CheeseZH: Stanford University: Machine Learning Ex4:Training Neural Network(Backpropagation Algorithm)
1. Feedforward and cost function;
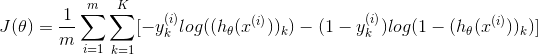
2.Regularized cost function:
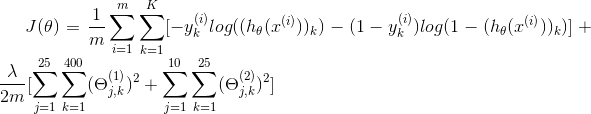
3.Sigmoid gradient
The gradient for the sigmoid function can be computed as:
![]()
where:
![]()
4.Random initialization
randInitializeWeights.m


1 function W = randInitializeWeights(L_in, L_out) 2 %RANDINITIALIZEWEIGHTS Randomly initialize the weights of a layer with L_in 3 %incoming connections and L_out outgoing connections 4 % W = RANDINITIALIZEWEIGHTS(L_in, L_out) randomly initializes the weights 5 % of a layer with L_in incoming connections and L_out outgoing 6 % connections. 7 % 8 % Note that W should be set to a matrix of size(L_out, 1 + L_in) as 9 % the column row of W handles the "bias" terms 10 % 11 12 % You need to return the following variables correctly 13 W = zeros(L_out, 1 + L_in); 14 15 % ====================== YOUR CODE HERE ====================== 16 % Instructions: Initialize W randomly so that we break the symmetry while 17 % training the neural network. 18 % 19 % Note: The first row of W corresponds to the parameters for the bias units 20 % 21 epsilon_init = 0.12; 22 W = rand(L_out, 1 + L_in) * 2 * epsilon_init - epsilon_init; 23 24 % ========================================================================= 25 26 end
5.Backpropagation(using a for-loop for t=1:m and place steps 1-4 below inside the for-loop), with the tth iteration perfoming the calculation on the tth training example(x(t),y(t)).Step 5 will divide the accumulated gradients by m to obtain the gradients for the neural network cost function.
(1) Set the input layer's values(a(1)) to the t-th training example x(t). Perform a feedforward pass, computing the activations(z(2),a(2),z(3),a(3)) for layers 2 and 3.
(2) For each output unit k in layer 3(the output layer), set :
![]()
where yk = 1 or 0.
(3)For the hidden layer l=2, set:
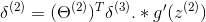
(4) Accumulate the gradient from this example using the following formula. Note that you should skip or remove δ0(2).
![]()
(5) Obtain the(unregularized) gradient for the neural network cost function by dividing the accumulated gradients by 1/m:
![]()
nnCostFunction.m
1 function [J grad] = nnCostFunction(nn_params, ... 2 input_layer_size, ... 3 hidden_layer_size, ... 4 num_labels, ... 5 X, y, lambda) 6 %NNCOSTFUNCTION Implements the neural network cost function for a two layer 7 %neural network which performs classification 8 % [J grad] = NNCOSTFUNCTON(nn_params, hidden_layer_size, num_labels, ... 9 % X, y, lambda) computes the cost and gradient of the neural network. The 10 % parameters for the neural network are "unrolled" into the vector 11 % nn_params and need to be converted back into the weight matrices. 12 % 13 % The returned parameter grad should be a "unrolled" vector of the 14 % partial derivatives of the neural network. 15 % 16 17 % Reshape nn_params back into the parameters Theta1 and Theta2, the weight matrices 18 % for our 2 layer neural network 19 Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), ... 20 hidden_layer_size, (input_layer_size + 1)); 21 22 Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), ... 23 num_labels, (hidden_layer_size + 1)); 24 25 % Setup some useful variables 26 m = size(X, 1); 27 28 % You need to return the following variables correctly 29 J = 0; 30 Theta1_grad = zeros(size(Theta1)); 31 Theta2_grad = zeros(size(Theta2)); 32 33 % ====================== YOUR CODE HERE ====================== 34 % Instructions: You should complete the code by working through the 35 % following parts. 36 % 37 % Part 1: Feedforward the neural network and return the cost in the 38 % variable J. After implementing Part 1, you can verify that your 39 % cost function computation is correct by verifying the cost 40 % computed in ex4.m 41 % 42 % Part 2: Implement the backpropagation algorithm to compute the gradients 43 % Theta1_grad and Theta2_grad. You should return the partial derivatives of 44 % the cost function with respect to Theta1 and Theta2 in Theta1_grad and 45 % Theta2_grad, respectively. After implementing Part 2, you can check 46 % that your implementation is correct by running checkNNGradients 47 % 48 % Note: The vector y passed into the function is a vector of labels 49 % containing values from 1..K. You need to map this vector into a 50 % binary vector of 1's and 0's to be used with the neural network 51 % cost function. 52 % 53 % Hint: We recommend implementing backpropagation using a for-loop 54 % over the training examples if you are implementing it for the 55 % first time. 56 % 57 % Part 3: Implement regularization with the cost function and gradients. 58 % 59 % Hint: You can implement this around the code for 60 % backpropagation. That is, you can compute the gradients for 61 % the regularization separately and then add them to Theta1_grad 62 % and Theta2_grad from Part 2. 63 % 64 65 %Part 1 66 %Theta1 has size 25*401 67 %Theta2 has size 10*26 68 %y hase size 5000*1 69 K = num_labels; 70 Y = eye(K)(y,:); %[5000 10] 71 a1 = [ones(m,1),X];%[5000 401] 72 a2 = sigmoid(a1*Theta1'); %[5000 25] 73 a2 = [ones(m,1),a2];%[5000 26] 74 h = sigmoid(a2*Theta2');%[5000 10] 75 76 costPositive = -Y.*log(h); 77 costNegtive = (1-Y).*log(1-h); 78 cost = costPositive - costNegtive; 79 J = (1/m)*sum(cost(:)); 80 %Regularized 81 Theta1Filtered = Theta1(:,2:end); %[25 400] 82 Theta2Filtered = Theta2(:,2:end); %[10 25] 83 reg = (lambda/(2*m))*(sumsq(Theta1Filtered(:))+sumsq(Theta2Filtered(:))); 84 J = J + reg; 85 86 87 %Part 2 88 Delta1 = 0; 89 Delta2 = 0; 90 for t=1:m, 91 %step 1 92 a1 = [1 X(t,:)]; %[1 401] 93 z2 = a1*Theta1'; %[1 25] 94 a2 = [1 sigmoid(z2)];%[1 26] 95 z3 = a2*Theta2'; %[1 10] 96 a3 = sigmoid(z3); %[1 10] 97 %step 2 98 yt = Y(t,:);%[1 10] 99 d3 = a3-yt; %[1 10] 100 %step 3 101 % [1 10] [10 25] [1 25] 102 d2 = (d3*Theta2Filtered).*sigmoidGradient(z2); %[1 25] 103 %step 4 104 Delta1 = Delta1 + (d2'*a1);%[25 401] 105 Delta2 = Delta2 + (d3'*a2);%[10 26] 106 end; 107 108 %step 5 109 Theta1_grad = (1/m)*Delta1; 110 Theta2_grad = (1/m)*Delta2; 111 112 %Part 3 113 Theta1_grad(:,2:end) = Theta1_grad(:,2:end) + ((lambda/m)*Theta1Filtered); 114 Theta2_grad(:,2:end) = Theta2_grad(:,2:end) + ((lambda/m)*Theta2Filtered); 115 116 % ------------------------------------------------------------- 117 118 % ========================================================================= 119 120 % Unroll gradients 121 grad = [Theta1_grad(:) ; Theta2_grad(:)]; 122 123 124 end
6.Gradient checking
Let
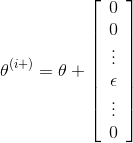
and
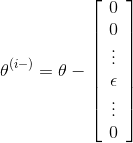
for each i, that:
![]()
computeNumericalGradient.m
1 function numgrad = computeNumericalGradient(J, theta) 2 %COMPUTENUMERICALGRADIENT Computes the gradient using "finite differences" 3 %and gives us a numerical estimate of the gradient. 4 % numgrad = COMPUTENUMERICALGRADIENT(J, theta) computes the numerical 5 % gradient of the function J around theta. Calling y = J(theta) should 6 % return the function value at theta. 7 8 % Notes: The following code implements numerical gradient checking, and 9 % returns the numerical gradient.It sets numgrad(i) to (a numerical 10 % approximation of) the partial derivative of J with respect to the 11 % i-th input argument, evaluated at theta. (i.e., numgrad(i) should 12 % be the (approximately) the partial derivative of J with respect 13 % to theta(i).) 14 % 15 16 numgrad = zeros(size(theta)); 17 perturb = zeros(size(theta)); 18 e = 1e-4; 19 for p = 1:numel(theta) 20 % Set perturbation vector 21 perturb(p) = e; 22 loss1 = J(theta - perturb); 23 loss2 = J(theta + perturb); 24 % Compute Numerical Gradient 25 numgrad(p) = (loss2 - loss1) / (2*e); 26 perturb(p) = 0; 27 end 28 29 end
7.Regularized Neural Networks
for j=0:
![]()
for j>=1:
![]()
别人的代码:
https://github.com/jcgillespie/Coursera-Machine-Learning/tree/master/ex4