最近在做时间序列异常值检测,除了常规的统计学算法以外,也想尝试通过机器学习或深度学习的方式去解决问题。
于是想,可不可以直接使用一个拟合效果非常棒的模型先去预测该时间序列的未来走势,再将预测后的值(predict_value)当前值(value)做对比,只要超过一定阈值就判定该值为异常值。
尝试了xgboost、ARIMA 和 LSTM 三者中,拟合效果最好的是LSTM,简单记录一下建模和调参过程。
1.加载数据:源数据结构如下,只要 y 值。


2.加载数据,由于我这里代表时间的字段是从piontStart里面拿出去,并且需要去掉最后'000'再用time.localtime()转换成时间戳,不是重点,简单看一下就行。

3.准备训练和测试数据



4.建模阶段




5.训练阶段

这里有我之前调参时的Train_Score 和 Test_Score 对比记录
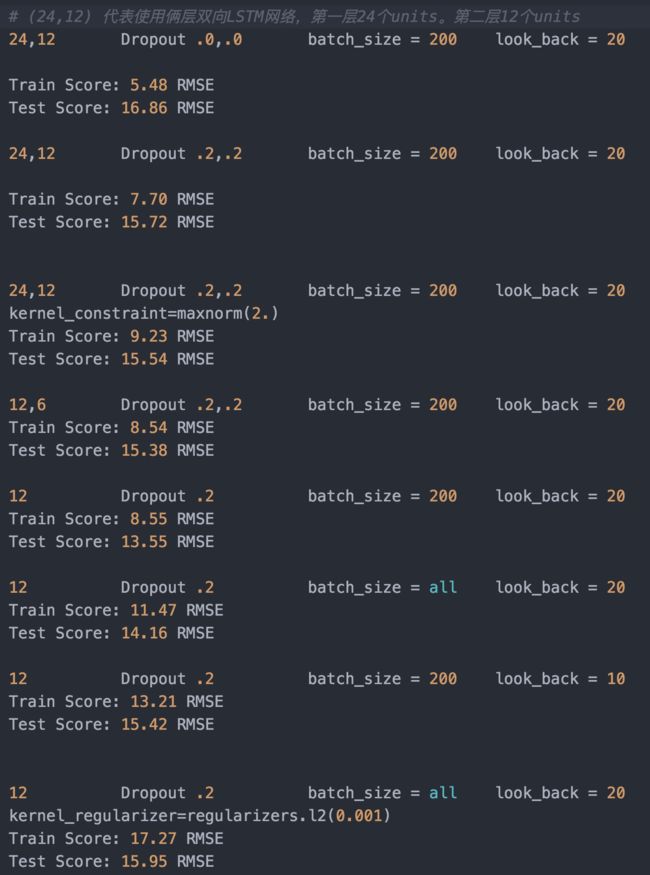

可以看到,使用双层结构的 LSTM 有非常严重的过拟合现象发生,单层LSTM已经可以很好的对时间序列进行拟合
batch_size 的大小也会对模型的收敛产生不小的影响
look_back(即 time_step) 的大小会对过拟合的程度造成很大影响,如果步长取的太短也会造成过拟合
6.画图查看训练集和测试集拟合效果


7. 双向LSTM 增量学习
可以看到双向 LSTM 在 训练集和测试集的拟合能力都非常出色。
但即便如此,LSTM在时序预测的问题上仍然存在很多不足(无法预测没有在Train_Data出出现过的值)。
而且LSTM的误差会随着时间的推移越来越大(前N个值每个值都存在一定的误差,再用前N个带有误差的预测值去预测第N+1个,结果可想而知)
为了尝试解决上述问题,尝试增量学习的方式。
LSTM 中 增量方法非常简单。
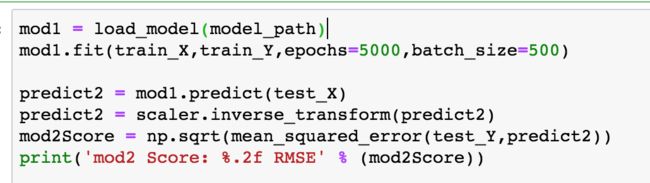
8.我尝试使用一个新的数据集 zhengbao2.json 来对比原始model(mod1) 和 增量后的模型(mod2) 分别对同一份数据进行预测,对比它们的MSE





可以看到,单从测试集来看,增量后模型能拟合更多情况的发生,但是总体误差也随之上升。
模型的训练也可以看出,虽然经过了5000轮的epochs,但是loss基本没有下降,这可能需要我们动态的调整batch_size,但是如果模型需要部署在客户的环境中,而不是在本地,就很难实现
手动调整参数,需要根据业务场景和数据的分布情况指定通用性更强的参数。
第一次写的比较潦草,希望对异常检测感兴趣的朋友多提宝贵意见。