Facebook 60TB+级的Apache Spark应用案例 里大体有两方面的PR,一个是Bug Fix,一个是性能优化。这篇文章会对所有提及的Bug Issue进行一次解释和说明。也请期待下一篇。
前言
Facebook 60TB+级的Apache Spark应用案例,本来上周就准备看的,而且要求自己不能手机看,要在电脑上细细的看。然而终究是各种忙拖到了昨天晚上。
文章体现的工作,我觉得更像是一次挑战赛,Facebook团队通过层层加码,最终将单个Spark Batch实例跑到了60T+ 的数据,这是一个了不起的成就,最最重要的是,他们完成这项挑战赛后给社区带来了三个好处:
- 在如此规模下,发现了一些Spark团队以前很难发现的Bug
- 提交了大量的bug fix 和 new features,而且我们可以在Spark 1.6.2 /Spark 2.0 里享受到其中的成果
- 在如此规模下,我们也知道我们最可能遇到的一些问题。大体是OOM和Driver的限制。
说实在的,我觉得这篇文章,可以算是一篇工程论文了。而且只用了三个人力,不知道一共花了多久。
值得注意的是,大部分Bug都是和OOM相关的,这也是Spark的一个痛点,所以这次提交的PR质量非常高。
Bug 剖析
Make PipedRDD robust to fetch failure SPARK-13793
这个Issue 还是比较明显的。PipedRDD 在Task内部启动一个新的Java进程(假设我们叫做ChildProcessor)获取数据。这里就会涉及到三个点:
- 启动一个线程往 ChildProcessor 写数据 (stdin writer)
- 启动一个线程监控ChildProcessor的错误输出 (stderr reader)
- 获取ChildProcessor输入流,返回一个迭代器(Iterator)
既然都是读取数据流,如果数据流因为某种异常原因关闭,那必然会抛出错误。所以我们需要记录这个异常,对于1,2 两个我们只要catch住异常,然后将异常记录下来方便后续重新抛出。 那么什么时候抛出呢?迭代器有经典的hasNext/next方法,每次hasNext时,我们都检查下是否有Exception(来自1,2的),如果有就抛出了。既然已经异常了,我们就应该不需要继续读取这个分区的数据了。否则数据集很大的情况下,还要运行很长时间才能运行完。
在hasNext 为false的情况下,有两类情况,一类是真的没有数据了,一类是有异常了,比如有节点挂了,所以需要检测下ChildProcessor的exitStatus状态。如果不正常,就直接抛出异常,进行重试。
对于1,2两点,原来都是没有的,是这次Facebook团队加上去的。
Configurable max number of fetch failures SPARK-13369
截止到我这篇文章发出,这个Issue 并没有被接收。
我们知道,Shuffle 发生时,一般会发生有两个Stage 产生,一个ShuffleMapStage (我们取名为 MapStage),他会写入数据到文件中,接着下一个Stage (我们取名为ReduceStage) 就会去读取对应的数据。 很多情况下,ReduceStage 去读取数据MapStage 的数据会失败,可能的原因比如有节点重启导致MapStage产生的数据有丢失,此外还有GC超时等。这个时候Spark 就会重跑这两个Stage,如果连续四次都发生这个问题,那么就会将整个Job给标记为失败。 现阶段(包括在刚发布的2.0),这个数值是固定的,并不能够设置。
@markhamstra 给出的质疑是,如果发生节点失败导致Stage 重新被Resubmit ,Resubmit后理论上不会再尝试原来失败的节点,如果连续四次都无法找到正常的阶段运行这些任务,那么应该是有Bug,简单增加重试次数虽然也有意义,但是治标不治本。
我个人认为在集群规模较大,任务较重的过程中,出现一个或者一批Node 挂掉啥的是很正常的,如果仅仅是因为某个Shuffle 导致整个Job失败,对于那种大而耗时的任务显然是不能接受的。个人认为应该讲这个决定权交给用户,也就是允许用户配置尝试次数。
Unresponsive driver SPARK-13279
这个Bug已经在1.6.1, 2.0.0 中修复。 这个场景比较特殊,因为Facebook产生了高达200k的task数,原来给pendingTasksForExecutor:HashMap[String, ArrayBuffer[Int]] 添加新的task 的时候,都会根据Executor名获取到已经存在的列表,然后判断该列表是否已经包含了新Task,这个操作的时间复杂度是O(N^2)。在Task数比较小的情况下没啥问题,但是一旦task数达到了200k,基本就要五分钟,给人的感觉就是Driver没啥反应了。
而且在实际运行任务的过程中,会通过一个特殊的dequeueTaskFromList结构来排除掉已经运行的任务,所以我们其实在addPendingTask 过程中不需要做这个检测。
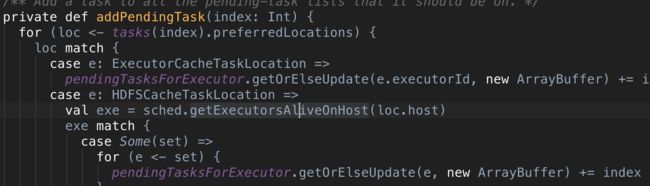
因为证明了没有副作用,所以现在是没啥问题了。但是我个人认为其实还有一种办法是,取一个阈值,如果小于某个阈值则做double duplicate check,否则就直接加进去就好了。Spark 在很多地方也是这么做的。
这里对于那些Task数特别大的朋友有福了。
TimSort issue due to integer overflow for large buffer
该Bug在1.6.2, 2.0.0 已经被解决。这个bug引起的问题现象初看起来会比较让人费解,大体如下:
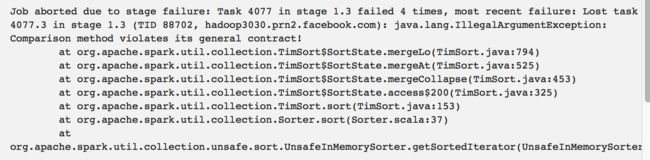
如图所示似乎违反了签名。其实问题本身确实比较复杂,通过提交了两个patch 才解决了该问题。
一开始Facebook的哥们觉得应该是排序过程中内存的数据(比如ShuffleExternalSorter等Sorter) 超过8G 引起的,所以限制了数量,大于一定数量之后就进行spill操作。 后面一个新的PR应该是发现了问题的根源,在UnsafeSortDataFormat.copyRange() 和ShuffleSortDataFormat copyRange() 里,里面数组的偏移量是Integer类型,虽然数据集的大小不至于超过Int的最大值,但是在特定数据分布下且数据集>268.43 million 并则会触发这个Bug。我看了下,原先 Platform.copyMemory 签名本身也是Long的,但是实现copyRange的时候,默认传进去的是Int,所以产生了这个问题。大家瞅一眼代码就知道了。
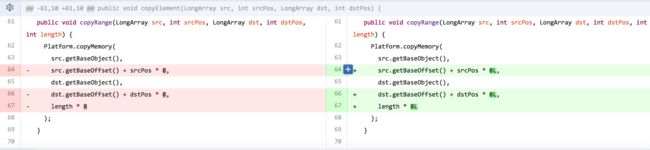
Fix Spark executor OOM
该Bug 也是在1.6.2, 2.0.0 被修正。
这个问题是这样的,Spark MemoryManager 可能认为还有10M内存,但是此时实际JVM可以提供给MemroyManager的内存只有5M了。所以分配内存的时候,就抛OOM了。这个时候应该捕获该OOM,并且保留已经申请到内存不归还,让MemoryManger 以为内存不够了,然后进行splill操作,从而凑足需要的内存。我们看TaskMemoryManager.allocatePage 方法。
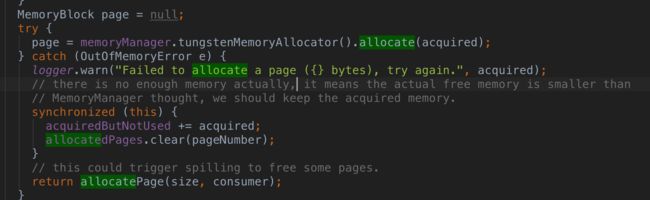
如果发生OOM了,则会捕获一次,,并且通过acquiredButNotUsed记住已经申请的量,最后再次调用allocatePage。这个时候allocatePage里的acquireExecutionMemory 方法可能发现自己内存不足了,就会发生spill了,从而释放出内存。
其实这之前的代码也考虑过,但是没有在allocatePage的层次上做。这个Bug估计在单个Executor 并行运行Task数比较多的时候比较严重和容易发生的。
Fix memory leak in the sorter SPARK-14363
这个Bug 也是在1.6.2, 2.0.0被修正。
在Spark排序中,指针和数据时分开存储的,进行spill操作其实是把数据替换到磁盘上。但是指针数组是必须在内存里。当数据被spill后,相应的,指向这些记录的指针其实也是要被释放的。数据量很大的时候,指针数组的大小也很可观。而且有一点值得指出的是,比如某个Executor 有五个Task并行运行,如果其中有三个完成了,那么可用内存增大,缓存到内存的数据就会变多,这个时候剩下的两个Task的指针数组也会增大,从而占用更多内存,接着新运行的三个Task可用内存变小了,从而失去了公平性。
这些各个Sorter里都需要修正。
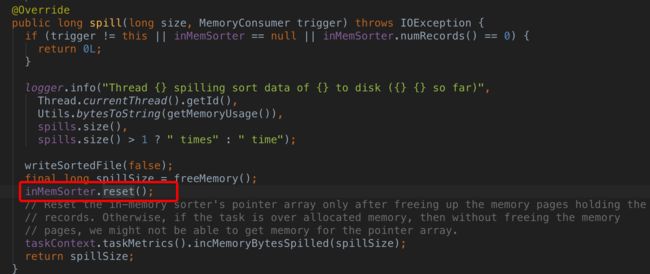
红框部分便是释放指针数组的地方。里面会重新按初始initialSize值申请一块指针数组的内存。