在流处理系统中,通常使用基于ProcessTime ,EventTime,Ingestion Time的消息处理模式。 相关含义可参考Flink 对于流消息的时间介绍
| 时间模式 | 时间来源 | 备注 |
|---|---|---|
| ProcessingTime | 处理消息时的系统时间 | 无法处理乱序 |
| Ingestion Time | 接收消息时的系统时间 | 无法处理乱序 |
| EventTime | 消息本身带有的时间 | 通常该时间戳表明消息产生时间 |
-
现实中的流消息延迟是必然的:
理想状态下,消息从产生要接收没有时间的延迟,基于消息的ProcessingTime和EventTime的统计处理没有区别,我们得到的结果是一样的。然而现实情况却不完全如此。如我们再处理电信信令消息时,在消息到达流系统之前要经过各种流程的解析分发,显然从信令产生到被流处理系统处理肯定有一定的消息延,如
00:00:00时刻的消息到了流系统时,已经是00:05:00 -
基于EventTime的消息处理是对Processing/Ingestion Time机制的完善:
通常对于消息时间本身没有特殊要求的场景,如消息的简单ETL处理,如消息分发过滤等场景,我们无需考虑消息的乱序,基于接收/处理时间来完成消息的处理可以满足生产需要。
但是还有一些场景如统计某一段时间内(如
12:00:00 ---13:00:00)某一个路口的车流量时,在该时间段内的消息进入流系统时,可能已经是(如14:00:00 ---15:00:00),如果是基于PorcessingTime的处理统计出来的车流量是14:00:00 ---15:00:00期间的车流量,然而我们真正需要的或者说现实的情况是,这个车流量是12:00:00 ---13:00:00,这个就会引发决策者/或者管理部门无法拿到真实的数据统计,进而引发错误的决策。 ProcessingTime VS EventTime
ProcessingTime VS EventTime
从上图可知,对于带有窗口的流消息统计中,基于EventTime的消息处理反应了消息本身的时间属性,具有特定的含义。当前主流的大数据流处理框架均支持了EventTime,ProcessTime的消息处理,以下对Spark和Flink的基于ProcessTime和EventTime的消息处理机制进行分析对比。
基于IngestionTime的消息处理大致与ProcessTime的处理类似,亦无法处理乱序/延迟消息,此处不再区分ProcessTime和IngestionTime
Processing Time的处理逻辑
Spark对于processingTime的处理
Spark中的Sparkstreaming和StructuredStreaming 均支持基于ProcessingTime的消息处理模式,二者均是基于micro-batch的处理,核心逻辑是定期触发批次处理,由Driver计算出本批次需要处理的消息,然后发送至executor启动task线程处理。如下图:

Spark中的基于ProcessingTime的处理,其中的ProcessingTime真正使用到的为Dirver所在节点的时间,与Executor计算节点的时间无关。如在Window中统计时,其window的时间就是Driver节点的window系统时间。
严格来说,Spark中的ProcessingTime既不是ProcessingTime(并非基于真正的收到消息的时间,而是读取消息前就已经设定好了时间),又不是IngestionTime(没有消息时间戳设定这一步)
StructuredStreaming同时包含了Continuous模式的消息处理模式,由于该模式在最新的Spark2.4中依旧是Experiment状态,当前只能支持简单的Map类的操作,无法支持聚合,此处暂时忽略该模式
Flink中基于ProcessingTime的处理
Flink中基于ProcessingTime的消息处理,使用的是读取和处理消息时的进程所在节点的系统时间。如果在多个节点执行,由于节点的系统误差,可能存在时间窗口不一致的情况。
以带有window的消息统计为例,其主要逻辑如下:
1:在接收到消息时,根据当前系统时间及窗口大小的设置,获取窗口并以窗口END值设置定时任务。
2:定时任务在时间到了之后触发窗口计算,输出结果
Event Time的处理逻辑
EventTime与ProcessingTime相比,更能反映消息自身的时间属性,对于关注消息发生时间的统计来说,具有重要意义。
流处理中的window
由于流数据的无限(没有尽头)的特征,类似传统批处理的全量统计无法进行,基于流消息的统计通常只能分段进行,在流处理中,“一段”即成为一个“window”。
流消息的延迟
-
消息的绝对延迟
延迟不是指流消息的产生时间到处理时间的不可避免的绝对延迟
-
消息的相对延迟(乱序)
在生成时有序的消息,由于各种现实情况如网络,设备故障/重启等原因引发的在进入流系统时变成无序消息的现象。
现实生活中,由于种种原因,消息的乱序(延迟)几乎是一种必然,在流消息的统计中,由于采用的是分段(window)统计,但消息又是延迟的,如何界定一个window的统计已经完成,可以输出了呢?
流技术中采用了watermark(水印/水平线)的概念,其核心思想是设定一个乱序的容忍阈值(lateness),基于当前所接收到的消息的最大的时间戳(maxTimeStamp)和设定的lateness算出一个watermark,后续所有时间戳小于该watermark的消息,均被认为是迟到的消息,不会被计算在内。
关于Event Time,watermark概念介绍可以参考 StructuredStreaming:Window-on-EventTime
EventTime和Watermark的生成
StructuredStreaming中EventTime和watermark的逻辑
Spark中只有StructuredStreaming支持EventTime模式的消息处理。
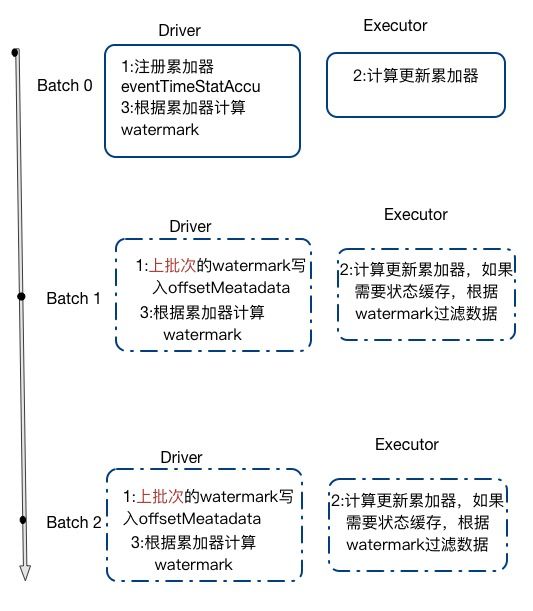
其核心思想/步骤如下:
是在driver端通过物理计划EventTimeWatermarkExec注册一个累加器EventTimeStatsAccum
-
在executor中每个task处理消息时,根据消息的时间状态操作累加器记录更新时间戳,从EventTimeWatermarkExec的doExecute方法中可以看到
iter.map { row => eventTimeStats.add(getEventTime(row).getLong(0) / 1000) row } -
在批次运行结束后调用updateWatermark统计该累加器的值,并根据设定的lateness,计算并记录watermark
watermarkOperators.zipWithIndex.foreach { case (e, index) if e.eventTimeStats.value.count > 0 => logDebug(s"Observed event time stats $index: ${e.eventTimeStats.value}") val newWatermarkMs = e.eventTimeStats.value.max - e.delayMs val prevWatermarkMs = operatorToWatermarkMap.get(index) if (prevWatermarkMs.isEmpty || newWatermarkMs > prevWatermarkMs.get) { operatorToWatermarkMap.put(index, newWatermarkMs) } ... -
在下个批次时候,通过constructNextBatch更新watermark
offsetSeqMetadata = offsetSeqMetadata.copy( batchWatermarkMs = watermarkTracker.currentWatermark, batchTimestampMs = triggerClock.getTimeMillis()) -
下个Executor的task在计算时,执行第二步的逻辑;如果有用到需要缓存状态时,会判读消息时候延迟,通过predict算子直接过滤掉。如StateStoreSaveExec,FlatMapGroupsWithStateExec,SymmetricHashJoinStateManager算子。以StateStoreSaveExec为例,查看其doExecute方法
case Some(Append) => allUpdatesTimeMs += timeTakenMs { val filteredIter = iter.filter(row => !watermarkPredicateForData.get.eval(row))}
由第五步可以看出task中接收到的消息只要小于该watermark,直接丢弃该消息。
Flink中EventTime和watermark的逻辑
与StructuredStreaming中每个批次一个watermark的处理逻辑不同,Flink流处理中没有批次的概念,其eventTime的提取方式与Structured类似,由taskManager中的source相关线程完成eventTime的读取。关于watermark的生成则默认提供两种方式,同时支持自定义eventTime和watermark的生成方式。
AssignerWithPeriodicWatermarks : 启动独立线程定期根据maxEventTime生成watermark
AssignerWithPunctuatedWatermarks :每条消息都会进入接口的checkAndGetNextWatermark函数,可以`实现严格意义的乱序消息处理`为每一条记录都生成一个watermark,但对性能有较大影响,在特定的场景(如:消息中包含某些标志来触发生成watermark)下使用。
Flink的watermark生成可参考
通常应用中使用AssignerWithPeriodicWatermarks进行周期性的watermark生成方式,其大致实现如下:
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxOutOfOrderness = 3500L // 3.5 seconds
var currentMaxTimestamp: Long = _
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
val timestamp = element.getCreationTime()
currentMaxTimestamp = max(timestamp, currentMaxTimestamp)
timestamp
}
override def getCurrentWatermark(): Watermark = {
// return the watermark as current highest timestamp minus the out-of-orderness bound
new Watermark(currentMaxTimestamp - maxOutOfOrderness)
}
}
在执行中主要由如下两步
1. Source线程读取消息,调用extractTimestamp提取消息时间,计算得出currentMaxTimestamp
2. Time trigger线程周期性调用getCurrentWatermark方法获取watermark值,并发送至下游operator
在Flink中,对于迟到的消息,默认的策略是丢弃消息但记录丢弃消息总数,但支持siedeoutput机制将消息单独输出。
if (isSkippedElement && isElementLate(element)) {
if (lateDataOutputTag != null){
sideOutput(element);
} else {
this.numLateRecordsDropped.inc();
}
}
总结:
相同之处:
- 在概念上,Flink和Spark(StructuredStreaming)对eventTime和watermark的定义是一致的,都是用于处理乱序数据
- 在实现中,Flink的周期性watermark提取的实现原理和Structured比较一致,周期性获取watermark
- 从实现效果来看,StructuredStreaming和Flink基于周期性的watermark获取方式并不能完全彻底的处理消息的乱序。只能处理批次间(Flink的不同watermark的调用之间)的消息乱序,对于同一批次或者同一同期间隔时间内的数据的乱序并不能完美
- StructuredStreaming的watermark使用的是
yyyy-MM-dd HH:mm:ss的方式表示,而flink则是Long型数字表示, - Flink通过AssignerWithPunctuatedWatermarks实现了严格意义的乱序消息处理,且支持可定制的实现方式,与Structured相比更加灵活,更加完善
- 对于延迟的消息,StructuredStreaming的处理逻辑是直接丢弃,Flink支持将延迟消息单独输出,便于数据稽查
Window的触发
流消息的统计基于Window,那么何时触发window?
StructuredStreaming中window的触发
在StructuredStreaming中,Window用户统计如执行groupby后进行count,max等操作,其window的触发基于trigger机制,其核心逻辑是设定窗口大小,基于窗口将消息划分至不同的窗口内,使用update或complete模式完成窗口消息统计和输出。 关于Trigger可以参考
StructuredStreaming中的统计输出分为三种模式:
| 模式 | 解释 |
|---|---|
| Complete | 全量输出,每次统计的全量结果全部输出 |
| Update | 每次统计输出统计更新结果 |
| Append | 追加模式,后续的结果输出是在之前的结果上追加,已输出的不会修改 |
- 生产中使用Append模式居多
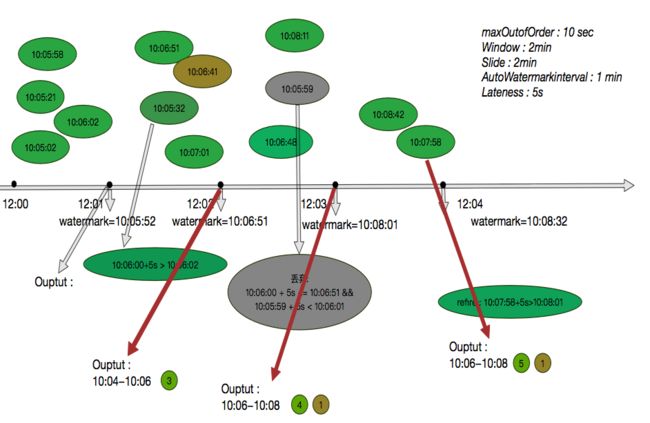
如下图展示了消息的触发和计算:
有如下几个特征 :
- watermark由trigger触发
- 迟到消息只能丢弃处理
- append模式当watermark大于window的end时,才会触发window的计算
StructuredStreaming的输出模式可以参考
Flink中的window的触发
Flink中的window较Spark中有更加丰富的语义支持. Flink Window请参考
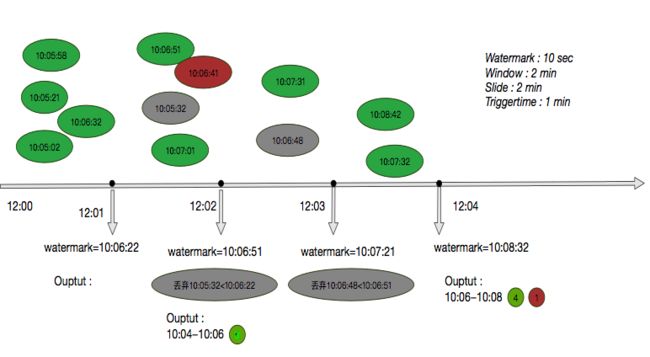
Flink中的window函数触发有两种途径 :
- watermark触发 : 接收到watermark后,当watermark > window.end && window内有消息
- 消息触发 : 消息到来,且对应window没有延迟, 即该window.end + allowlateness > watermark 且 watermark > window.end
消息延迟的判定 :
- 消息对应的window已经延迟,window.end + allowedLateness
- 消息本身延迟,消息的timestamp + allowedLateness
- 消息本身延迟,消息的timestamp + allowedLateness
如下图 :