导读:本文将描述 Apache Druid 的基本集群架构,说明架构中各进程的作用。并从数据写入和数据查询两个角度来说明 Druid 架构的工作流程。
关注公众号 MageByte,设置星标点「在看」是我们创造好文的动力。公众号后台回复 “加群” 进入技术交流群获更多技术成长。
Druid 是多进程架构,每种进程类型都可以独立配置,独立扩展。这样可以为集群提供最大的灵活度。这种设计还提供了强失效容忍:一个失效的组件不会立即影响另外的组件。
下面我们来深入了解 Druid 有哪些进程类型,每种进程又在整个集群中扮演什么角色。
进程和服务(Process and Servers)
Druid 有多种进程类型,如下:
- Coordinator进程在集群中负责管理数据可用。
- Overlord进程控制数据摄入的资源负载分配。
- Broker进程处理外部客户端的查询。
- Router进程是可选的,它可以路由请求到 Brokers,Coordinator,和 Overlord。
- Historical进程存储可查询的数据。
- MiddleManager进程负责数据摄入。
你可以以任何方式来部署上面的进程。但是为了易于运维,官方建议以下面三种服务类型来组织进程:Master、Query 和 Data。
- Master:运行 Coordinator 和 Overlord 进程,管理数据可用和数据写入。
- Query: 运行 Broker 和可选的 Router 进程,负责处理外部查询请求。
- Data:运行 Historical 和 MiddleManager 进程,负责执行数据写入任务并存储可查询的数据。
外部依赖(External dependencies)
除了内置的进程类型,Druid 还有三个外部依赖项。
Deep storage
共享文件存储,只要配置成允许 Druid 访问即可。在集群部署中,通常使用分布式存储(如 S3 或 HDFS)或挂载网络文件系统。在单机部署中,通常使用本地磁盘。Druid 使用 Deep Storage 存储写入集群的数据。
Druid 仅将 Deep Storage 用作数据的备份,并作为 Druid进程间在后台的数据传输方式。要响应查询,Historical 进程并不从 Deep Storage 上读取数据,在任何查询之前,先从本地磁盘查询已经存在的数据。这意味着,Druid 在查询时并不需要访问 Deep Storage,这样就可以得到最优的查询延迟。这也意味着,在 Deep Storage 和 Historical 进程间你必须有足够的磁盘空间来存储你计划加载的数据。
Deep Storage 是 Druid 弹性、容错设计的重要组成部分。如果 Druid 单机进程本地数据丢失,可以从 Deep Storage 恢复数据。
Metadata storage
元数据存储,存储各种共享的系统元数据,如 segment 可用性信息和 task 信息。在集群部署中,通常使用传统的 RDBMS,如 PostgreSQL 或 MySQL。在单机部署中,通常使用本地存储,如 Apache Derby 数据库。
Zookeeper
用来进行内部服务发现,协调,和主选举。
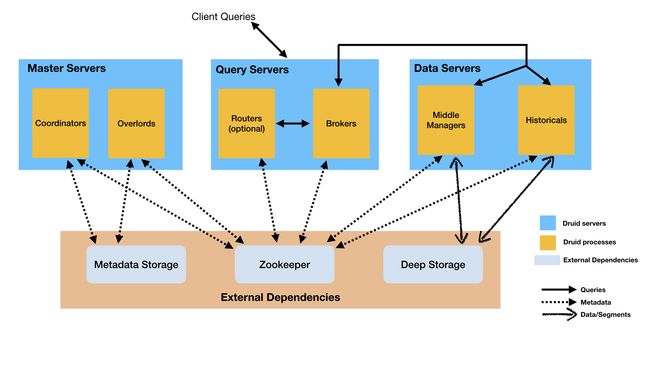
架构图(Architecture diagram)
下图可以看出使用官方建议的 Master/Query/Data 服务部署方式,查询和写入数据是如何进行的:
存储设计(Storage design)
Datasources and segments
Druid 数据存储在"datasources"中,它就像 RDBMS 中的 table。每一个 datasources 通过时间分区,或通过其他属性进行分区。每一个时间范围称之为"chunk"(比如,一天一个,如果你的 datasource 使用 day 分区)。在 chunk 中,数据被分区进一个或多个"segments"中。每一个 segment 是一个单独的文件,通常包含数百万行数据。一旦 segment 被存储进 chunks,其组织方式将如以下时间线所示:
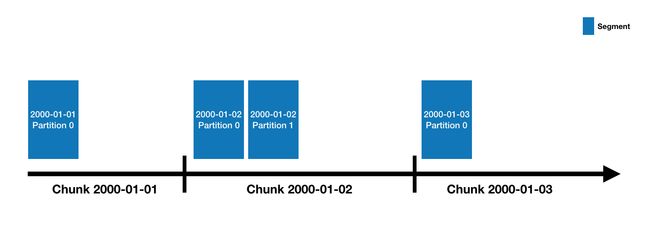
一个 datasource 也许只有一个,也可能有数十万甚至上百万个 segment。每个 segment 生命周期开始于 MiddleManager 创建时,刚被创建时,segment 是可变和未提交的。segment 构建过程包含以下几步,旨在生成结构紧凑并支持快速查询的数据文件。
- 转换成列格式
- 使用 bitmap 创建索引
- 使用各种算法压缩数据
- 为 String 列做字典编码,用最小化 id 存储
- 对 bitmap 索引做 bitmap 压缩
- 对所有列做类型感知压缩
segment 定时提交和发布。此时,数据被写入 Deep Storage,并且再不可变,并从 MiddleManagers 进程迁移至 Historical 进程中。一个关于 segment 的 entry 将写入 metadata storage。这个 entry 是关于 segment 的元数据的自描述信息,包含如 segment 的数据模式,大小,Deep Storage 地址等信息。这些信息让 Coordinator 知道集群中哪些数据是可用的。
索引和移交(Indexing and handoff)
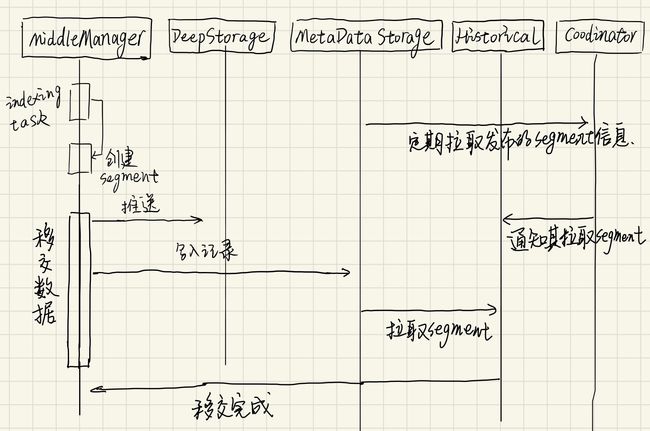
indexing 是每个 segment 创建的机制。handoff 是数据被发布并开始可以被 Historical 进程处理的机制。这机制在 indexing 侧的工作顺序如下:
- 启动一个 indexing task 并构建一个新的 segment。在构建之前必须先确定其标识。对于一个追加任务(如 kafka 任务,或 append 模式任务)可以调用 Overlord 的"allocate"API 来将一个潜在的新分区加入到一个已经存在的 segment 中。对于一个覆写任务(如 Hadoop 任务,或非 append 模式 index 任务) 将为 interval 创建新版本号和新 segment。
- 如果 indexing 任务是实时任务(如 Kafka 任务),此时 segment 可以立即被查询。数据是可用的,但还是未发布状态。
- 当 indexing 任务完成读取 segment 数据时,它将数据推送到 Deep Storage 上,并通过向 metadata store 写一个记录来发布数据。
- 如果 indexing 任务是实时任务,此时,它将等待 Historical 进程加载这个 segment。如果 indexing 任务不是实时任务,就立即退出。
这机制在 Coordinator/Historical 侧的工作如下:
- Coordinator 定期从 metadata storage 拉取已经发布的 segments(默认,每分钟执行)。
- 当 Coordinate 发现已发布但不可用的 segment 时,它将选择一个 Historical 进程去加载 segment,并指示 Historical 该做什么。
- Historical 加载 segment 并为其提供服务。
- 此时,如果 indexing 任务还在等待数据移交,就可以退出。
数据写入(indexing)和移交(handoff):
段标识(Segment identifiers)
Segment 标识由下面四部分组成:
- Datasource 名称。
- 时间间隔(segment 包含的时间间隔,对应数据摄入时
segmentGranularity指定参数)。 - 版本号(通常是 ISO8601 时间戳,对应 segment 首次生成时的时间)。
- 分区号(整数,在 datasource+interval+version 中唯一,不一定是连续的)。
例如,这是 datasource 为clarity-cloud0,时间段为2018-05-21T16:00:00.000Z/2018-05-21T17:00:00.000Z,版本号为2018-05-21T15:56:09.909Z,分区号为 1 的标识符:
clarity-cloud0_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T15:56:09.909Z_1
分区号为 0(块中的第一个分区)的 segment 省略了分区号,如以下示例所示,它是与前一个分区在同一时间块中的 segment,但分区号为 0 而不是 1:
clarity-cloud0_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T15:56:09.909Z
段版本控制(segment versioning)
你可能想知道上一节中描述的“版本号”是什么。
Druid 支持批处理模式覆写。在 Driud 中,如果你要做的只是追加数据,那么每个时间块只有一个版本。但是,当你覆盖数据时,在幕后发生的事情是使用相同的数据源,相同的时间间隔,但版本号更高的方式创建了一组新的 segment。这向 Druid 系统的其余部分发出信号,表明应从群集中删除较旧的版本,而应使用新版本替换它。
对于用户而言,切换似乎是瞬间发生的,因为 Druid 通过先加载新数据(但不允许对其进行查询)来处理此问题,然后在所有新数据加载完毕后,立即将新查询切换到新 segment。然后,它在几分钟后删除旧 segment。
段(segment)生命周期
每个 segment 的生命周期都涉及以下三个主要领域:
- 元数据存储区:一旦构建完 segment,就将 segment 元数据(小的 JSON 数据,通常不超过几个 KB)存储在
元数据存储区中。将 segmnet 的记录插入元数据存储的操作称为发布。然后将元数据中的use布尔值设置成可用。由实时任务创建的 segment 将在发布之前可用,因为它们仅在 segment 完成时才发布,并且不接受任何其他数据。 - 深度存储:segment 数据构建完成后,并在将元数据发布到元数据存储之前,立即将 segment 数据文件推送到深度存储。
- 查询的可用性:segment 可用于在某些 Druid 数据服务器上进行查询,例如实时任务或Historical进程。
你可以使用 Druid SQL sys.segments表检查当前 segment 的状态 。它包括以下标志:
is_published:如果 segment 元数据已发布到存储的元数据中,used则为 true,此值也为 true。is_available:如果该 segment 当前可用于实时任务或Historical查询,则为 True。is_realtime:如果 segment 在实时任务上可用,则为 true 。对于使用实时写入的数据源,通常会先设置成true,然后随着 segment 的发布和移交而变成false。is_overshadowed:如果该 segment 已发布(used设置为 true)并且被其他一些已发布的 segment 完全覆盖,则为 true。通常,这是一个过渡状态,处于此状态的 segment 很快就会将其used标志自动设置为 false。
查询处理
查询首先进入Broker进程,Broker将得出哪些 segment 具有与该查询有关的数据(segment 列表始终按时间规划,也可以根据其他属性来规划,这取决于数据源的分区方式),然后,Broker将确定哪些 Historical 和 MiddleManager 正在为这些 segment 提供服务,并将重写的子查询发送给每个进程。Historical / MiddleManager 进程将接受查询,对其进行处理并返回结果。Broker接收结果并将它们合并在一起以得到最终答案,并将其返回给客户端。
Broker会分析每个请求,优化查询,尽可能的减少每个查询必须扫描的数据量。相比于 Broker 过滤器做的优化,每个 segment 内的索引结构允许 Druid 在查看任何数据行之前先找出哪些行(如果有)与过滤器集匹配。一旦 Druid 知道哪些行与特定查询匹配,它就只会访问该查询所需的特定列。在这些列中,Druid 可以在行与行之间跳过,从而避免读取与查询过滤器不匹配的数据。
因此,Druid 使用三种不同的技术来优化查询性能:
-
检索每个查询需访问的 segment。
-
在每个 segment 中,使用索引来标识查询的行。
-
在每个 segment 中,仅读取与特定查询相关的行和列。
其他系列文章链接
时间序列数据库(TSDB)初识与选择
十分钟了解 Apache Druid
想了解更多数据存储,时间序列,Druid 的知识,可关注我的公众号。点「在看」是我们创造好文的动力