1,概述
模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断)。
常见的模型压缩算法有:量化,剪枝,蒸馏,低秩近似以及紧凑模型设计(如mobileNet)等操作。但在这里有些方法只能起到缩减模型大小,而起不到加速的作用,如稀疏化剪枝。而在现代的硬件设备上,其实更关注的是模型推断速度。今天我们就讲一种既能压缩模型大小,又能加速模型推断速度:量化。
量化一般可以分为两种模式:训练后的量化(post training quantizated)和训练中引入量化(quantization aware training)。
训练后的量化理解起来比较简单,将训练后的模型中的权重由float32量化到int8,并以int8的形式保存,但是在实际推断时,还需要反量化为float类型进行计算。这种量化的方法在大模型上表现比较好,因为大模型的抗噪能力很强,但是在小模型上效果就很差。
训练中引入量化是指在训练的过程中引入伪量化操作,即在前向传播时,采用量化后的权重和激活,但是在反向传播时仍是对float类型的权重做梯度更新;在预测时将全部采用int8的方式进行计算。
注:模型除了可以量化到int8之外,还可以量化到float16,int4等,只是在作者看来量化到int8之后,能保证压缩效果和准确率损失最优。
2,quantization aware training
论文:Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
quantization aware training技术来源于上面这篇论文,现在在tensorflow和pytorch中都提供了相应的接口。
作者在本文中提供了一种将float32量化到int8的策略,并给出了一个推断框架和训练框架,推断框架让模型可以有效的整数运算硬件上运行,训练框架和推断框架相辅相成,可以降低精度的损失。我们先来看看推断框架:
Quantizated Inference
1, Quantization scheme
首先定义q为量化值,r为真实浮点值。本文抛弃了之前采用查找表的方式将浮点值映射到整数值,而是引入了一个映射关系来表示,公式如下:
![]()
上面式子中S为缩放稀疏,Z为"Zero-Point",其实Z就是真实浮点值0映射到整数时对应的值,这个值的存在是有一定意义的,因为无论是在图像中还是NLP中都会有用0做padding值来补全的,映射到整数后,也应该有这样一个值的存在,这个值就是Z。在这里S和Z可以称为量化参数,对于每个权重矩阵和每个激活数组都有一对这样的值。
用C++中的结构体来表示这个数据结构的话,如下:

在这里QType既可以是int8,也可以是float16,int4等。
2,Integer-arithmetic-only matrix multiplication
对于两个浮点数矩阵之间的运算,可以全部转换成整数运算,公式如下:
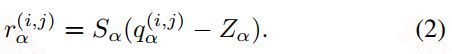
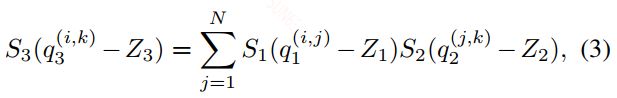


在上面的式子中只有M是一个浮点数,所以这里会有一个浮点运算,作者在这里好像为了避开浮点运算,做了下面一个操作,但没怎么看懂,有兴趣的可以自己。
![]()
3,Efficient handling of zero-points
个人理解在上面的式子4中因为两个矩阵都需要减去相应的Z值,减法运算之后得到的值有可能会突破int8的范围,到时候就需要int16来存储,但整个运算为了控制在int8的类型下计算,作者做了下面的变换。至于作者提到的2N^3的计算复杂度,即使转换完之后还是存在的,这个复杂度就是两个矩阵的计算复杂度。
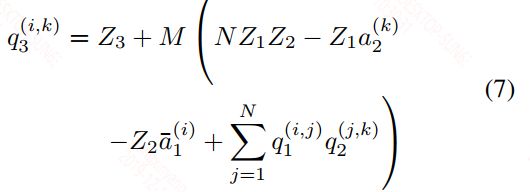
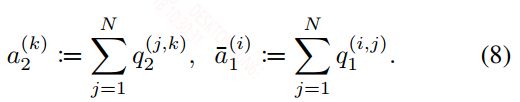
4,Implementation of a typical fused layer
上面的描述了权重的矩阵运算,但除此之外在一个神经网络中还含有bias和激活函数的映射,因为int8类型的矩阵运算完之后的值应该是在int32之内的,所以bias选择int32的类型,这样的选择一是因为bias在整个神经网络中只占据极少的一部分,此外bias的作用其实非常重要,高精度的bias可以降低模型的偏差。因此加上bias之后就变成了int32,我们需要再次转换成int8类型,之后再进入到激活中。具体如下图所示:
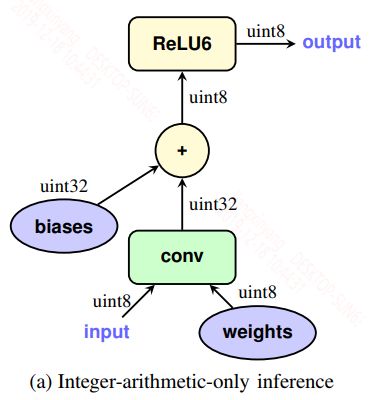
Training with simulated quantization
为什么要采用这种量化策略,前面也说了对于大模型采用post training quantizated的方法是可以的,但是小模型容易导致精度损失较大。具体的量化策略如下:
1,weights再输入进行卷积之前就开始量化,如果有bn层,将bn层融入到weights中。
2,激活在激活函数执行完之后再量化。
具体的如下如所示:
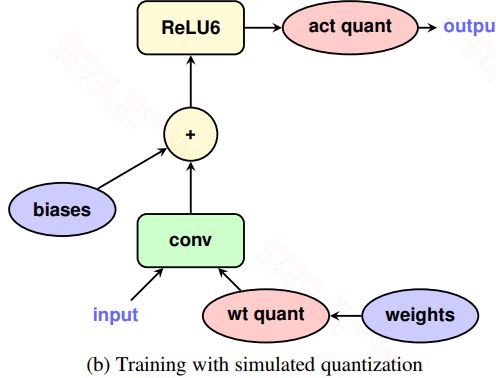
具体的量化公式如下:
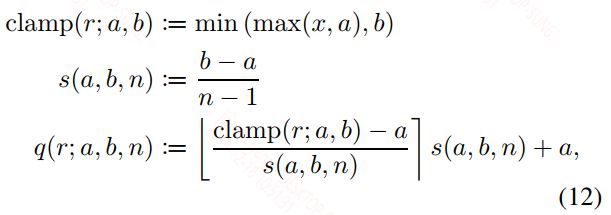
也是min-max的方式,上面式子中(a, b)是针对浮点数的量化范围,n可以理解为对于int8,$n = 2^8$。上面的⌊·⌉ 其实是一个将浮点数转为最近且小于它的整数的符号,该符号内部就是量化函数。
1,Learning quantization ranges
对于上面的量化范围(a, b),weight和activation是不一样的,对于weight来说很简单,就是该权重中最大最小值,但是对于activation是不太一样的, 对于activation采用了EMA(滑动平均)来对输入中的最大最小值计算得到的,但是在训练初期,因为输入的值变化较大,会影响到滑动平均的值,因此在初期不对activation做量化,而是在网络稳定之后再引入。具体量化算法如下:

2,Batch normalization folding
对于bn层,在训练时是一个单独的层存在,但是在推断时为了提升效率是融合到卷积或全连接层的权重和偏置中的,如下图:
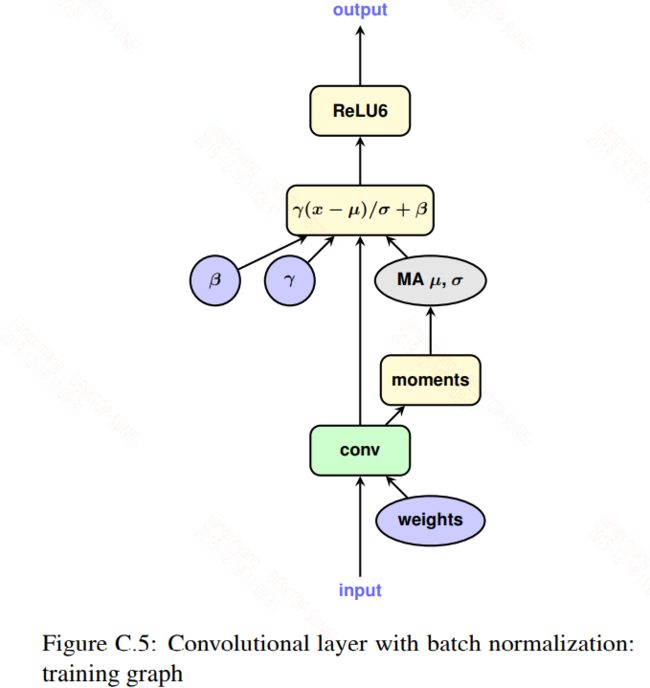
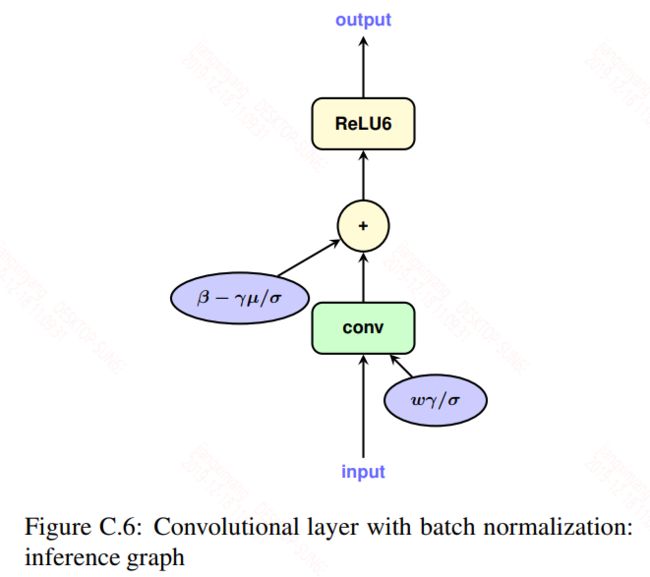
为了模拟推断,训练时需要将bn层考虑进权重,然后再做量化。具体公式如下:
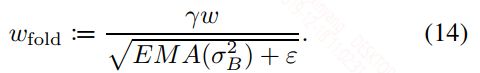
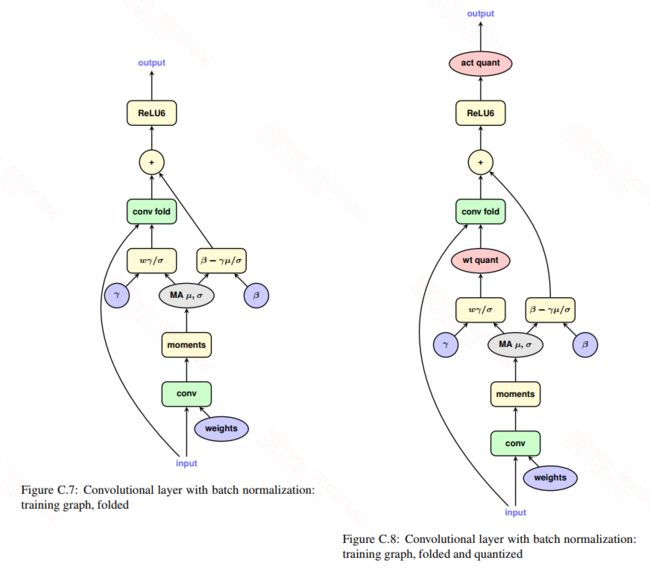
参考文献:
Quantizing deep convolutional networks for efficient inference: A whitepaper
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference