
saver_p = tf.train.import_meta_graph(
"D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\province\\car_province.ckpt.meta")
with tf.Session() as sess_p:
model_file = tf.train.latest_checkpoint("D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\province")
saver_p.restore(sess_p, model_file)
# 第一个卷积层
W_conv1 = sess_p.graph.get_tensor_by_name("W_conv1:0")
b_conv1 = sess_p.graph.get_tensor_by_name("b_conv1:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 2, 2, 1]
pool_strides = [1, 2, 2, 1]
L1_pool = conv_layer(x_image, W_conv1, b_conv1, conv_strides, kernel_size, pool_strides, padding='SAME')
# 第二个卷积层
W_conv2 = sess_p.graph.get_tensor_by_name("W_conv2:0")
b_conv2 = sess_p.graph.get_tensor_by_name("b_conv2:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 1, 1, 1]
pool_strides = [1, 1, 1, 1]
L2_pool = conv_layer(L1_pool, W_conv2, b_conv2, conv_strides, kernel_size, pool_strides, padding='SAME')
# 全连接层
W_fc1 = sess_p.graph.get_tensor_by_name("W_fc1:0")
b_fc1 = sess_p.graph.get_tensor_by_name("b_fc1:0")
h_pool2_flat = tf.reshape(L2_pool, [-1, 16 * 20 * 32])
h_fc1 = full_connect(h_pool2_flat, W_fc1, b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# readout层
W_fc2 = sess_p.graph.get_tensor_by_name("W_fc2:0")
b_fc2 = sess_p.graph.get_tensor_by_name("b_fc2:0")
# 定义优化器和训练op
conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
for n in range(1, 2):
path = "D:\\PyCharm\\Test213\\py_car_num_tensor\\img_cut\\%s.bmp" % (n)
img = Image.open(path)
width = img.size[0]
height = img.size[1]
img_data = [[0] * SIZE for i in range(1)]
for h in range(0, height):
for w in range(0, width):
if img.getpixel((w, h)) < 190:
img_data[0][w + h * width] = 1
else:
img_data[0][w + h * width] = 0
result = sess_p.run(conv, feed_dict={x: np.array(img_data), keep_prob: 1.0})
max1 = 0
max2 = 0
max3 = 0
max1_index = 0
max2_index = 0
max3_index = 0
for j in range(7):
if result[0][j] > max1:
max1 = result[0][j]
max1_index = j
continue
if (result[0][j] > max2) and (result[0][j] <= max1):
max2 = result[0][j]
max2_index = j
continue
if (result[0][j] > max3) and (result[0][j] <= max2):
max3 = result[0][j]
max3_index = j
continue
nProvinceIndex = max1_index
print("概率: [%s %0.2f%%] [%s %0.2f%%] [%s %0.2f%%]" % (
PROVINCES[max1_index], max1 * 100, PROVINCES[max2_index], max2 * 100, PROVINCES[max3_index],
max3 * 100))
sess_p.close()
print("省份简称是: %s" % PROVINCES[nProvinceIndex])
'''
车牌号码第二个字符识别:G [粤G .SB250]
'''
SIZE = 1280
WIDTH = 32
HEIGHT = 40
# NUM_CLASSES = 24
LETTERS_DIGITS = (
"A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y",
"Z")
time_begin = time.time()
# 定义输入节点,对应于图片像素值矩阵集合和图片标签(即所代表的数字)
x = tf.placeholder(tf.float32, shape=[None, SIZE])
y_ = tf.placeholder(tf.float32, shape=[None, 24])
x_image = tf.reshape(x, [-1, WIDTH, HEIGHT, 1])
# 定义卷积函数
def conv_layer(inputs, W, b, conv_strides, kernel_size, pool_strides, padding):
L1_conv = tf.nn.conv2d(inputs, W, strides=conv_strides, padding=padding)
L1_relu = tf.nn.relu(L1_conv + b)
return tf.nn.max_pool(L1_relu, ksize=kernel_size, strides=pool_strides, padding='SAME')
# 定义全连接层函数
def full_connect(inputs, W, b):
return tf.nn.relu(tf.matmul(inputs, W) + b)
def province_letter_test():
license_num = ""
saver = tf.train.import_meta_graph("D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\letters\\model.ckpt.meta")
with tf.Session() as sess:
model_file = tf.train.latest_checkpoint("D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\letters")
saver.restore(sess, model_file)
# 第一个卷积层
W_conv1 = sess.graph.get_tensor_by_name("W_conv1:0")
b_conv1 = sess.graph.get_tensor_by_name("b_conv1:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 2, 2, 1]
pool_strides = [1, 2, 2, 1]
L1_pool = conv_layer(x_image, W_conv1, b_conv1, conv_strides, kernel_size, pool_strides, padding='SAME')
# 第二个卷积层
W_conv2 = sess.graph.get_tensor_by_name("W_conv2:0")
b_conv2 = sess.graph.get_tensor_by_name("b_conv2:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 1, 1, 1]
pool_strides = [1, 1, 1, 1]
L2_pool = conv_layer(L1_pool, W_conv2, b_conv2, conv_strides, kernel_size, pool_strides, padding='SAME')
# 全连接层
W_fc1 = sess.graph.get_tensor_by_name("W_fc1:0")
b_fc1 = sess.graph.get_tensor_by_name("b_fc1:0")
h_pool2_flat = tf.reshape(L2_pool, [-1, 16 * 20 * 32])
h_fc1 = full_connect(h_pool2_flat, W_fc1, b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# readout层
W_fc2 = sess.graph.get_tensor_by_name("W_fc2:0")
b_fc2 = sess.graph.get_tensor_by_name("b_fc2:0")
# 定义优化器和训练op
conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
for n in range(2, 3):
path = "D:\\PyCharm\\Test213\\py_car_num_tensor\\img_cut\\%s.bmp" % (n)
img = Image.open(path)
width = img.size[0]
height = img.size[1]
img_data = [[0] * SIZE for i in range(1)]
for h in range(0, height):
for w in range(0, width):
if img.getpixel((w, h)) < 190:
img_data[0][w + h * width] = 1
else:
img_data[0][w + h * width] = 0
result = sess.run(conv, feed_dict={x: np.array(img_data), keep_prob: 1.0})
max1 = 0
max2 = 0
max3 = 0
max1_index = 0
max2_index = 0
max3_index = 0
for j in range(24):
if result[0][j] > max1:
max1 = result[0][j]
max1_index = j
continue
if (result[0][j] > max2) and (result[0][j] <= max1):
max2 = result[0][j]
max2_index = j
continue
if (result[0][j] > max3) and (result[0][j] <= max2):
max3 = result[0][j]
max3_index = j
continue
if n == 3:
license_num += "-"
license_num = license_num + LETTERS_DIGITS[max1_index]
print("概率: [%s %0.2f%%] [%s %0.2f%%] [%s %0.2f%%]" % (
LETTERS_DIGITS[max1_index], max1 * 100, LETTERS_DIGITS[max2_index], max2 * 100,
LETTERS_DIGITS[max3_index],
max3 * 100))
sess.close()
print("城市代号是: 【%s】" % license_num)
'''
车牌号码 后五位识别 SB250 [粤G .SB250]
'''
SIZE = 1280
WIDTH = 32
HEIGHT = 40
# NUM_CLASSES = 34
LETTERS_DIGITS = (
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N",
"P",
"Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z")
time_begin = time.time()
# 定义输入节点,对应于图片像素值矩阵集合和图片标签(即所代表的数字)
x = tf.placeholder(tf.float32, shape=[None, SIZE])
y_ = tf.placeholder(tf.float32, shape=[None, 34])
x_image = tf.reshape(x, [-1, WIDTH, HEIGHT, 1])
# 定义卷积函数
def conv_layer(inputs, W, b, conv_strides, kernel_size, pool_strides, padding):
L1_conv = tf.nn.conv2d(inputs, W, strides=conv_strides, padding=padding)
L1_relu = tf.nn.relu(L1_conv + b)
return tf.nn.max_pool(L1_relu, ksize=kernel_size, strides=pool_strides, padding='SAME')
# 定义全连接层函数
def full_connect(inputs, W, b):
return tf.nn.relu(tf.matmul(inputs, W) + b)
def last_5_num_test():
license_num = ""
saver = tf.train.import_meta_graph("D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\digits\\model.ckpt.meta")
print("main2")
with tf.Session() as sess:
model_file = tf.train.latest_checkpoint("D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\digits")
print("main3")
saver.restore(sess, model_file)
# 第一个卷积层
W_conv1 = sess.graph.get_tensor_by_name("W_conv1:0")
b_conv1 = sess.graph.get_tensor_by_name("b_conv1:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 2, 2, 1]
pool_strides = [1, 2, 2, 1]
L1_pool = conv_layer(x_image, W_conv1, b_conv1, conv_strides, kernel_size, pool_strides, padding='SAME')
# 第二个卷积层
W_conv2 = sess.graph.get_tensor_by_name("W_conv2:0")
b_conv2 = sess.graph.get_tensor_by_name("b_conv2:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 1, 1, 1]
pool_strides = [1, 1, 1, 1]
L2_pool = conv_layer(L1_pool, W_conv2, b_conv2, conv_strides, kernel_size, pool_strides, padding='SAME')
# 全连接层
W_fc1 = sess.graph.get_tensor_by_name("W_fc1:0")
b_fc1 = sess.graph.get_tensor_by_name("b_fc1:0")
h_pool2_flat = tf.reshape(L2_pool, [-1, 16 * 20 * 32])
h_fc1 = full_connect(h_pool2_flat, W_fc1, b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# readout层
W_fc2 = sess.graph.get_tensor_by_name("W_fc2:0")
b_fc2 = sess.graph.get_tensor_by_name("b_fc2:0")
# 定义优化器和训练op
conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
for n in range(4, 9):
path = "D:\\PyCharm\\Test213\\py_car_num_tensor\\img_cut\\%s.bmp" % (n)
img = Image.open(path)
width = img.size[0]
height = img.size[1]
img_data = [[0] * SIZE for i in range(1)]
for h in range(0, height):
for w in range(0, width):
if img.getpixel((w, h)) < 190:
img_data[0][w + h * width] = 1
else:
img_data[0][w + h * width] = 0
result = sess.run(conv, feed_dict={x: np.array(img_data), keep_prob: 1.0})
max1 = 0
max2 = 0
max3 = 0
max1_index = 0
max2_index = 0
max3_index = 0
for j in range(34):
if result[0][j] > max1:
max1 = result[0][j]
max1_index = j
continue
if (result[0][j] > max2) and (result[0][j] <= max1):
max2 = result[0][j]
max2_index = j
continue
if (result[0][j] > max3) and (result[0][j] <= max2):
max3 = result[0][j]
max3_index = j
continue
license_num = license_num + LETTERS_DIGITS[max1_index]
print("概率: [%s %0.2f%%] [%s %0.2f%%] [%s %0.2f%%]" % (
LETTERS_DIGITS[max1_index], max1 * 100, LETTERS_DIGITS[max2_index], max2 * 100,
LETTERS_DIGITS[max3_index],
max3 * 100))
sess.close()
print("车牌编号是: 【%s】" % license_num)
if __name__ == '__main__':
find_car_num_brod() #车牌定位裁剪
cut_car_num_for_chart() #二值化处理裁剪成单个字符
province_test()
#last_5_num_test() 同时加载两个模型还有问题,还望解决过的指明方向
资源链接:链接:https://pan.baidu.com/s/1iE__t08BBt5QbhLOUytOlA
提取码:8c21
复制这段内容后打开百度网盘手机App,操作更方便哦
遗留问题:
目前还有很大的问题就是只能一次加载1个预测模型,加载两个的话会说graph问题,我也按照网上说的一个模型一个graph处理但仍旧不行,这里提供下我的两模型加载代码,还望多多指正问题,我的多模型加载:
import tensorflow as tf
import numpy as np
g1 = tf.Graph()
g2 = tf.Graph()
sess2 = tf.Session(graph=g2)
sess = tf.Session(graph=g1)
# 定义输入节点,对应于图片像素值矩阵集合和图片标签(即所代表的数字)
x = tf.placeholder(tf.float32, shape=[None, 1280])
y_ = tf.placeholder(tf.float32, shape=[None, 7])
x_image = tf.reshape(x, [-1, 32, 40, 1])
# 定义卷积函数
def conv_layer(inputs, W, b, conv_strides, kernel_size, pool_strides, padding):
print("inputs-----",inputs)
print("w ---------",W)
print("b ----------",b)
print("conv_strides ---------" ,conv_strides)
print("kernel_size ----------",kernel_size)
print("pool_strides ----------------",pool_strides)
print("padding-----------------",padding)
L1_conv = tf.nn.conv2d(inputs, W, strides=conv_strides, padding=padding)
L1_relu = tf.nn.relu(L1_conv + b)
return tf.nn.max_pool(L1_relu, ksize=kernel_size, strides=pool_strides, padding='SAME')
# 定义全连接层函数
def full_connect(inputs, W, b):
return tf.nn.relu(tf.matmul(inputs, W) + b)
def load_model():
print("graph1 ---------------------", g1)
with sess.as_default():
with sess.graph.as_default():
graph = tf.get_default_graph()
saver1 = tf.train.import_meta_graph(
"D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\province\\model.ckpt.meta")
model_file = tf.train.latest_checkpoint("D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\province")
saver1.restore(sess, model_file)
print("-------------------------------------------------------------------", graph)
print('Successfully load the pre-trained model!')
# 第一个卷积层
W_conv1 = graph.get_tensor_by_name("W_conv1:0")
b_conv1 = graph.get_tensor_by_name("b_conv1:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 2, 2, 1]
pool_strides = [1, 2, 2, 1]
L1_pool = conv_layer(x_image, W_conv1, b_conv1, conv_strides, kernel_size, pool_strides, padding='SAME')
# 第二个卷积层
W_conv2 = graph.get_tensor_by_name("W_conv2:0")
b_conv2 = graph.get_tensor_by_name("b_conv2:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 1, 1, 1]
pool_strides = [1, 1, 1, 1]
L2_pool = conv_layer(L1_pool, W_conv2, b_conv2, conv_strides, kernel_size, pool_strides, padding='SAME')
# 全连接层
W_fc1 = graph.get_tensor_by_name("W_fc1:0")
b_fc1 = graph.get_tensor_by_name("b_fc1:0")
h_pool2_flat = tf.reshape(L2_pool, [-1, 16 * 20 * 32])
h_fc1 = full_connect(h_pool2_flat, W_fc1, b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# readout层
W_fc2 = graph.get_tensor_by_name("W_fc2:0")
b_fc2 = graph.get_tensor_by_name("b_fc2:0")
# 定义优化器和训练op
conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
print('Successfully load the pre-trained model!')
predict(keep_prob, conv)
from PIL import Image
def predict(keep_prob, conv):
PROVINCES = ("京", "闽", "粤", "苏", "沪", "浙", "豫")
nProvinceIndex = 0
for n in range(1, 2):
path = "D:\\PyCharm\\Test213\\py_car_num_tensor\\img_cut\\%s.bmp" % (n)
img = Image.open(path)
width = img.size[0]
height = img.size[1]
img_data = [[0] * 1280 for i in range(1)]
for h in range(0, height):
for w in range(0, width):
if img.getpixel((w, h)) < 190:
img_data[0][w + h * width] = 1
else:
img_data[0][w + h * width] = 0
result = sess.run(conv, feed_dict={x: np.array(img_data), keep_prob: 1.0})
max1 = 0
max2 = 0
max3 = 0
max1_index = 0
max2_index = 0
max3_index = 0
for j in range(7):
if result[0][j] > max1:
max1 = result[0][j]
max1_index = j
continue
if (result[0][j] > max2) and (result[0][j] <= max1):
max2 = result[0][j]
max2_index = j
continue
if (result[0][j] > max3) and (result[0][j] <= max2):
max3 = result[0][j]
max3_index = j
continue
nProvinceIndex = max1_index
print("概率: [%s %0.2f%%] [%s %0.2f%%] [%s %0.2f%%]" % (
PROVINCES[max1_index], max1 * 100, PROVINCES[max2_index], max2 * 100, PROVINCES[max3_index], max3 * 100))
print("省份简称是: %s" % PROVINCES[nProvinceIndex])
def load_model2():
with sess2.as_default():
with sess2.graph.as_default():
print("sess2 .graph -------->", sess2.graph)
graph = tf.get_default_graph()
print("get default graph --------------------------------------",graph)
saver2 = tf.train.import_meta_graph(
"D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\letters\\model.ckpt.meta")
model_file = tf.train.latest_checkpoint("D:\\PyCharm\\Test213\\py_car_num_tensor\\train-saver\\letters")
saver2.restore(sess2, model_file)
print('Successfully load the pre-trained model!')
# 第一个卷积层
W_conv1 = graph.get_tensor_by_name("W_conv1:0")
b_conv1 = graph.get_tensor_by_name("b_conv1:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 2, 2, 1]
pool_strides = [1, 2, 2, 1]
L1_pool = conv_layer(x_image, W_conv1, b_conv1, conv_strides, kernel_size, pool_strides, padding='SAME')
# 第二个卷积层
W_conv2 = graph.get_tensor_by_name("W_conv2:0")
b_conv2 = graph.get_tensor_by_name("b_conv2:0")
conv_strides = [1, 1, 1, 1]
kernel_size = [1, 1, 1, 1]
pool_strides = [1, 1, 1, 1]
L2_pool = conv_layer(L1_pool, W_conv2, b_conv2, conv_strides, kernel_size, pool_strides, padding='SAME')
# 全连接层
W_fc1 = graph.get_tensor_by_name("W_fc1:0")
b_fc1 = graph.get_tensor_by_name("b_fc1:0")
h_pool2_flat = tf.reshape(L2_pool, [-1, 16 * 20 * 32])
h_fc1 = full_connect(h_pool2_flat, W_fc1, b_fc1)
# dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# readout层
W_fc2 = graph.get_tensor_by_name("W_fc2:0")
b_fc2 = graph.get_tensor_by_name("b_fc2:0")
# 定义优化器和训练op
conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
print('Successfully load the pre-trained model!')
predict2(keep_prob, conv)
def predict2(keep_prob, conv):
LETTERS_DIGITS = (
"A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X",
"Y", "Z")
for n in range(1, 2):
path = "D:\\PyCharm\\Test213\\py_car_num_tensor\\img_cut\\%s.bmp" % (n)
img = Image.open(path)
width = img.size[0]
height = img.size[1]
img_data = [[0] * 1280 for i in range(1)]
for h in range(0, height):
for w in range(0, width):
if img.getpixel((w, h)) < 190:
img_data[0][w + h * width] = 1
else:
img_data[0][w + h * width] = 0
result = sess2.run(conv, feed_dict={x: np.array(img_data), keep_prob: 1.0})
max1 = 0
max2 = 0
max3 = 0
max1_index = 0
max2_index = 0
max3_index = 0
for j in range(7):
if result[0][j] > max1:
max1 = result[0][j]
max1_index = j
continue
if (result[0][j] > max2) and (result[0][j] <= max1):
max2 = result[0][j]
max2_index = j
continue
if (result[0][j] > max3) and (result[0][j] <= max2):
max3 = result[0][j]
max3_index = j
continue
nProvinceIndex = max1_index
print("概率: [%s %0.2f%%] [%s %0.2f%%] [%s %0.2f%%]" % (
LETTERS_DIGITS[max1_index], max1 * 100, LETTERS_DIGITS[max2_index], max2 * 100, LETTERS_DIGITS[max3_index],
max3 * 100))
print("省份简称是: %s" % LETTERS_DIGITS[nProvinceIndex])
if __name__ == '__main__':
load_model()
print("load module 2)
load_model2()
错误类型:ValueError: Tensor("W_conv1:0", shape=(8, 8, 1, 16), dtype=float32_ref) must be from the same graph as Tensor("Reshape:0", shape=(?, 32, 40, 1), dtype=float32).