通过前面两篇文章我们对Android P下Actvity生命周期的分发有了一个总体认识,但我们仍然没有触及到对这些事件的感应,现在我们来看看android 框架是如何实现感应的。先添加如下代码
//因为使用的是java8,所以在build文件中添加如下依赖,这个依赖库目前就提供了一个DefaultLifecycleObserver接口
implementation 'androidx.lifecycle:lifecycle-common-java8:2.0.0'
添加类FirstLifecycleObserver 实现DefaultLifecycleObserver,DefaultLifecycleObserver继承自FullLifecycleObserver,后面会用到这一点
public class FirstLifecycleObserver implements DefaultLifecycleObserver {
private static final String TAG = "FirstLifecycleObserver";
@Override
public void onCreate(@NonNull LifecycleOwner owner) {
Log.d(TAG, "onCreate: ");
}
...
@Override
public void onDestroy(@NonNull LifecycleOwner owner) {
Log.d(TAG, "onDestroy: ");
}
}
MainActivity.java
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Log.d(TAG, "onCreate: ");
//添加生命周期的观察者
getLifecycle().addObserver(new FirstLifecycleObserver());
}
getLifecycle是接口LifecycleOwner的方法,ComponentActivity实现了此方法,返回的是LifecycleRegistry
ComponentActivity.java
private LifecycleRegistry mLifecycleRegistry = new LifecycleRegistry(this);
@Override
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
先看addObserver方法
LifecycleRegistry.java
@Override
public void addObserver(@NonNull LifecycleObserver observer) {
//开始mState 为INITIALIZED,所以initialState=INITIALIZED
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
ObserverWithState statefulObserver = new ObserverWithState(observer, initialState);
ObserverWithState previous = mObserverMap.putIfAbsent(observer, statefulObserver);
//如果已经存在直接返回
if (previous != null) {
return;
}
//使用的是弱引用
LifecycleOwner lifecycleOwner = mLifecycleOwner.get();
if (lifecycleOwner == null) {
// it is null we should be destroyed. Fallback quickly
return;
}
//目前没有重入
boolean isReentrance = mAddingObserverCounter != 0 || mHandlingEvent;
State targetState = calculateTargetState(observer);
mAddingObserverCounter++;
//一步一步将新添加的观察者状态提升到目标状态,此时不会执行 先忽略
while ((statefulObserver.mState.compareTo(targetState) < 0
&& mObserverMap.contains(observer))) {
pushParentState(statefulObserver.mState);
statefulObserver.dispatchEvent(lifecycleOwner, upEvent(statefulObserver.mState));
popParentState();
// mState / subling may have been changed recalculate
targetState = calculateTargetState(observer);
}
if (!isReentrance) {
// we do sync only on the top level.
sync();
}
mAddingObserverCounter--;
}
先看ObserverWithState的初始化,如前面强调的我们的Observer是FullLifecycleObserver类型,
所以返回FullLifecycleObserverAdapter
LifecycleRegistry.java
static class ObserverWithState {
//记录Observer的状态
State mState;
GenericLifecycleObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
mLifecycleObserver = Lifecycling.getCallback(observer);
mState = initialState;
}
}
Lifecycling.java
static GenericLifecycleObserver getCallback(Object object) {
if (object instanceof FullLifecycleObserver) {
//持有我们的引用
return new FullLifecycleObserverAdapter((FullLifecycleObserver) object);
}
...
}
FullLifecycleObserverAdapter.java
//持有观察者的引用
private final FullLifecycleObserver mObserver;
FullLifecycleObserverAdapter(FullLifecycleObserver observer) {
mObserver = observer;
}
一番折腾以后,两个字段都被赋值了

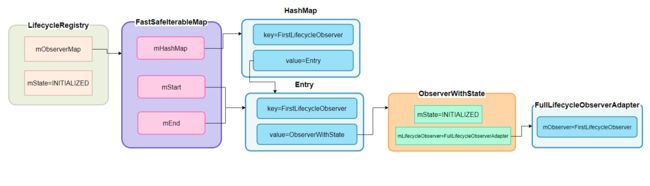
mObserverMap 从名字上看是一个Map,号称又快又安全
private FastSafeIterableMap mObserverMap =
new FastSafeIterableMap<>();
从源码可以看出它继承一个链表并组合了HashMap
public class FastSafeIterableMap extends SafeIterableMap {
private HashMap> mHashMap = new HashMap<>();
}
//名字叫Map,实际是一个链表
public class SafeIterableMap implements Iterable> {
Entry mStart;
private Entry mEnd;
}
回头我们看看putIfAbsent干了啥
FastSafeIterableMap.java
@Override
protected Entry get(K k) {
return mHashMap.get(k);
}
@Override
public V putIfAbsent(@NonNull K key, @NonNull V v) {
//调用的是上面mHashMap方法,第一次肯定返回null
Entry current = get(key);
if (current != null) {
return current.mValue;
}
//put(key, v)调用的是父类方法
mHashMap.put(key, put(key, v));
return null;
}
put(key, v)看着像Map存储操作其实是链表的插入操作
SafeIterableMap.java
protected Entry put(@NonNull K key, @NonNull V v) {
Entry newEntry = new Entry<>(key, v);
mSize++;
//第一次走这里,结束后mEnd 和mStart指向同一个Entry
if (mEnd == null) {
mStart = newEntry;
mEnd = mStart;
return newEntry;
}
//再添加就链接起来
mEnd.mNext = newEntry;
newEntry.mPrevious = mEnd;
mEnd = newEntry;
return newEntry;
}
//Entry就是双向链表的节点
static class Entry implements Map.Entry {
@NonNull
final K mKey;
@NonNull
final V mValue;
Entry mNext;
Entry mPrevious;
Entry(@NonNull K key, @NonNull V value) {
mKey = key;
this.mValue = value;
}
}
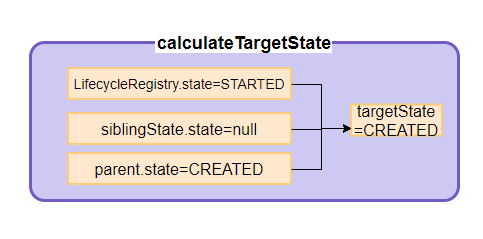
接下来就要计算目标状态,往mObserverMap添加的观察者有一个特性,后加的观察者其State值小于等于前面的,parentState 现在用不上,我们在后面讲,现在直接忽略掉,那目标状态就在mState和siblingState 之间选一个小的,如果mState小,那么新来的小于前面的,如果siblingState 小,那么新来的等于前面的,无论选择哪个都能保证这个特性。具体对null的处理看min方法。
private State calculateTargetState(LifecycleObserver observer) {
//获取当前观察者前面的那个观察者
Entry previous = mObserverMap.ceil(observer);
State siblingState = previous != null ? previous.getValue().mState : null;
//如果没有重入返回null 暂不考虑
State parentState = !mParentStates.isEmpty() ? mParentStates.get(mParentStates.size() - 1) : null;
//在三者之间取较小的作为目标状态,
return min(min(mState, siblingState), parentState);
}
和前面的图不同,下面的图表示关系而不是流程。至此观察者被添加,坐等通知,从第一篇的分析看,此时ReportFragment还没有分发onCreate事件。
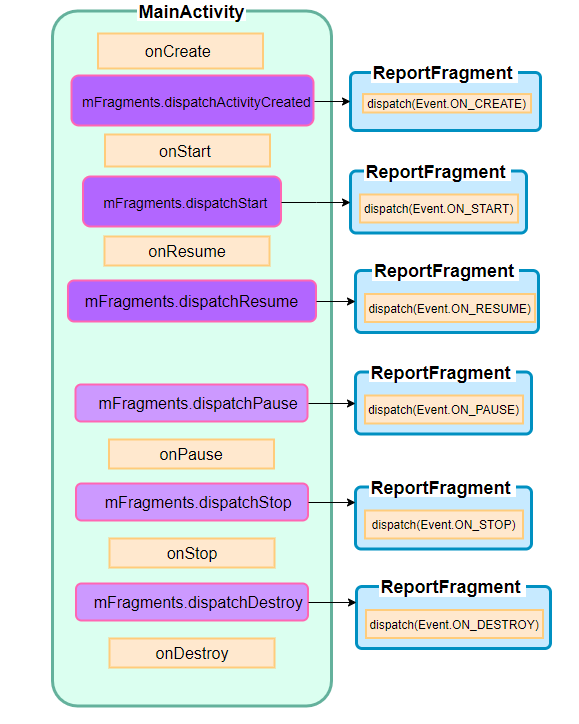
在handleLaunchActivity流程添加上addObserver方法后,整个流程一目了然,时刻注意你的操作在流程的哪个位置。现在我们接着dispatch方法往下看
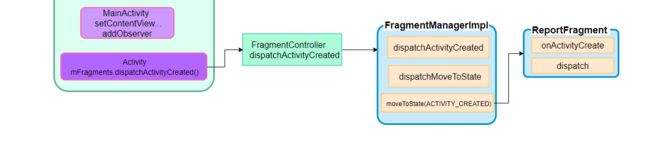
从第一篇可以看到在ComponentActivity的onCreate方法中ReportFragment被注入,所以ReportFragment持有MainActivity的引用,并且MainActivity是LifecycleOwner类型,因为ComponentActivity实现了LifecycleOwner,返回LifecycleRegistry
private void dispatch(Lifecycle.Event event) {
Activity activity = getActivity();
...
if (activity instanceof LifecycleOwner) {
//和在MainActivity中调用getLifecycle返回的是同一个
Lifecycle lifecycle = ((LifecycleOwner) activity).getLifecycle();
if (lifecycle instanceof LifecycleRegistry) {
((LifecycleRegistry) lifecycle).handleLifecycleEvent(event);
}
}
}
到此Lifecycle.Event.ON_CREATE事件被ReportFragment发到LifecycleRegistry,可以看出对生命周期事件的处理大体分两步,一:首先获取经过此次事件后应该进入的状态,二:移动到此状态即可。在进入具体分析之前,我们先看看几个Event和State之间的转换
//获取此事件之后的状态
static State getStateAfter(Event event) {
switch (event) {
case ON_CREATE:
case ON_STOP:
return CREATED;
case ON_START:
case ON_PAUSE:
return STARTED;
case ON_RESUME:
return RESUMED;
case ON_DESTROY:
return DESTROYED;
case ON_ANY:
break;
}
throw new IllegalArgumentException("Unexpected event value " + event);
}
//State向上升一级需要经历的事件
private static Event upEvent(State state) {
switch (state) {
case INITIALIZED:
case DESTROYED:
return ON_CREATE;
case CREATED:
return ON_START;
case STARTED:
return ON_RESUME;
case RESUMED:
throw new IllegalArgumentException();
}
throw new IllegalArgumentException("Unexpected state value " + state);
}
//State向下降一级需要经历的事件
private static Event downEvent(State state) {
switch (state) {
case INITIALIZED:
throw new IllegalArgumentException();
case CREATED:
return ON_DESTROY;
case STARTED:
return ON_STOP;
case RESUMED:
return ON_PAUSE;
case DESTROYED:
throw new IllegalArgumentException();
}
throw new IllegalArgumentException("Unexpected state value " + state);
}
我们以一张图来表示,可以形象的看出事件之后的状态,状态之间的事件,状态大小,理解其中转化关系很重要,否则很乱
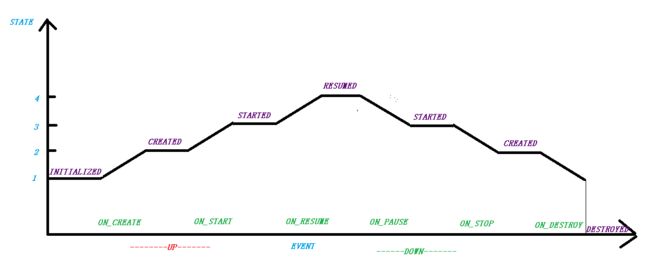
后面的内容基本都是:根据事件更新状态,根据状态变化分发事件
LifecycleRegistry.java
public void handleLifecycleEvent(@NonNull Lifecycle.Event event) {
State next = getStateAfter(event);
moveToState(next);
}
首先更新mState为CREATED,这个是LifecycleRegistry持有的状态,是观察者要迁移的目标。mHandlingEvent 和mAddingObserverCounter是对重入的考虑,对于此前简单的例子不用考虑,主要看sync同步方法
private void moveToState(State next) {
if (mState == next) {
return;
}
//更新为要进入的状态
mState = next;
if (mHandlingEvent || mAddingObserverCounter != 0) {
mNewEventOccurred = true;
return;
}
mHandlingEvent = true;
sync();
mHandlingEvent = false;
}
同步的工作就是如何把mObserverMap中的观察者状态同步到mState,首先通过isSynced判断是否同步,如果没有再通过backwardPass和forwardPass实现同步
private void sync() {
LifecycleOwner lifecycleOwner = mLifecycleOwner.get();
if (lifecycleOwner == null) {
Log.w(LOG_TAG, "LifecycleOwner is garbage collected, you shouldn't try dispatch "
+ "new events from it.");
return;
}
while (!isSynced()) {
mNewEventOccurred = false;
// no need to check eldest for nullability, because isSynced does it for us.
if (mState.compareTo(mObserverMap.eldest().getValue().mState) < 0) {
backwardPass(lifecycleOwner);
}
Entry newest = mObserverMap.newest();
if (!mNewEventOccurred && newest != null
&& mState.compareTo(newest.getValue().mState) > 0) {
forwardPass(lifecycleOwner);
}
}
mNewEventOccurred = false;
}
我们先看isSynced,判断的标准就是mObserverMap中,第一个和最后一个观察者及当前的mState是否一样,目前只有一个,state为INITIALIZED,需要同步
private boolean isSynced() {
if (mObserverMap.size() == 0) {
return true;
}
State eldestObserverState = mObserverMap.eldest().getValue().mState;
State newestObserverState = mObserverMap.newest().getValue().mState;
return eldestObserverState == newestObserverState && mState == newestObserverState;
}
// mObserverMap.eldest()返回的是链表的头
public Map.Entry eldest() {
return mStart;
}
// mObserverMap.eldest()返回的是链表的尾
public Map.Entry newest() {
return mEnd;
}
再来看看backwardPass和forwardPass的执行条件,mStart指定第一个观察者,mEnd指向最后一个,如果mState比第一观察者也就是状态最大的还要大,执行forwardPass,同理backwardPass。现在指向的都是同一个观察者。这里的mState是枚举值,(mState=CREATED=2)>(mStart.mState=INITIALIZED=1),这里只执行forwardPass,backwardPass作用类似。
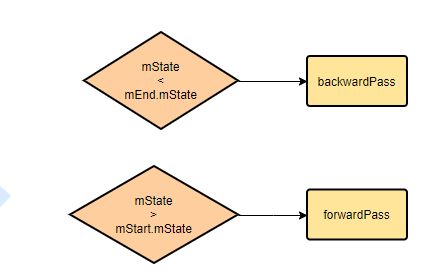
使用iteratorWithAdditions迭代器从链表的mStart开始往mEnd遍历观察者,处理观察者的状态和当前状态:分发事件、更新观察者状态直到和当前状态平衡
private void forwardPass(LifecycleOwner lifecycleOwner) {
Iterator> ascendingIterator =
mObserverMap.iteratorWithAdditions();
while (ascendingIterator.hasNext() && !mNewEventOccurred) {
//参考图示,很容易看出Entry里面的关系
Entry entry = ascendingIterator.next();
ObserverWithState observer = entry.getValue();
while ((observer.mState.compareTo(mState) < 0 && !mNewEventOccurred
&& mObserverMap.contains(entry.getKey()))) {
pushParentState(observer.mState);
observer.dispatchEvent(lifecycleOwner, upEvent(observer.mState));
popParentState();
}
}
}

目前只有一个观察者,没有新事件mNewEventOccurred=false,观察者的mState还是INITIALIZED小于CREATED,没有重入不需要关心pushParentState、popParentState,直接进入observer.dispatchEvent,在进入之前,观察者的状态被upEvent转化了一次,意思就是此状态要提升一级会收到什么样的事件。
我们知道此次分发的是ON_CREATE事件,为什么不直接传?因为我们是在onCreate中添加观察者的,所以问题不明显,如果我们在onResume中添加,直接传就是ON_RESUME事件,那我们的观察者就会漏掉前面的ON_CREATE和ON_START事件。这也是为什么要在while循环中分发事件,因为不是一步到位的,是一步一步迁移的。dispatchEvent干了两件事,把事件发给观察者然后更新观察者状态
void dispatchEvent(LifecycleOwner owner, Event event) {
//同样为观察者计算此次事件后的状态
State newState = getStateAfter(event);
mState = min(mState, newState);
mLifecycleObserver.onStateChanged(owner, event);
mState = newState;
}
如前文所述mLifecycleObserver实例为FullLifecycleObserverAdapter,并且持有我们观察者的引用,在这里我们的观察者终于等来事件通知。
FullLifecycleObserverAdapter.java
@Override
public void onStateChanged(LifecycleOwner source, Lifecycle.Event event) {
switch (event) {
case ON_CREATE:
mObserver.onCreate(source);
break;
//雷同
...
}
}
目前的流程应该是最简单的一种,如果不是在onCreate阶段添加观察者,那么在addObserver方法中添加观察者后就会立马更新观察者到目标状态。
如果仅仅在Activity中添加或删除观察者,源码也不会有重入的判断还有pushParentState、popParentState等奇怪操作。所以我们看一个复杂的情况,在前面的基础上再添加一个观察者SecondLifecycleObserver
public class SecondLifecycleObserver implements DefaultLifecycleObserver {
private static final String TAG = "SecondLifecycleObserver";
@Override
public void onCreate(@NonNull LifecycleOwner owner) {
Log.d(TAG, "onCreate: ");
}
...
@Override
public void onDestroy(@NonNull LifecycleOwner owner) {
Log.d(TAG, "onDestroy: ");
}
}
更改FirstLifecycleObserver的代码如下,从LifecycleRegistry移除自己再添加SecondLifecycleObserver
FirstLifecycleObserver.java
@Override
public void onStart(@NonNull LifecycleOwner owner) {
Log.d(TAG, "onStart: ");
owner.getLifecycle().removeObserver(this);
owner.getLifecycle().addObserver(new SecondLifecycleObserver());
}
就前面的分析,onCreate流程应该是这个样子,需要注意的是Observer的状态在onstateChange方法之后才会更新

再看onStart事件的分发,与上一个forwardPass方法不同,这里我们标记了pushParentState,不是上一次没有而是用不上,在FirstObserver的onStart方法里先移除了自己再添加了SecondObserver,所以FirstObserver还没来得及升级到STARTED状态就挂了。
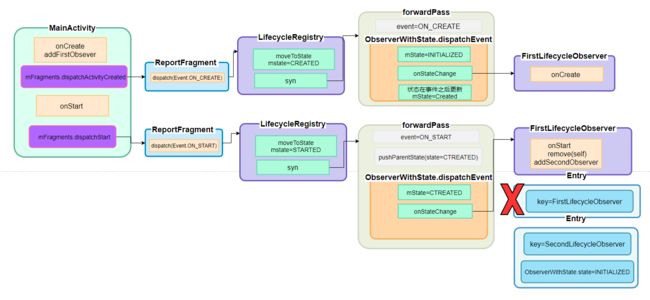
再看addObserver,现在是mHandlingEvent = true的状态进入,就是重入状态
LifecycleRegistry.java
@Override
public void addObserver(@NonNull LifecycleObserver observer) {
....
//现在就是重入状态
boolean isReentrance = mAddingObserverCounter != 0 || mHandlingEvent;
//为observer计算目标状态
State targetState = calculateTargetState(observer);
mAddingObserverCounter++;
//如果observer没有达到目标状态,持续迁移
while ((statefulObserver.mState.compareTo(targetState) < 0
&& mObserverMap.contains(observer))) {
pushParentState(statefulObserver.mState);
statefulObserver.dispatchEvent(lifecycleOwner, upEvent(statefulObserver.mState));
popParentState();
// mState / subling may have been changed recalculate
targetState = calculateTargetState(observer);
}
if (!isReentrance) {
// we do sync only on the top level.
sync();
}
mAddingObserverCounter--;
}
再看calculateTargetState方法,由于前面FirstObserver被移除了,state为null,如果没有使用pushParentState记录FirstObserver状态,那么返回的目标状态就是STARTED,这样SecondObserver就会连续触发onCreate和onStart,但此时FirstObserver的onstateChange还没执行完,状态还没升到STARTED,导致后加的SecondObserver状态越界,使用parentState起到限制作用。在这个addObserver方法中SecondObserver只会被提到CREATED状态,随后的循环才会分发SecondObserver的onStart事件和提升状态。
现在看mObserverMap.contains(entry.getKey())这种判断是有道理的,这种在遍历过程中支持添加和删除的数据结构也是牛叉的。到此大部分的方法都分析了,其它生命周期的情况大同小异。根据前文的分析,我们简化成下图
最后强烈建议大家使用断点调试来跟踪,我还写了一首歌:
断点调试好
断点调试妙
断点调试呱呱叫
嘿!呱呱叫!
