云妹导读:本文主要介绍了Wide&Deep、PNN、DeepFM、Wide&Resnet模型结构,并尝试在1688猜你喜欢的真实数据场景中进行应用。文内有一些实验结果,也提出了一些遇到的问题,希望能与大家一起分享讨论。
一、背景

猜你喜欢是推荐领域极其经典的一个场景,在1688首页无线端猜你喜欢栏目日曝光约23w,其中约72%的用户会产生点击行为,人均点击约8次。在我们的场景中,这部分是一个相对较大的流量来源。我们算法要做的就是通过用户的真实行为数据,预测用户最可能感兴趣的商品进行展示,以提高点击率,从而提高购买量。
不同于搜索,这种用户带有明确目的的行为,猜你喜欢是在用户没有明确目的时让用户“逛起来”,挖掘用户的潜在喜好商品,增强用户体验。

整个猜你喜欢的框架如图。用户产生的实时数据放在ABFS上,通过TPP传入BE,在BE中通过swing、c2i等算法召回1000个商品(粗排),再把这1000个商品通过TPP传入RTP中在线打分,最后把分数最高的600个商品按得分展现给用户(精排)。离线在Porsche平台上调试模型,调到最优结果再发布到RTP看线上效果。
ABFS (Ali Basic Feature Server),统一特征服务平台:该模块主要负责用户实时数据的处理以及特征的统计工作,如基础行为特征(点击、收藏、加购等),统计特征(点击次数、点击率等),并传递到TPP供BE系统调用;
TPP(The Personalization Platform),阿里个性化平台:集成RTP、IGraph、BE等常用服务,方便数据的流动调用,降低开发成本,帮助业务和算法快速上线迭代;
BE(Basic Engine),向量化召回。是DII上的一个为推荐场景定制的召回引擎服务,负责从多种类型的索引表中召回商品,并关联具体的商品信息进行过滤和粗排。线上召回效率极高,可以在几毫秒内对全库商品召回结果;
iGraph平台:超大规模分布式在线图存储和检索。在我们的流程中主要用来储存一些用户特征,用户偏好类目和热门商品召回等。因为这些信息不需要频繁更新,存到iGraph上方便存取和调用;
RTP(Real Time Prediction),实时打分服务系统:利用Swift增量传输模型,使用实时BUILD索引技术来实现特征和模型的秒级更新,RTP系统在收到TPP推荐系统的前端请求后,进行FG的实时特征产出,并对请求的item list中每个item计算出一个分值,是CTR、CVR各种机器学习模型预估的专用服务器;
Porsche在线学习平台: Porsche是基于Blink的分布式流式计算框架,提供了日志处理、特征计算和实时建模的插件接口。实时更新的模型和特征通过swift秒级别同步RTP等服务端。从用户发生交互行为、行为样本被实时系统接收和解析、加入在线训练、将更新的模型参数发送给服务端到最终新的推荐结果被用户感知,这个过程高度实时化、在线化。
二、模型简介
1. 搭积木

深度学习模型很大程度上来自不同基础模块的组合,通过不同方式组合不同模块,构建不同的模型。最经典的就是Google的Wide&Deep模型,结合深度模块DNN和线性模块LR,让模型同时拥有记忆性和泛化性。
在WDL之后,学术界和工业界在此结构上有很多其他的尝试。下面分析几个我试过的网络。
2. Wide&Deep

这是Google提出的非常经典的网络结构,论文见《Wide & Deep Learning for Recommender Systems》。离散特征经过Embedding和连续特征一起输入到DNN侧,Wide侧是一些人工交叉(如用笛卡尔积)特征,主要交叉的是id类特征,来学习特征间的共现。主要公式如下:
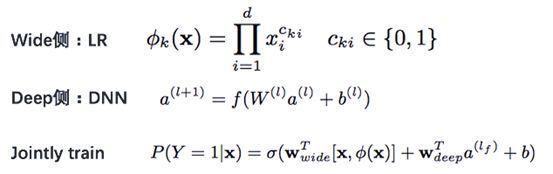
Wide侧LR模型的记忆性很强,比如用户买了一本科幻书,下一次再出现这样的组合,模型就会记住判断正确。但若此时来了一本科学书,LR模型不一定能分对,所以需要Deep侧DNN模型的补充。
Deep侧DNN模型通过Embedding层挖掘特征间的语义相关性,比如上个例子中,通过Embedding模型可以学到“科学”和“科幻”是相似的,从而也能推出用户也可能喜欢科学书。这样,通过DNN和LR模型的结合,Wide&Deep模型有很好的记忆性和泛化性。这也是我们目前猜你喜欢线上在用的模型。
3. PNN
PNN的思想来自于对MLP学习的交叉特征的补充,论文见《Product-based Neural Networks for User Response Prediction》。作者认为MLP不能很好地学出特征间的交叉关系,所以提出了一种product layer的思想,也就是基于乘法的运算强行显式地进行二阶特征交叉,结构如下图:

从结构图可以看出,product layer可以分成z和p两部分。线性部分z直接从Embedding结果得到,非线性部分也就是乘积部分,这里的乘积有两种选择,内积或者外积。

但这种结构的受限之处在于,它要求输入特征Embedding到相等的维度,因为维度相同才能做乘积运算。
4.DeepFM
DeepFM由华为诺亚方舟实验室和哈工大共同提出,论文见《DeepFM:A Factorization-Machine based Neural Network for CTR Prediction》。它的结构很像Wide&Deep与PNN的结合,它是把Wide&Deep中Wide侧的LR换成了乘积结构FM,通过FM和DNN分别提取低阶和高阶特征。而且这两部分共享Embedding输入。结构如下图:

FM部分是一个因子分解机。关于因子分解机可以参阅Steffen Rendle 在ICDM, 2010发表的文章《Factorization Machines》。因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,FM也可以很好的学习。FM的公式如下:

而且在FM的文章中,作者还给出了求解交叉项的化简公式:

跟PNN一样,因为FM强制特征间二阶交叉,所以需要把特征Embedding到相等长度的维度,且DeepFM结构两边的输入是共享的,不需要像Wide&Deep一样人工给LR模型构造交叉特征,节省了人力。但在集团实际应用中,不同特征的维度相差很大,比如性别只有3维(男、女、未知),而id类特征多达上亿维,不可能都Embedding到相同的长度。这里可以参考淘宝搜索团队的做法,通过Group product的方式分组Embedding:双11实战之大规模深度学习模型。他们在双十一中也取得了不错的效果。
5.Wide&Resnet
这个结构是我自己在工作中的尝试。想法来源于对Wide&Deep模型的改进,把原来Wide&Deep结构中DNN部分改成了一个类似Resnet那样skip connection的结构,也就是信号分成两路,一路还是经过两个relu层,另一路直接接到第二层relu,形成类似残差网络的结构。这样做的好处是,可以把不同层级的特征进行组合,丰富特征的信息量。两个模型的对比图如下:
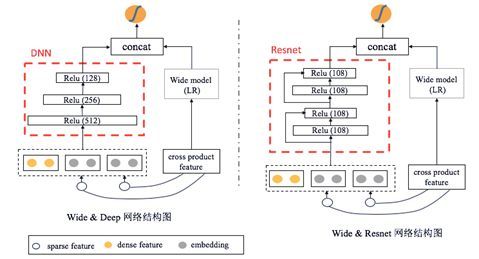
此外,我还发现单纯从DNN改到Resnet的结构并没有多少作用,但是在Resnet中加入batch normalization,即BN层后,网络的表达能力得到了很大的提高。可以从离线CTR实验的准确率中得以提现。离线效果见第四部分。

三、训练数据
训练数据来自目标日前七天内用户在1688首页猜你喜欢模块行为数据,曝光点击label为1,曝光未点击则label为0。
1688猜你喜欢使用的数据特征体系如下:

图中滑窗期指目标前1/3/5/7/15/30天的行为窗口。
1688平台与淘宝等传统的B2C平台不同,1688是一个B2B的平台,意味着我们的买家和卖家都是B类用户。B类用户与C类用户在特征上有明显的不同,比如:
B类用户特征会有是否是淘宝卖家;
相比于C类,B类用户没有年龄、性别、社会状态(是否有孩子、车子、房子)等人口统计学特征;
对于1688的商品也没有品牌特征,因为我们主打的是非品牌类的批发市场。
四、实验结果
在Porsche平台上做离线实验,可以看到带BN层的Wide&Resnet的模型比baseline的Wide&Deep模型在训练集和测试集上的AUC基本都要高1个多百分点。经过三次增量,即每批数据从上一次训练的模型基础上进一步迭代训练,AUC能提高5%~6%。
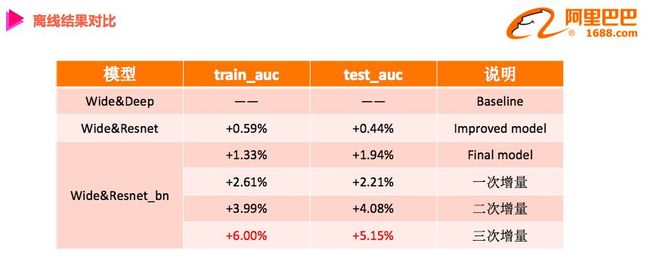
从loss曲线中更能明显看出,加了BN后的模型,loss基本在0.3之下,稳定在一个较小水平;而原来Wide&Deep模型的loss波动范围较大。所以BN对模型的稳定性起到了很明显的效果。

五、调参经验
分享一些其他的调参经验:

六、总结
本文在Wide&Deep模型上进行改进,提出Wide&Resnet结构,并通过Batch Normalization的方式大幅提升网络效果,是一次有意义的探索。
感谢霍博和CBU的算法小伙伴们一个多月的支持!以及特别感谢哈西师兄,易山师兄的指导!
关于我们
1688CBU事业部是阿里集团新零售事业群的核心部门,聚焦B类电商,建设B2B数据和业务闭环。CBU技术部新零售算法团队担负着技术创造新的业务价值的使命,我们已经将一系列深度模型应用于推荐、搜索、NLP、品类规划等领域,沉淀出一套有竞争力的技术体系,并且坚持在算法深度的道路上持续探索。
欢迎加入CBU技术部新零售算法团队!团队长年招聘搜索、推荐、NLP相关算法同学,有意向欢迎邮件至[email protected]
参考资料:
[1] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 2016.
[2] Qu, Yanru, et al. "Product-based neural networks for user response prediction." Data Mining (ICDM), 2016 IEEE 16th International Conference on. IEEE, 2016.
[3] Guo, Huifeng, et al. "Deepfm: a factorization-machine based neural network for ctr prediction." arXiv preprint arXiv:1703.04247 (2017).
[4] Rendle, Steffen. "Factorization machines." Data Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE, 2010.
了解更多
关注账号:阿里云科技快讯并私信小编接口暗号“Hello World”,云栖大会300份干货PPT属于你!