Netty源码分析——flush流程
前言
承接上篇写流程,这篇看下flush流程。之前文章中我们已经提到过,writeAndFlush操作实际上是通过pipeline分别进行了write和flush操作。具体我们就不看了,我们直接看下flush。
flush
flush操作同样是通过pipeline最终传递给HeadContext:unsafe.flush();:
123456789101112public final void flush() { //确保不是外部调用 assertEventLoop(); ChannelOutboundBuffer outboundBuffer = this.outboundBuffer; if (outboundBuffer == null) { return; } //添加flush节点 outboundBuffer.addFlush(); //把节点里的数据写到socket里 flush0();}
最主要的其实是两个步骤,上文已经标注了,一个就是添加flush节点,一个就是真正的写操作。
添加flush节点
追进去看下:
1234567891011121314151617public void addFlush() { Entry entry = unflushedEntry; if (entry != null) { if (flushedEntry == null) { flushedEntry = entry; } do { flushed ++; if (!entry.promise.setUncancellable()) { int pending = entry.cancel(); decrementPendingOutboundBytes(pending, false, true); } entry = entry.next; } while (entry != null); unflushedEntry = null; }}
我们按照上篇文章的状态来说,当前调用了两次write的状态是这样的:
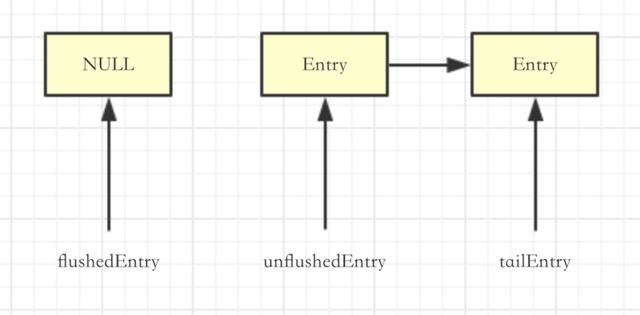
调用完addFlush之后是这样的:
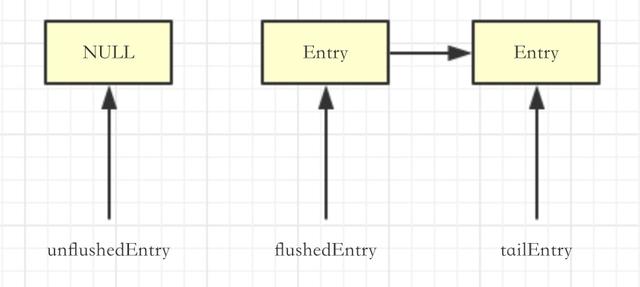
看到了吗,实际上是把flushedEntry和unFlushedEntry交换了一下。
再假设一下,如果我们在调用flush之前调用了三次write,再调用flush,链表是这样的:
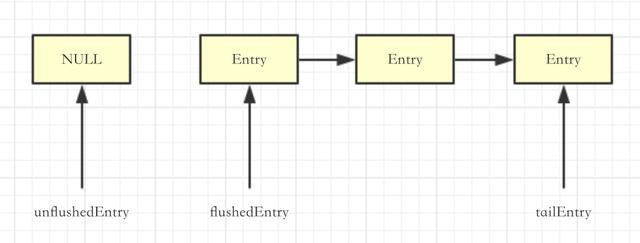
添加节点之后会继续执行flush0:
123if (!isFlushPending()) { super.flush0();}
看下这个isFlushPending:
12SelectionKey selectionKey = selectionKey();return selectionKey.isValid() && (selectionKey.interestOps() & SelectionKey.OP_WRITE) != 0;
这里其实是在校验,当前这个Channel是否有OP_WRITE,如果当前selectionKey是写事件,说明有线程执行flush过程,结合上面的一句:!isFlushPending(),说明如果有线程在进行flush过程,就直接返回。
这里其实我还没吃透,我的疑问是这里是否有必要进行!isFlushPending()判断。因为我们之前已经说过了,任何flush操作开头都进行了一个校验:assertEventLoop(),说白了,只有Reactor线程可以调用flush,那么当前线程在执行的时候,怎么可能有别的线程进行了flush操作呢?
这个问题我会去debug一下,然后求证一下作者,有结果了会在文章后面加上。
继续看,如果当前channel没有被其他线程操作,这里会调用super.flush0,回到io.netty.channel.AbstractChannel.AbstractUnsafe#flush0里:
12345678910111213141516171819202122232425262728293031323334353637383940if (inFlush0) { // 防止重复调用 return;}// 如果没有数据要flush就返回final ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;if (outboundBuffer == null || outboundBuffer.isEmpty()) { return;}inFlush0 = true;// 如果channel失效,把所有待刷的数据设置为失败if (!isActive()) { try { if (isOpen()) { outboundBuffer.failFlushed(FLUSH0_NOT_YET_CONNECTED_EXCEPTION, true); } else { outboundBuffer.failFlushed(FLUSH0_CLOSED_CHANNEL_EXCEPTION, false); } } finally { inFlush0 = false; } return;}try { // 真正的写操作 doWrite(outboundBuffer);} catch (Throwable t) { if (t instanceof IOException && config().isAutoClose()) { close(voidPromise(), t, FLUSH0_CLOSED_CHANNEL_EXCEPTION, false); } else { try { shutdownOutput(voidPromise(), t); } catch (Throwable t2) { close(voidPromise(), t2, FLUSH0_CLOSED_CHANNEL_EXCEPTION, false); } }} finally { inFlush0 = false;}
继续看doWrite操作,这里会直接走到io.netty.channel.socket.nio.NioSocketChannel#doWrite里:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849SocketChannel ch = javaChannel();// 获取循环次数,相当于一个自旋,保证写成功int writeSpinCount = config().getWriteSpinCount();do { // 如果buffer里空的,则清理OP_WRITE,防止Reacotr线程再次处理这个Channel if (in.isEmpty()) { clearOpWrite(); return; } // 聚合 int maxBytesPerGatheringWrite = ((NioSocketChannelConfig) config).getMaxBytesPerGatheringWrite(); ByteBuffer[] nioBuffers = in.nioBuffers(1024, maxBytesPerGatheringWrite); int nioBufferCnt = in.nioBufferCount(); switch (nioBufferCnt) { case 0: writeSpinCount -= doWrite0(in); break; case 1: { // 如果只有一个buffer的情况下,直接把这个buffer写进去 ByteBuffer buffer = nioBuffers[0]; int attemptedBytes = buffer.remaining(); final int localWrittenBytes = ch.write(buffer); if (localWrittenBytes <= 0) { incompleteWrite(true); return; } adjustMaxBytesPerGatheringWrite(attemptedBytes, localWrittenBytes, maxBytesPerGatheringWrite); in.removeBytes(localWrittenBytes); --writeSpinCount; break; } default: { // 多个buffer的情况下,写nioBufferCnt个buffer进去 long attemptedBytes = in.nioBufferSize(); final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt); if (localWrittenBytes <= 0) { incompleteWrite(true); return; } adjustMaxBytesPerGatheringWrite((int) attemptedBytes, (int) localWrittenBytes, maxBytesPerGatheringWrite); in.removeBytes(localWrittenBytes); --writeSpinCount; break; } }} while (writeSpinCount > 0);// 是否写完成incompleteWrite(writeSpinCount < 0);
上面的过程中,我只是粗略的写了一下过程,其实里面的细节非常多,我们一点一点来看。
先看着几句:
123int maxBytesPerGatheringWrite = ((NioSocketChannelConfig) config).getMaxBytesPerGatheringWrite();ByteBuffer[] nioBuffers = in.nioBuffers(1024, maxBytesPerGatheringWrite);int nioBufferCnt = in.nioBufferCount();
首先获取聚合写的最大字节数,聚合写,在原生NIO的概念中,是把几个Buffer的数据写到一个Channel里,就是说一次最多写多少字节数据。然后进入到nioBuffers方法,这个方法做什么注释上有说:如果缓冲区里全都是ByteBuf,则返回直接NIO缓冲区的Buffer数组(其实就是把ByteBuf里的数据写到原生Buffer里),nioBufferCount和nioBufferSize分别代表返回数组中原生NIO Buffer的数量和NIO缓冲区的可读字节总数。看代码,有点长拆开看:
123456789long nioBufferSize = 0;int nioBufferCount = 0;final InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.get();ByteBuffer[] nioBuffers = NIO_BUFFERS.get(threadLocalMap);Entry entry = flushedEntry;while (isFlushedEntry(entry) && entry.msg instanceof ByteBuf) { //...}return nioBuffers;
先是从当前线程里获取ByteBuffer,这里可以看出,其实ByteBuffer是被缓存了的(如果没有创建一个长度为1024的ByteBuffer数组),不需要每次创建。
然后是循环所有的flushedEntry,这里,我们回顾一下上面addFlush之后的图,其实循环中会不停地把flushedEntry前移,直到flushedEntry和tailEntry中的节点全部都被处理。isFlushEntry的代码:e != null && e != unflushedEntry;,其实就是,不是unflushedEntry的都是flushedEntry。
这里我们可以看到,另外一个循环的条件就是entry.msg instanceof ByteBuf,说明这个方法只处理ByteBuf。
继续看循环里:
1234567891011121314151617181920212223ByteBuf buf = (ByteBuf) entry.msg;final int readerIndex = buf.readerIndex();final int readableBytes = buf.writerIndex() - readerIndex;// 如果有数据if (readableBytes > 0) { if (maxBytes - readableBytes < nioBufferSize && nioBufferCount != 0) { break; } // NIO Buffer可读字节数+ByteBuf的可读字节数 nioBufferSize += readableBytes; int count = entry.count; if (count == -1) { // 初始化entry的count entry.count = count = buf.nioBufferCount(); } int neededSpace = min(maxCount, nioBufferCount + count); if (neededSpace > nioBuffers.length) { //如果实际需要的空间,比之前得到的ByteBuffer数组数量大,就扩容,然后缓存起来 nioBuffers = expandNioBufferArray(nioBuffers, neededSpace, nioBufferCount); NIO_BUFFERS.set(threadLocalMap, nioBuffers); }}
这里说下这个流程,声明一下,ByteBuffer指的是原生Buffer,ByteBuf是Netty自己封装的Buffer。
先拿出来一个Entry的ByteBuf,看看可读的字节多少。然后初始化entry的count,用的是组成这个ByteBuf的ByteBuffer(原生)的数量(这里这个nioBufferCount大部分情况下返回1,及一个ByteBuf对应一个ByteBuffer)。
然后看看需要的空间是多少,需要的空间默认情况下是1024和已有需要的ByteBuffer数量+count(及ByteBuf.nioBufferCount)二者之间的最小值,及,最多搞1024个ByteBuffer。
然后对比需要空间和提供空间,及对比之前分配的ByteBuffer[]的length和需要的ByteBuffer的数量,如果需要的空间大,就扩容(这里可以类比一下ArrayList的扩容)。也就是,不管怎么样,都会分配足够的ByteBuffer使用。
可能这么看起来有点绕,我举个例子:
假设我们有八个节点,每个节点的ByteBuf在Flush的时候,数据都会写入到1个ByteBuffer里,然后我们开始循环这个八个节点,循环之前我记录一下一共需要多少个ByteBuffer数组(比如叫count,循环前就是0),然后我们有一个分配给我们的ByteBuffer数组(比如叫fenpei)。
代码应该是这样的:
123456789101112// 循环八个节点int count = 0;for (Entry e : entries) { ByteBuf b = e.msg; // 这里大部分ByteBuf会返回1 int c = b.nioBufferCount(); count += c; if (count > fenpei.length) { //扩容 expandNioBufferArray(fenpei) }}
这样就比较直接了,再看不懂的。。。emmm,哈哈哈哈哈~
继续看:
12345678910111213141516171819202122232425if (count == 1) { // 1个ByteBuff对应1个ByteBuffer ByteBuffer nioBuf = entry.buf; if (nioBuf == null) { // 初始化ByteBuffer, entry.buf = nioBuf = buf.internalNioBuffer(readerIndex, readableBytes); } // 放到数组里 nioBuffers[nioBufferCount++] = nioBuf;} else { // 一个ByteBuf对应多个ByteBuffer,初始化多个ByteBuffer,循环放到数组里 ByteBuffer[] nioBufs = entry.bufs; if (nioBufs == null) { entry.bufs = nioBufs = buf.nioBuffers(); } for (int i = 0; i < nioBufs.length && nioBufferCount < maxCount; ++i) { ByteBuffer nioBuf = nioBufs[i]; if (nioBuf == null) { break; } else if (!nioBuf.hasRemaining()) { continue; } nioBuffers[nioBufferCount++] = nioBuf; }}
这个方法我们总结一下,就是分配数组,这个数组一开始会初始化一个长度为1024的ByteBuffer数组,如果不够用就扩容,里面的ByteBuffer能容纳的数据,对应每个节点ByteBuf里有的数据。这个地方其实并没有看到ByteBuf向对应的ByteBuffer里写数据的地方,关于这个问题,大家可以跟一下buf.internalNioBuffer(readerIndex, readableBytes)这里,这里是会把数据搞到ByteBuffer里的。
至此分配就结束了,然后继续往下看doWrite,接下来进入了一个switch,条件就是有多少个原生ByteBuffer要写,我们看看default的情况:
12345678910111213141516// 整个Entry链的可读数据long attemptedBytes = in.nioBufferSize();// 向管道中写数据final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);// 如果写失败了,这个要细说if (localWrittenBytes <= 0) { incompleteWrite(true); return;}// 调整最大聚合写的字节数adjustMaxBytesPerGatheringWrite((int) attemptedBytes, (int) localWrittenBytes, maxBytesPerGatheringWrite);// remove节点 in.removeBytes(localWrittenBytes);// 自旋次数-1--writeSpinCount;
向channel中写入数据,如果localWrittenBytes < 0,这里是说明这个Channel不可用,其实就是写失败了(或者说没有全部写到Channel里?这个地方存疑,我没有验证过)。
这里写失败了怎么办,我们看下incompleteWrite,注意入参是true,下面会说到:
1234567891011121314151617// 这里这个setOpWrite就是入参trueif (setOpWrite) { setOpWrite();} else { clearOpWrite(); eventLoop().execute(flushTask);}setOpWrite方法:final SelectionKey key = selectionKey();if (!key.isValid()) { return;}final int interestOps = key.interestOps();if ((interestOps & SelectionKey.OP_WRITE) == 0) { key.interestOps(interestOps | SelectionKey.OP_WRITE);}
如果失败了,就去setOpWrite,其实就是给Channel注册了一个OP_WRITE,然后就return了。
这里为什么要打上OP_WRITE呢,打上有什么用呢?还记得上文中我提出的问题么,关于为什么flush0之前要进行判断isFlushPending,这里让我细细说来(为什么判断isFlushPending的疑惑已经解开了,这篇文章拖了几天,这几天中来来回回的看源码、请教大神、debug。。终于有所突破)。
先放下isFlushPending,继续说这个OP_WRITE。这里还记得什么时候打上OP_WRITE么,是Channel写失败的时候!我们先不管这个OP_WRITE的具体含义,就认为是一个标记,标记这个管道不可用,这时候,请问:管道不可用的情况下,如果我还想进行Flush操作,即向管道中写数据,这时候能成功么?答案是不行!怎么优化?太简单了,提前返回就可以了,每次Flush的时候先看看管道是否可用!
到这,isFlushPending的作用就体现出来了!OP_WRITE我们就把它当成一个普通的标记,如果Channel上有这个标记,就表示不可写。
那么为什么用OP_WRITE标识不可写呢,命名OP_WRITE的含义就是可写啊!这里就要说回到Reacotr要做的三件事中的处理select到的事件了,看一下processSelectedKey:
1234if ((readyOps & SelectionKey.OP_WRITE) != 0) { // Call forceFlush which will also take care of clear the OP_WRITE once there is nothing left to write ch.unsafe().forceFlush();}
其中有这么一句,这里的注释我也抄过来了,就是说,如果轮训到写事件,就去执行forceFlush,然后清理掉OP_WRITE。
回想我们写失败的地方。如果写失败,就给管道注册OP_WRITE,然后Reacotr线程会不断地去select,一旦Channel可用,那么这个Channel由于之前注册了OP_WRITE,就会被Reactor线程select出来,然后进行forceFlush,这个forceFlush其实就是调用了flush0,重新走了一遍flush操作,注意两个地方:
forceFlush不会添加flush节点(不会调用addFlush)
forceFlush不会进行isFlushPending校验
为什么不进行isFlushPending:我们说过了,OP_WRITE的意思是管道不可用,那么被select出来的管道一定是可用的,直接进行写操作。
这样我们就理顺了写失败的流程:
如果写失败,给管道注册一个OP_WRITE
其他的flush操作都会直接返回(被isFlushPending)拦截
管道可用后,被Reacotr线程select到,进行forceFlush操作
收一下,看回到doWrite方法里,如果写成功,进行in.removeBytes(localWrittenBytes);操作,remove掉这个节点。
注意,正常情况下,结束doWrite操作是在:
1234if (in.isEmpty()) { clearOpWrite(); return;}
这里返回的。如果乐观锁的默认16次都循环完,操作还没结束,又会进行incompleteWrite(writeSpinCount < 0)操作,如果执行了16次循环以后,ChannelOutboundBuffer中还有Entry,writeSpinCount < 0成立,设置一个OP_WRITE,然后等着被Reacotr线程select。如果大于0,这种情况比较特殊,写入的ByteBuf或者FileRegion只有一个,但是这个ByteBuf是不可读的,或者region.transferred() >= region.count()。这时候会走到incompleteWrite(false)里,这里执行clearOpWrite();和eventLoop().execute(flushTask);,清理掉OP_WRITE让通道继续可写,然后再次扔了一个flushTask到NioEventLoop里,这里其是让出资源,让Reacotr可以处理其他的task。至此,整个写流程就结束了,写的比较细,大家多多琢磨,多多思考,才会有更多收获!
如果想学习Java工程化、高性能及分布式、深入浅出。微服务、Spring,MyBatis,Netty源码分析的朋友可以加我的Java进阶群:617434785,群里有阿里大牛直播讲解技术,以及Java大型互联网技术的视频免费分享给大家。