本篇文章主要介绍Spark的内核架构,详细介绍从Saprk程序编写完成使用Spark submit(shell)的方式提交到完成任务的流程,为后续阅读Spark源码打下基础。
在这之前我也写过一篇文章Spark RDD核心详解,这篇文章也详细介绍了Spark的核心,因此本篇 文章主要是更细粒度来剖析其架构原理,对之前的文章的全面概述与总结。因此,对于Spark Core了解不够详细的读者可以先阅读之前的这篇文章,然后看下面的内容。
下面是Spark从启动到执行应用的架构图(Standalone模式)
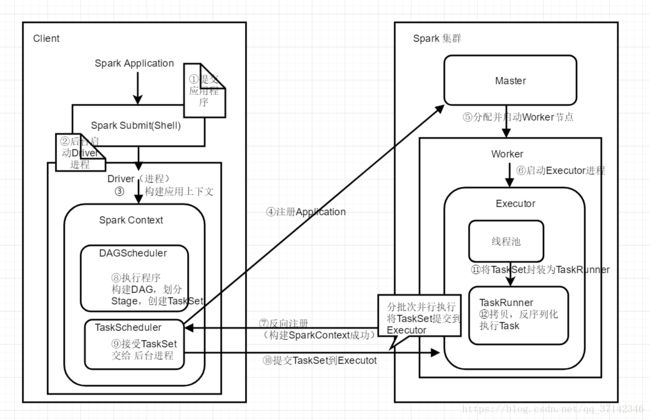
在我们日常开发中,我们常常会在IDEA中编写好Spark应用程序,然后打包到集群上执行,上面的这幅图就是Sstandalone模式提交应用执行的流程。
1. 首先是提交打包的应用程序,使用Spark submit或者spark shell工具执行。
2. 提交应用程序后后台会在后台启动Driver进程(注意:这里的Driver是在Client上启动,如果使用cluster模式提交任务,Driver进程会在Worker节点上启动)。
3. 开始构建Spark应用上下文。一般的一个Spark应用程序都会先创建一个Sparkconf,然后来创建SparkContext。如下代码所示:val conf=new SparkConf(); val sc=new SparkContext(conf)。在创建SparkContext对象时有两个重要的对象,DAGScheduler和TaskScheduler(具体作用后面会详细讲解)。
4. 构建好TaskScheduler后,它对应着一个后台进程,接着它会去连接Master集群,向Master集群注册Application。
5. Master节点接收到应用程序之后,会向该Application分配资源,启动一个或者多个Worker节点。
6. 每一个Worker节点会为该应用启动一个Executor进程来执行该应用程序。
7. 向Master节点注册应用之后,master为应用分配了节点资源,在Worker启动Executor完成之后,此时,Executo会向TaskScheduler反向注册,以让它知道Master为应用程序分配了哪几台Worker节点和Executor进程来执行任务。到此时为止,整个SparkContext创建完成。
8. 创建好SparkContext之后,继续执行我们的应用程序,每执行一个action操作就创建为一个job,将job交给DAGScheduler执行,然后DAGScheduler会将多个job划分为stage(这里涉及到stage的划分算法,比较复杂)。然后每一个stage创建一个TaskSet。
9. 实际上TaskScheduler有自己的后台进程会处理创建好的TaskSet。
10. 然后就会将TaskSet中的每一个task提交到Executor上去执行。(这里也涉及到task分配算法,提交到哪几个worker节点的executor中去执行)。
11. Executor会创建一个线程池,当executor接收到一个任务时就从线程池中拿出来一个线程将Task封装为一个TaskRunner。
12. 在TaskRunner中会将我们程序的拷贝,反序列化等操作,然后执行每一个Task。对于这个Task一般有两种,ShufflerMapTask和ResultTask,只有最后一个stage的task是ResultTask,其它的都是ShufflerMapTask。
13. 最后会执行完所有的应用程序,将stage的每一个task分批次提交到executor中去执行,每一个Task针对一个RDD的partition,执行我们定义的算子和函数,直到全部执行完成。
#总结
对于Spark架构流程的关键是理解上面的架构图,只有理解了Spark的内核架构,才能继续阅读源码或者去研究建立在Spark Core之上的Spark SQL,Spark Steaming,Spark MLlib等框架。
#