什么是Merkle Tree
Merkle Tree是一种基于哈希的数据结构。Merkle Tree是一种树状数据结构,该树中的每一个叶子结点都是一个数据块,而每一个非叶子结点都是其子结点组合的哈希。普遍性况下Merkle Tree是二叉树,也就是说Merkle Tree中的每一个结点有两个子结点。当然,Merkle Tree可以是多叉树,例如Ethereum平台所采用的。简单起见,本文我们仅讨论二叉Merkle Tree。
Merkle Tree在分布式系统中被广泛使用于进行数据校验。一般来说,在分布式系统中,由于我们将数据存储于许多不同的机器上,那么为了保证数据可靠性及一致性,数据的校验就显得尤为重要。例如我们如果更新了一台机器上的某一块数据,这一更新必须被传递到分布式系统中的所有机器上以保证数据的最终一致性,这样一来对比不同机器上的数据就是问题所在。
直接比较所有文件显然是一种既耗时又低效的方法。而且这样做会由于机器之间相互发送文件而产生大量的网络通信。考虑到我们往往想要尽量减少通过网络发送的数据量,发送文件的哈希就成了自然而然的选择。
Merkle Tree之所以能够高效进行数据校验,是因为其采用验证哈希值的形式进行校验。相比于直接比较整个文件,比较文件哈希值显然高效的多。而且验证哈希值能够大大减少分布式系统,或者peer-to-peer(p2p)系统中处于校验需求所需要互相发送的信息量。
当前,Merkle Tree主要被用于Tor,Bitcoin,Git这一类的分布式p2p系统中,或用于Apache Cassandra或HBase这样的分布式数据库中。
Merkle Tree的结构综述
如下图所示是一个二叉Merkle Tree。此处我们假设图中所使用的哈希方法Hash()不会产生哈希值碰撞的情况。也就是说,对于不同的输入数据块,Hash()一定会返回一个独特的不会与其他数据块对应哈希值重叠的哈希值,或说找到两个具有相同哈希值的不同区块在现有计算机运算能力下不可实现。
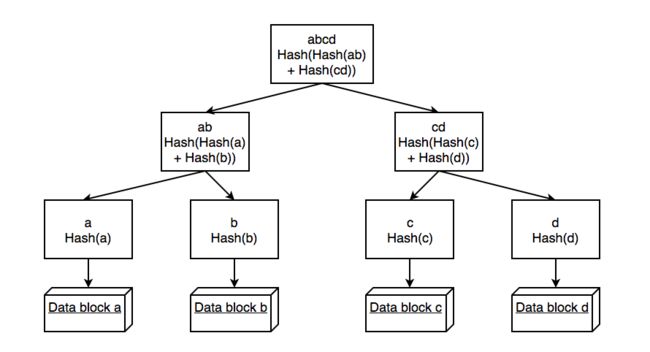
图中最下层的四个叶节点表示四个数据块。他们上层的a,b,c,d四个结点分别包含四个数据块的哈希。除去这两层之外,Merkle Tree中其他结点的哈希值均由其左右两个子结点哈希值组合计算得出。例如图中ab结点的哈希值由其两个子结点——a,b的哈希值合并计算得出。以此类推,Merkle Tree中的每一个结点的哈希值事实上反映了以该节点为根的子树中所包含的所有数据块的内容。
而通过以上分析,我们容易得知,构建Merkle Tree的过程其实就是从最底层的数据块开始,合并左右两个子结点的哈希值并计算出他们的母结点的哈希值,循环往复直至我们抵达该Merkle Tree的根结点,也就是当前层只剩下一个结点。
数据校验的流程
当分布式系统中的电脑对应于一系列数据区块构建出其Merkle Tree之后,我们可以通过如下算法进行自上而下的数据校验:
- A服务器向B服务器发送需要对应Merkle Tree的根结点的哈希值。
- B服务器收到该值,并同自己所构建的Merkle Tree的根结点哈希值对比。
- 如果两个值相同,则代表着二者所存储的文件完全相同。
- 否则的话,B服务器需要像A服务器索要根结点对应的两个子结点的哈希值。
- A服务器将对应的值发给B服务器。
- B服务器对比起相应的结点中的哈希值并重复步骤4和步骤5直到B服务器找到导致哈希值不同的一个或几个数据块。
显而易见,在以上算法中我们仅仅需要发送哈希值就可以进行不同服务器上的数据对比,这一过程是很高效的。并且在对比结束过后我们可以轻易得知哪些数据区块不同并做相应更新,而非更改整个文件。
对于p2p系统而言,Merkle Tree主要被用来在peer不一定可信的情况下检验从不同的peer所得到的数据区块是否可信。同上述算法相反,检验数据块是否可信的算法是自下而上的。以上面图中的Merkle Tree为例,如果我们想确保所得到的区块a是可信的,我们需要利用已有的Hash(b),Hash(c),Hash(d)重新构建整个Merkle Tree直至到达根结点。接着我们可以对比该根哈希值是否与从一个可靠peer处得到的根哈希值是否相同来确定所得到区块a是否可信。或者我们也可以采取像Bitcoin系统一样假设多数peer可信的原则进行校验。
复杂度分析
设我们总计有n个数据区块。
从上面的算法可以得知,如果要在分布式系统中找到不统一的文件,我们需要O(logn)时间,因为我们只需沿树中的某一条路径一路向下验证到叶节点即可。而如果要确定p2p系统中我们所得到的数据区块是否可信,则需要最坏情况下O(n)的时间,因为我们可能需要重构整个Merkle Tree。
Merkle Tree的使用
上面我们已经提到Merkle Tree被广泛用于分布式系统,p2p系统中。在这些系统中,同一份数据块往往被存储于许多不同的地方。因此这样的系统需要使用Merkle进行高效的数据校验。
例如Git,其作为一个非常流行的分布式代码版本控制系统,就使用Merkle Tree来比较不同机器上分别存储的代码版本是否统一。
Bitcoin,作为当前最流行的匿名分布式加密数字货币之一,也采用Merkle Tree来对代表交易的区块所构成的区块链进行校验。这些代表交易的区块链分别存在于每一个使用比特币的用户的电脑上。每次当由用户试图添加一个新的区块(代表一比新的交易)时,这一改变就将被其他用户采用基于Merkle Tree的方法来验证。
Apache Cassandra,最常用的分布式NoSQL数据库之一,也采用基于Merkle Tree的算法来确保不同服务器上的数据备份的一致性。在其所谓Compaction的过程中,Cassandra采用对比Merkle Tree的方式来进行数据一致性的对比,并进行不一致数据块的更新或修复。