本文是我学习kafka的一个思路和总结,希望对刚接触kafka的你有所帮助。在学习kafka之前,最好能对kafka有一个简单的了解,可以提出一些问题,带着问题去学习,就会容易一些。
0 什么是kakfa1 kafka的版本2 kakfa中的术语3 Kafka消息模型4 kafka的结构5 使用kafka创建demo6 kakfa客户端请求是如何被处理的7 kafka中的组件coordinatorcontroller8 位移提交与分区管理9 重平衡10 kakfa的参数(整理项,选读)brokertopicproducerconsumer端
0 什么是kakfa
kakfa是一个开源的消息引擎系统,提供了一组规范,企业可以利用这组规范在不同的系统中,传递语义准确的消息。(通俗的来讲,就是系统A发消息给消息引擎,系统B从消息引擎中读取系统A发送的消息)。
1 kafka的版本
我们学习开源框架,一定要有版本意识。至少要了解每个版本有哪些大的改动,如果没有版本意识,就很容易出现学习后,由于使用的版本不同,导致各种错误,甚至是调用的api不能通过编译。
接下来我就对kafka版本的改动点做一个总结:
0.7: 只提供了最基础的消息队列的功能
0.8: 引入了副本的机制,保证了系统的可靠性,此时kafka使用的还是老版本的客户端api,需要指定zookeeper地址,0.8.2引入了新版本的producer,但是bug较多。
0.9: 引入了kakfa connect组件,使用了java语言重写了新版 consumer api,从这个版本开始,新版producer api相对稳定。
0.10: 引入了kafka stream 使得kafka正式升级成为了分布式流处理平台,这个版本的consumer api开始相对稳定,0.10.22修复了可能会降低producer性能的bug,如果你使用的是这个版本的kafka,建议升级为0.10.22
0.11: 引入了幂等性Producer 以及事务性,这个版本的kafka消息进行了重构,由v1升级成了v2,提高了压缩的程度和效率。
1.0/2.0:主要是对kafka Stream进行改进和优化
2 kakfa中的术语
消息(record)、主题(topic)、分区(Partition)、位移(offset)、副本(replica)、生产者(producer)、消费者(consumer)、消费者组(consumer group)、重平衡(rebalance)
3 Kafka消息模型
点对点模型:也叫做消息队列模型,即系统A发送的消息只能系统B去接收,类似于打电话。
发布/订阅模型:这里有一个主题的概念,可以理解成消息的逻辑容器。消息的发布者向主题发布消息,订阅者从它订阅的主题中获取消息。在这个过程中发布者和订阅者都可能是多个,主题也可以是多个,类似于订报纸。
4 kafka的结构
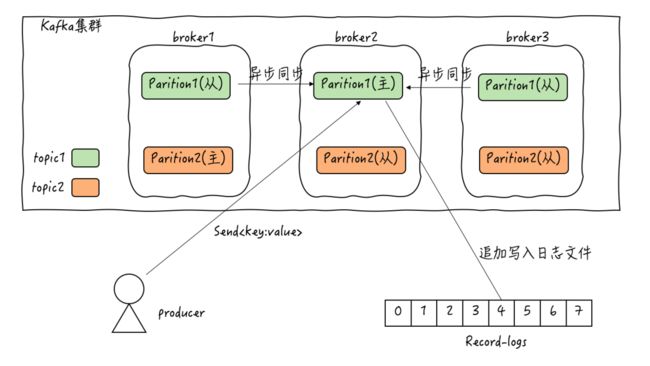
注:topic只是一个逻辑容器,常用来区分不同的业务数据。
5 使用kafka创建demo
kafka集群的创建过程以及使用java调用kafka客户端api的demo,请参考本博客前2篇文章,有非常详细的教程。
6 kakfa客户端请求是如何被处理的
kafka broker采用的React模型处理请求,React模式是事件驱动架构的一种实现方式,特被适用于处理多个客户端并发向服务器端发送请求的场景。我们通过一幅图来对React模式有一个初步的了解。
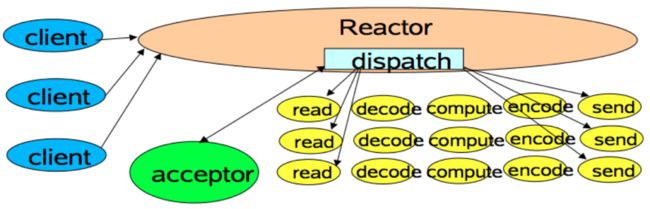
客户端的请求发送到Reactor,Reactor中有一个dispatch线程,负责分发请求,它将请求分发到工作线程中,由工作线程进行处理。映射到kafka中, SocketServer就上述中的Reactor, acceptor线程就是上述中的dispatch线程,kafka工作线程也有一个专属的名字,叫 网络线程池。但是kafka在此基础上,进行了进一步的细化,接收用户请求的线程(网络线程池中的线程)不对用户请求进行处理,而是将请求放到一个 共享请求队列中,由 IO线程池中的线程进行处理。

上图中的purgatory组件用于缓存延时请求,比如我们配置了acks = all,当ISR中的其他副本还没有写入结果的时候,这个响应就会缓存在purgatory中,直到条件满足,IO线程才会将结果返回到网络响应队列中。
我们通过上图可以知道,如果想提高kafka处理消息的能力,可以提高网络线程数和io线程数,这两个线程数分别对应着 num.network.threads、 num.io.threads两个参数。
7 kafka中的组件
coordinator
管理消费者组,与位移提交有关。
coordinator是每个broker都有的组件,那么如何确定coordinator呢?
确定位移主题是由哪个分区保存的:Math.abs(group.id % offsetTopicParitionCount);
找出该分区leader对应的broker。
controller
主题、分区管理、集群管理、数据缓存
8 位移提交与分区管理
consumer会定期向kakfa提交自己的消费位移(offset),kafkaConsumer api提供了多种提交位移的方式,就用户而言,位移提交分为手动提交和自动提交(auto.commit.offset.enable),就Consumer而言,提交位移分为同步提交(commitSync)和异步提交(CommitAsync),consumer会将位移信息提交到__consumer_offset这个主题中。
kafka中的副本(replica),是在分区(Partition)层面上进行的,可以实现数据的冗余(replica.factor)。在同一个分区中,数据是有序的,kafka支持对消息设置键,同一个键的消息会被发送到一个分区中,一个分区只能由一个Consumer进行消费。
在kafka中只有leader 副本对客户端提供服务,follower副本只是异步同步数据。不提供服务。
9 重平衡
重平衡可以说是kafka中最重要的概念了,重平衡的本质是一种协议,它规定了一个consumer group下的所有consumer如何达成一致,对订阅topic的partition进行分配。
那么为什我们要避免重平衡呢?重平衡的效率不高,在重平衡的过程中,当前consumer group的所有consumer会停止消费(可以类比java中的full gc),重平衡的影响范围较广,consumer group下的所有comsumer都会受到影响。
重平衡的实现,需要借助Coordinator组件,消费者端的重平衡可以分为两步:
1.Consumer入组
2.等待Leader consumer分配方案,分别对应着joinGroup和syncGroup两类请求。
首先当consumer加入consumer group的时候,会向coordinator发送join Group请求,这样coordinator就知道了所有订阅主题的消费者信息。一旦收集了所有consumer的信息,协调者就会选出一个comsumer leader。
领导者消费者的任务就是收集所有成员的订阅信息,然后根据信息,制定分区方案。
最后领导者消费者会将分配方案发送给协调者,其他消费者也会发送请求给协调者,不过请求中没有实际的内容。协调者会以响应的方式将方案返回给所有消费者,这样消费者组内的成员就可以知道自己消费的分区了。
10 kakfa的参数(整理项,选读)
总结的都是个人认为比较重要的参数,但是篇幅有限,很难展开说明,其目的就是让你有一个印象,下次见到这些参数的时候,要重点记忆
broker
log.dirs:指定了broker使用的若干文件路径。
listeners:监听器,告诉外部连接者通过什么协议访问指定名称和端口的kafka服务
advertised.listeners:和listeners功能一致,不同的是它是对外部发布的
auto.create.topics.enable:是否允许自动创建topic
unclean.leader.election.enable:是否允许unclean的leader进行选举
auto.leader.rebalance.enabl:是否允许定期举行leader选举
log.retention.{hours|minutes|ms}:消息被保存的时间
message.max.bytes:broker最大能接收消息的大小
replica.lag.time.max.ms:follower副本可以落后leader副本的最长时间间隔。
topic
retention.ms:该topic中消息被保存的时间
max.message.bytes:该topic最大能接收的消息大小
replication.factor:消息冗余份数
producer
bootstrap.server:用于与kafka集群中的broker创建连接,只需要配置部分broker即可
key.serializer/value.serializer:键/值的序列化方式,必填
acks:非常重要,用于控制producer产生消息的持久性,kafka只对“已提交”的消息做有有限度的持久化保证。而这个参数,就是定义“已提交”。
acks = 0:producer不用理睬broker端的处理结果,只要消息发送后,就认为是“已提交”
acks = all或-1,不仅leader broker要将消息写入本地日志,还要ISR集合中的所有副本都成功写入各自的本地日志后,才发送响应消息给producer,认为消息“已提交”
acks = 1折中方案,当leader broker将消息写入本地日志,就返回响应给producer,认为消息“已提交”
min.insync.replica:消息至少要被写入多少个副本,才算写入成功,这个参数和acks功能类似,不过它强调的是个,acks = all时,强调的是所有副本。(比如ISR中只有一个replica,那么配置acks = 1即写入一个broker即可,min.sync.replica = 2,即需要写入2个broker,这条消息会写入失败)
buffer.memory:指定了producer端用于缓存消息的缓冲区大小。kafka发送消息采用的是异步架构的方式,消息写入缓冲区,由一个专属线程从缓冲区中获取消息,执行真正的发送
compression.type:producer端压缩方式,压缩可以节省网络传输中的带宽,牺牲CPU使用率
retries:失败后的重试次数,非常重要的参数,用于实现kafka的处理语义
retries = 0,即失败后不会进行重试,实现至多一次的处理语义
retries = n,即失败后会重试n次,实现至少一次的处理语义
(kafka 0.11后推出了精确一次的处理语义,即幂等性producer以及事务,相关参数:enable.idempotence = true)
bacth.size:producer会将发往同一分区的消息,打成一个batch,当batch满了后,producer会一次发送batch中的所有消息,这个参数控制者batch的大小。
linger.ms:上面提到的batch,在batch没满的时候,也会进行发送,这其实是一种权衡,权衡的是吞吐量和消息延时,linger.ms控制的就是消息的延时行为,默认值是0,表示消息会被立即发送,不管batch是否装满,我们可以改变这个参数,来修改发送消息的时间,即一条消息是否会被发送,取决于1、batch是否装满;2、有没有达到linger.ms规定的时间。
max.request.size:控制producer端最大可以发送消息的大小。
request.timeout.ms:当producer发送消息给broker后,broker需要在指定时间内返回响应,否则producer就会认为该请求超时,并显示抛出TimeoutException。
consumer端
bootstrap.server:用于与kafka集群中的broker创建连接,只需要配置部分broker即可
key.deserializer/value.deserializer:键/值的反序列化方式,必填
group.id:consumer group的名字,必填
session.time.out:coordinator检测到consumer失活的时间,这个值设置的较小有利于coordinator更快的检测consumer失活。
max.poll.interval.ms:consumer处理逻辑的最大时间,如果一次poll()超过了这个时间,则coordinator会认为该consumer已经不可用,会将其踢出消费者组并进行重平衡。
auto.offset.reset:制定了无位移或位移越界时,kafka的对应策略。取值:earliest:从最早位移进行消费、laster:从最新位移开始消费、none:抛出异常。
auto.commit.enable:指定consumer是否自定义提交位移
fetch.max.bytes:consumer端单次获取数据的最大字节数
max.poll.records:单次poll()返回的最大消息数
heartbeat.interval.ms:心跳请求频率
connections.max.idle.ms:定期关闭空闲的tcp连接。
最后,期待您的订阅和点赞,专栏每周都会更新,希望可以和您一起进步,同时也期待您的批评与指正!
 image
image