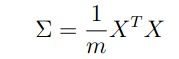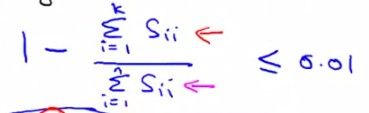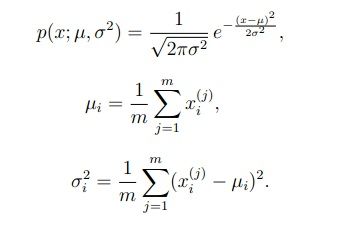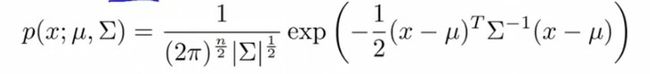- 情绪觉察日记第37天
露露_e800
今天是家庭关系规划师的第二阶最后一天,慧萍老师帮我做了个案,帮我处理了埋在心底好多年的一份恐惧,并给了我深深的力量!这几天出来学习,爸妈过来婆家帮我带小孩,妈妈出于爱帮我收拾东西,并跟我先生和婆婆产生矛盾,妈妈觉得他们没有照顾好我…。今晚回家见到妈妈,我很欣赏她并赞扬她,妈妈说今晚要跟我睡我说好,当我们俩躺在床上准备睡觉的时候,我握着妈妈的手对她说:妈妈这几天辛苦你了,你看你多利害把我们的家收拾得
- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
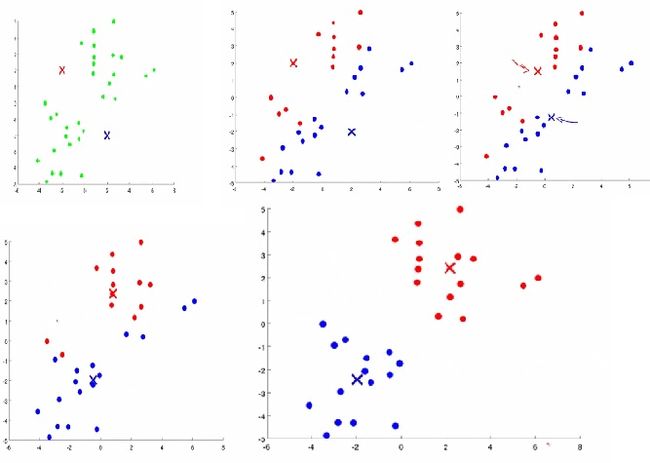
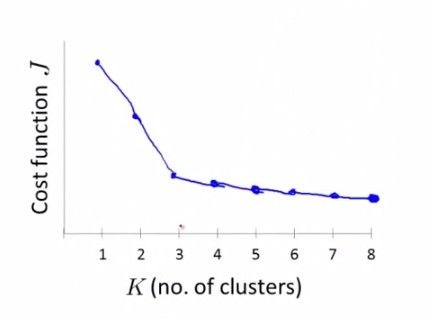
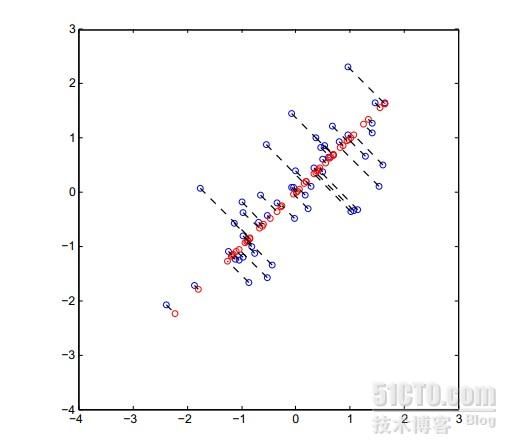
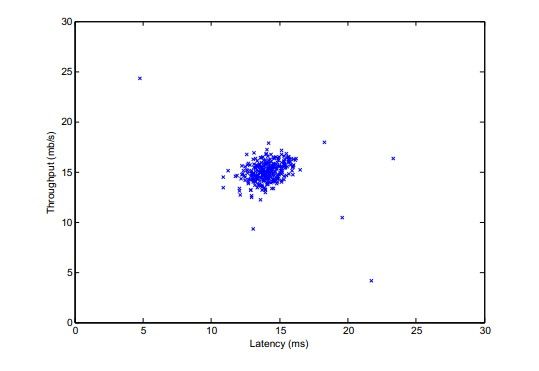
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 铭刻于星(四十二)
随风至
69夜晚,绍敏同学做完功课后,看了眼房外,没听到动静才敢从书包的夹层里拿出那个心形纸团。折痕压得很深,都有些旧了,想来是已经写好很久了。绍敏同学慢慢地、轻轻地捏开折叠处,待到全部拆开后,又反复抚平纸张,然后仔细地一字字默看。只是开头的三个字是第一次看到,让她心漏跳了几拍。“亲爱的绍敏:从四年级的时候,我就喜欢你了,但是我一直不敢说,怕影响你学习。六年级的时候听说有人跟你表白,你接受了,我很难过,但
- UI学习——cell的复用和自定义cell
Magnetic_h
ui学习
目录cell的复用手动(非注册)自动(注册)自定义cellcell的复用在iOS开发中,单元格复用是一种提高表格(UITableView)和集合视图(UICollectionView)滚动性能的技术。当一个UITableViewCell或UICollectionViewCell首次需要显示时,如果没有可复用的单元格,则视图会创建一个新的单元格。一旦这个单元格滚动出屏幕,它就不会被销毁。相反,它被添
- 10月|愿你的青春不负梦想-读书笔记-01
Tracy的小书斋
本书的作者是俞敏洪,大家都很熟悉他了吧。俞敏洪老师是我行业的领头羊吧,也是我事业上的偶像。本日摘录他书中第一章中的金句:『一个人如果什么目标都没有,就会浑浑噩噩,感觉生命中缺少能量。能给我们能量的,是对未来的期待。第一件事,我始终为了进步而努力。与其追寻全世界的骏马,不如种植丰美的草原,到时骏马自然会来。第二件事,我始终有阶段性的目标。什么东西能给我能量?答案是对未来的期待。』读到这里的时候,我便
- 学点心理知识,呵护孩子健康
静候花开_7090
昨天听了华中师范大学教育管理学系副教授张玲老师的《哪里才是学生心理健康的最后庇护所,超越教育与技术的思考》的讲座。今天又重新学习了一遍,收获匪浅。张玲博士也注意到了当今社会上的孩子由于心理问题导致的自残、自杀及伤害他人等恶性事件。她向我们普及了一个重要的命题,她说心理健康的一些基本命题,我们与我们通常的一些教育命题是不同的,她还举了几个例子,让我们明白我们原来以为的健康并非心理学上的健康。比如如果
- 《投行人生》读书笔记
小蘑菇的树洞
《投行人生》----作者詹姆斯-A-朗德摩根斯坦利副主席40年的职业洞见-很短小精悍的篇幅,比较适合初入职场的新人。第一部分成功的职业生涯需要规划1.情商归为适应能力分享与协作同理心适应能力,更多的是自我意识,你有能力识别自己的情并分辨这些情绪如何影响你的思想和行为。2.对于初入职场的人的建议,细节,截止日期和数据很重要截止日期,一种有效的方法是请老板为你所有的任务进行优先级排序。和老板喝咖啡的好
- ArcGIS栅格计算器常见公式(赋值、0和空值的转换、补充栅格空值)
研学随笔
arcgis经验分享
我们在使用ArcGIS时通常经常用到栅格计算器,今天主要给大家介绍我日常中经常用到的几个公式,供大家参考学习。将特定值(-9999)赋值为0,例如-9999.Con("raster"==-9999,0,"raster")2.给空值赋予特定的值(如0)Con(IsNull("raster"),0,"raster")3.将特定的栅格值(如1)赋值为空值,其他保留原值SetNull("raster"==
- 【一起学Rust | 设计模式】习惯语法——使用借用类型作为参数、格式化拼接字符串、构造函数
广龙宇
一起学Rust#Rust设计模式rust设计模式开发语言
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、使用借用类型作为参数二、格式化拼接字符串三、使用构造函数总结前言Rust不是传统的面向对象编程语言,它的所有特性,使其独一无二。因此,学习特定于Rust的设计模式是必要的。本系列文章为作者学习《Rust设计模式》的学习笔记以及自己的见解。因此,本系列文章的结构也与此书的结构相同(后续可能会调成结构),基本上分为三个部分
- 回溯 Leetcode 332 重新安排行程
mmaerd
Leetcode刷题学习记录leetcode算法职场和发展
重新安排行程Leetcode332学习记录自代码随想录给你一份航线列表tickets,其中tickets[i]=[fromi,toi]表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从JFK开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。例如,行程[“JFK”,“LGA”]与[“JFK”,“LGB
- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- git常用命令笔记
咩酱-小羊
git笔记
###用习惯了idea总是不记得git的一些常见命令,需要用到的时候总是担心旁边站了人~~~记个笔记@_@,告诉自己看笔记不丢人初始化初始化一个新的Git仓库gitinit配置配置用户信息gitconfig--globaluser.name"YourName"gitconfig--globaluser.email"
[email protected]"基本操作克隆远程仓库gitclone查看
- 2019-12-22-22:30
涓涓1016
今天是冬至,写下我的日更,是因为这两天的学习真的是能量的满满,让我看到了自己,未来另外一种可能性,也让我看到了这两年这几年的过程中我所接受那些痛苦的来源。一切的根源和痛苦都来自于人生,家庭,而你的原生家庭,你的爸爸和妈妈,是因为你这个灵魂在那一刻选择他们作为你的爸爸和妈妈来的,所以你得接受他,你得接纳他,他就是因为他的存在而给你的学习和成长带来这些痛苦,那其实是你必然要经历的这个过程,当你去接纳的
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 509. 斐波那契数(每日一题)
lzyprime
lzyprime博客(github)创建时间:2021.01.04qq及邮箱:2383518170leetcode笔记题目描述斐波那契数,通常用F(n)表示,形成的序列称为斐波那契数列。该数列由0和1开始,后面的每一项数字都是前面两项数字的和。也就是:F(0)=0,F(1)=1F(n)=F(n-1)+F(n-2),其中n>1给你n,请计算F(n)。示例1:输入:2输出:1解释:F(2)=F(1)+
- 拥有断舍离的心态,过精简生活--《断舍离》读书笔记
爱吃丸子的小樱桃
不知不觉间房间里的东西越来越多,虽然摆放整齐,但也时常会觉得空间逼仄,令人心生烦闷。抱着断舍离的态度,我开始阅读《断舍离》这本书,希望从书中能找到一些有效的方法,帮助我实现空间、物品上的断舍离。《断舍离》是日本作家山下英子通过自己的经历、思考和实践总结而成的,整体内涵也从刚开始的私人生活哲学的“断舍离”升华成了“人生实践哲学”,接着又成为每个人都能实行的“改变人生的断舍离”,从“哲学”逐渐升华成“
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- 高端密码学院笔记285
柚子_b4b4
高端幸福密码学院(高级班)幸福使者:李华第(598)期《幸福》之回归内在深层生命原动力基础篇——揭秘“激励”成长的喜悦心理案例分析主讲:刘莉一,知识扩充:成功=艰苦劳动+正确方法+少说空话。贪图省力的船夫,目标永远下游。智者的梦再美,也不如愚人实干的脚印。幸福早课堂2020.10.16星期五一笔记:1,重视和珍惜的前提是知道它的价值非常重要,当你珍惜了,你就真正定下来,真正的学到身上。2,大家需要
- GitHub上克隆项目
bigbig猩猩
github
从GitHub上克隆项目是一个简单且直接的过程,它允许你将远程仓库中的项目复制到你的本地计算机上,以便进行进一步的开发、测试或学习。以下是一个详细的步骤指南,帮助你从GitHub上克隆项目。一、准备工作1.安装Git在克隆GitHub项目之前,你需要在你的计算机上安装Git工具。Git是一个开源的分布式版本控制系统,用于跟踪和管理代码变更。你可以从Git的官方网站(https://git-scm.
- HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动
二挡起步
web前端期末大作业web设计网页规划与设计htmlcssjavascriptdreamweaver前端
Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线
- Day17笔记-高阶函数
~在杰难逃~
Python笔记python开发语言pycharm数据分析
高阶函数【重点掌握】函数的本质:函数是一个变量,函数名是一个变量名,一个函数可以作为另一个函数的参数或返回值使用如果A函数作为B函数的参数,B函数调用完成之后,会得到一个结果,则B函数被称为高阶函数常用的高阶函数:map(),reduce(),filter(),sorted()1.map()map(func,iterable),返回值是一个iterator【容器,迭代器】func:函数iterab
- Day1笔记-Python简介&标识符和关键字&输入输出
~在杰难逃~
Pythonpython开发语言大数据数据分析数据挖掘
大家好,从今天开始呢,杰哥开展一个新的专栏,当然,数据分析部分也会不定时更新的,这个新的专栏主要是讲解一些Python的基础语法和知识,帮助0基础的小伙伴入门和学习Python,感兴趣的小伙伴可以开始认真学习啦!一、Python简介【了解】1.计算机工作原理编程语言就是用来定义计算机程序的形式语言。我们通过编程语言来编写程序代码,再通过语言处理程序执行向计算机发送指令,让计算机完成对应的工作,编程
- 人工智能时代,程序员如何保持核心竞争力?
jmoych
人工智能
随着AIGC(如chatgpt、midjourney、claude等)大语言模型接二连三的涌现,AI辅助编程工具日益普及,程序员的工作方式正在发生深刻变革。有人担心AI可能取代部分编程工作,也有人认为AI是提高效率的得力助手。面对这一趋势,程序员应该如何应对?是专注于某个领域深耕细作,还是广泛学习以适应快速变化的技术环境?又或者,我们是否应该将重点转向AI无法轻易替代的软技能?让我们一起探讨程序员
- node.js学习
小猿L
node.jsnode.js学习vim
node.js学习实操及笔记温故node.js,node.js学习实操过程及笔记~node.js学习视频node.js官网node.js中文网实操笔记githubcsdn笔记为什么学node.js可以让别人访问我们编写的网页为后续的框架学习打下基础,三大框架vuereactangular离不开node.jsnode.js是什么官网:node.js是一个开源的、跨平台的运行JavaScript的运行
- 阶段总结反思
轻争
马上就要进入10月份了,今天做一下前段时间的总结和反思。前段时间,日更、英语、健身、护肤坚持的比较好。阅读、书法坚持的不好。1.中间被迫停更半个多月,其余时间一直在坚持日更挑战。偶尔也有不想写的时候,就做一下摘抄。因为阅读(输入)没跟上来,所以写作(输出)质量有待进一步加强。2.英语做到了一周至少学习5天,每次不少于30分钟,但是小班课没有跟上更新速度,下一步要争取利用零碎时间补听小班课。3.减肥
- 数据仓库——维度表一致性
墨染丶eye
背诵数据仓库
数据仓库基础笔记思维导图已经整理完毕,完整连接为:数据仓库基础知识笔记思维导图维度一致性问题从逻辑层面来看,当一系列星型模型共享一组公共维度时,所涉及的维度称为一致性维度。当维度表存在不一致时,短期的成功难以弥补长期的错误。维度时确保不同过程中信息集成起来实现横向钻取货活动的关键。造成横向钻取失败的原因维度结构的差别,因为维度的差别,分析工作涉及的领域从简单到复杂,但是都是通过复杂的报表来弥补设计
- ARM驱动学习之基础小知识
JT灬新一
ARM嵌入式arm开发学习
ARM驱动学习之基础小知识•sch原理图工程师工作内容–方案–元器件选型–采购(能不能买到,价格)–原理图(涉及到稳定性)•layout画板工程师–layout(封装、布局,布线,log)(涉及到稳定性)–焊接的一部分工作(调试阶段板子的焊接)•驱动工程师–驱动,原理图,layout三部分的交集容易发生矛盾•PCB研发流程介绍–方案,原理图(网表)–layout工程师(gerber文件)–PCB板
- ARM驱动学习之5 LEDS驱动
JT灬新一
嵌入式C底层arm开发学习单片机
ARM驱动学习之5LEDS驱动知识点:•linuxGPIO申请函数和赋值函数–gpio_request–gpio_set_value•三星平台配置GPIO函数–s3c_gpio_cfgpin•GPIO配置输出模式的宏变量–S3C_GPIO_OUTPUT注意点:DRIVER_NAME和DEVICE_NAME匹配。实现步骤:1.加入需要的头文件://Linux平台的gpio头文件#include//三
- ARM驱动学习之4小结
JT灬新一
嵌入式C++arm开发学习linux
ARM驱动学习之4小结#include#include#include#include#include#defineDEVICE_NAME"hello_ctl123"MODULE_LICENSE("DualBSD/GPL");MODULE_AUTHOR("TOPEET");staticlonghello_ioctl(structfile*file,unsignedintcmd,unsignedlo
- 展现思维导图魅力,不断挖掘人生宝藏
思维导图讲师Mandy
第13期最强思维导图训练营已经结束一周了,但是我依旧是感觉所有学员还在努力的学习,这些学员中有教师、学生、白领、公务员、宝妈等等,只要你努力,只要你想改变自己,任何行业,任何岗位都可以参与进来,28天足以让你见成效,在这28天中,我们的学员不仅仅是收获了一枚毕业证,最重要的是让自己的思维方式得到升级,今天的你为自己投资,明天的你就会感谢你今天的付出,我们来听一听来自13期最强思维导图训练营优秀学员
- 多线程编程之存钱与取钱
周凡杨
javathread多线程存钱取钱
生活费问题是这样的:学生每月都需要生活费,家长一次预存一段时间的生活费,家长和学生使用统一的一个帐号,在学生每次取帐号中一部分钱,直到帐号中没钱时 通知家长存钱,而家长看到帐户还有钱则不存钱,直到帐户没钱时才存钱。
问题分析:首先问题中有三个实体,学生、家长、银行账户,所以设计程序时就要设计三个类。其中银行账户只有一个,学生和家长操作的是同一个银行账户,学生的行为是
- java中数组与List相互转换的方法
征客丶
JavaScriptjavajsonp
1.List转换成为数组。(这里的List是实体是ArrayList)
调用ArrayList的toArray方法。
toArray
public T[] toArray(T[] a)返回一个按照正确的顺序包含此列表中所有元素的数组;返回数组的运行时类型就是指定数组的运行时类型。如果列表能放入指定的数组,则返回放入此列表元素的数组。否则,将根据指定数组的运行时类型和此列表的大小分
- Shell 流程控制
daizj
流程控制if elsewhilecaseshell
Shell 流程控制
和Java、PHP等语言不一样,sh的流程控制不可为空,如(以下为PHP流程控制写法):
<?php
if(isset($_GET["q"])){
search(q);}else{// 不做任何事情}
在sh/bash里可不能这么写,如果else分支没有语句执行,就不要写这个else,就像这样 if else if
if 语句语
- Linux服务器新手操作之二
周凡杨
Linux 简单 操作
1.利用关键字搜寻Man Pages man -k keyword 其中-k 是选项,keyword是要搜寻的关键字 如果现在想使用whoami命令,但是只记住了前3个字符who,就可以使用 man -k who来搜寻关键字who的man命令 [haself@HA5-DZ26 ~]$ man -k
- socket聊天室之服务器搭建
朱辉辉33
socket
因为我们做的是聊天室,所以会有多个客户端,每个客户端我们用一个线程去实现,通过搭建一个服务器来实现从每个客户端来读取信息和发送信息。
我们先写客户端的线程。
public class ChatSocket extends Thread{
Socket socket;
public ChatSocket(Socket socket){
this.sock
- 利用finereport建设保险公司决策分析系统的思路和方法
老A不折腾
finereport金融保险分析系统报表系统项目开发
决策分析系统呈现的是数据页面,也就是俗称的报表,报表与报表间、数据与数据间都按照一定的逻辑设定,是业务人员查看、分析数据的平台,更是辅助领导们运营决策的平台。底层数据决定上层分析,所以建设决策分析系统一般包括数据层处理(数据仓库建设)。
项目背景介绍
通常,保险公司信息化程度很高,基本上都有业务处理系统(像集团业务处理系统、老业务处理系统、个人代理人系统等)、数据服务系统(通过
- 始终要页面在ifream的最顶层
林鹤霄
index.jsp中有ifream,但是session消失后要让login.jsp始终显示到ifream的最顶层。。。始终没搞定,后来反复琢磨之后,得到了解决办法,在这儿给大家分享下。。
index.jsp--->主要是加了颜色的那一句
<html>
<iframe name="top" ></iframe>
<ifram
- MySQL binlog恢复数据
aigo
mysql
1,先确保my.ini已经配置了binlog:
# binlog
log_bin = D:/mysql-5.6.21-winx64/log/binlog/mysql-bin.log
log_bin_index = D:/mysql-5.6.21-winx64/log/binlog/mysql-bin.index
log_error = D:/mysql-5.6.21-win
- OCX打成CBA包并实现自动安装与自动升级
alxw4616
ocxcab
近来手上有个项目,需要使用ocx控件
(ocx是什么?
http://baike.baidu.com/view/393671.htm)
在生产过程中我遇到了如下问题.
1. 如何让 ocx 自动安装?
a) 如何签名?
b) 如何打包?
c) 如何安装到指定目录?
2.
- Hashmap队列和PriorityQueue队列的应用
百合不是茶
Hashmap队列PriorityQueue队列
HashMap队列已经是学过了的,但是最近在用的时候不是很熟悉,刚刚重新看以一次,
HashMap是K,v键 ,值
put()添加元素
//下面试HashMap去掉重复的
package com.hashMapandPriorityQueue;
import java.util.H
- JDK1.5 returnvalue实例
bijian1013
javathreadjava多线程returnvalue
Callable接口:
返回结果并且可能抛出异常的任务。实现者定义了一个不带任何参数的叫做 call 的方法。
Callable 接口类似于 Runnable,两者都是为那些其实例可能被另一个线程执行的类设计的。但是 Runnable 不会返回结果,并且无法抛出经过检查的异常。
ExecutorService接口方
- angularjs指令中动态编译的方法(适用于有异步请求的情况) 内嵌指令无效
bijian1013
JavaScriptAngularJS
在directive的link中有一个$http请求,当请求完成后根据返回的值动态做element.append('......');这个操作,能显示没问题,可问题是我动态组的HTML里面有ng-click,发现显示出来的内容根本不执行ng-click绑定的方法!
- 【Java范型二】Java范型详解之extend限定范型参数的类型
bit1129
extend
在第一篇中,定义范型类时,使用如下的方式:
public class Generics<M, S, N> {
//M,S,N是范型参数
}
这种方式定义的范型类有两个基本的问题:
1. 范型参数定义的实例字段,如private M m = null;由于M的类型在运行时才能确定,那么我们在类的方法中,无法使用m,这跟定义pri
- 【HBase十三】HBase知识点总结
bit1129
hbase
1. 数据从MemStore flush到磁盘的触发条件有哪些?
a.显式调用flush,比如flush 'mytable'
b.MemStore中的数据容量超过flush的指定容量,hbase.hregion.memstore.flush.size,默认值是64M 2. Region的构成是怎么样?
1个Region由若干个Store组成
- 服务器被DDOS攻击防御的SHELL脚本
ronin47
mkdir /root/bin
vi /root/bin/dropip.sh
#!/bin/bash/bin/netstat -na|grep ESTABLISHED|awk ‘{print $5}’|awk -F:‘{print $1}’|sort|uniq -c|sort -rn|head -10|grep -v -E ’192.168|127.0′|awk ‘{if($2!=null&a
- java程序员生存手册-craps 游戏-一个简单的游戏
bylijinnan
java
import java.util.Random;
public class CrapsGame {
/**
*
*一个简单的赌*博游戏,游戏规则如下:
*玩家掷两个骰子,点数为1到6,如果第一次点数和为7或11,则玩家胜,
*如果点数和为2、3或12,则玩家输,
*如果和为其它点数,则记录第一次的点数和,然后继续掷骰,直至点数和等于第一次掷出的点
- TOMCAT启动提示NB: JAVA_HOME should point to a JDK not a JRE解决
开窍的石头
JAVA_HOME
当tomcat是解压的时候,用eclipse启动正常,点击startup.bat的时候启动报错;
报错如下:
The JAVA_HOME environment variable is not defined correctly
This environment variable is needed to run this program
NB: JAVA_HOME shou
- [操作系统内核]操作系统与互联网
comsci
操作系统
我首先申明:我这里所说的问题并不是针对哪个厂商的,仅仅是描述我对操作系统技术的一些看法
操作系统是一种与硬件层关系非常密切的系统软件,按理说,这种系统软件应该是由设计CPU和硬件板卡的厂商开发的,和软件公司没有直接的关系,也就是说,操作系统应该由做硬件的厂商来设计和开发
- 富文本框ckeditor_4.4.7 文本框的简单使用 支持IE11
cuityang
富文本框
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>知识库内容编辑</tit
- Property null not found
darrenzhu
datagridFlexAdvancedpropery null
When you got error message like "Property null not found ***", try to fix it by the following way:
1)if you are using AdvancedDatagrid, make sure you only update the data in the data prov
- MySQl数据库字符串替换函数使用
dcj3sjt126com
mysql函数替换
需求:需要将数据表中一个字段的值里面的所有的 . 替换成 _
原来的数据是 site.title site.keywords ....
替换后要为 site_title site_keywords
使用的SQL语句如下:
updat
- mac上终端起动MySQL的方法
dcj3sjt126com
mysqlmac
首先去官网下载: http://www.mysql.com/downloads/
我下载了5.6.11的dmg然后安装,安装完成之后..如果要用终端去玩SQL.那么一开始要输入很长的:/usr/local/mysql/bin/mysql
这不方便啊,好想像windows下的cmd里面一样输入mysql -uroot -p1这样...上网查了下..可以实现滴.
打开终端,输入:
1
- Gson使用一(Gson)
eksliang
jsongson
转载请出自出处:http://eksliang.iteye.com/blog/2175401 一.概述
从结构上看Json,所有的数据(data)最终都可以分解成三种类型:
第一种类型是标量(scalar),也就是一个单独的字符串(string)或数字(numbers),比如"ickes"这个字符串。
第二种类型是序列(sequence),又叫做数组(array)
- android点滴4
gundumw100
android
Android 47个小知识
http://www.open-open.com/lib/view/open1422676091314.html
Android实用代码七段(一)
http://www.cnblogs.com/over140/archive/2012/09/26/2611999.html
http://www.cnblogs.com/over140/arch
- JavaWeb之JSP基本语法
ihuning
javaweb
目录
JSP模版元素
JSP表达式
JSP脚本片断
EL表达式
JSP注释
特殊字符序列的转义处理
如何查找JSP页面中的错误
JSP模版元素
JSP页面中的静态HTML内容称之为JSP模版元素,在静态的HTML内容之中可以嵌套JSP
- App Extension编程指南(iOS8/OS X v10.10)中文版
啸笑天
ext
当iOS 8.0和OS X v10.10发布后,一个全新的概念出现在我们眼前,那就是应用扩展。顾名思义,应用扩展允许开发者扩展应用的自定义功能和内容,能够让用户在使用其他app时使用该项功能。你可以开发一个应用扩展来执行某些特定的任务,用户使用该扩展后就可以在多个上下文环境中执行该任务。比如说,你提供了一个能让用户把内容分
- SQLServer实现无限级树结构
macroli
oraclesqlSQL Server
表结构如下:
数据库id path titlesort 排序 1 0 首页 0 2 0,1 新闻 1 3 0,2 JAVA 2 4 0,3 JSP 3 5 0,2,3 业界动态 2 6 0,2,3 国内新闻 1
创建一个存储过程来实现,如果要在页面上使用可以设置一个返回变量将至传过去
create procedure test
as
begin
decla
- Css居中div,Css居中img,Css居中文本,Css垂直居中div
qiaolevip
众观千象学习永无止境每天进步一点点css
/**********Css居中Div**********/
div.center {
width: 100px;
margin: 0 auto;
}
/**********Css居中img**********/
img.center {
display: block;
margin-left: auto;
margin-right: auto;
}
- Oracle 常用操作(实用)
吃猫的鱼
oracle
SQL>select text from all_source where owner=user and name=upper('&plsql_name');
SQL>select * from user_ind_columns where index_name=upper('&index_name'); 将表记录恢复到指定时间段以前
- iOS中使用RSA对数据进行加密解密
witcheryne
iosrsaiPhoneobjective c
RSA算法是一种非对称加密算法,常被用于加密数据传输.如果配合上数字摘要算法, 也可以用于文件签名.
本文将讨论如何在iOS中使用RSA传输加密数据. 本文环境
mac os
openssl-1.0.1j, openssl需要使用1.x版本, 推荐使用[homebrew](http://brew.sh/)安装.
Java 8
RSA基本原理
RS