博客声明:此文链接地址https://www.cnblogs.com/Vrapile/p/12427326.html,未经允许禁止转载
一、前言说明
1. 功能简述
(1)将chatterbot机器人框架的的聊天与训练功能封装成API接口,并部署在服务器,可以供其它系统调用
(2)额外封装百度图像识别和语音识别的API接口
(3)实现前端后台管理机器人对话的增删改查导等功能
2. 我的开发环境
(1)开发系统环境Win10,运行环境Python3.8,运行工具Pycharm,服务器Centos7.4,前端框架Vue,前端工具VSCode,服务器工具Xshell5和Xftp5,其它
二、接口源码设计
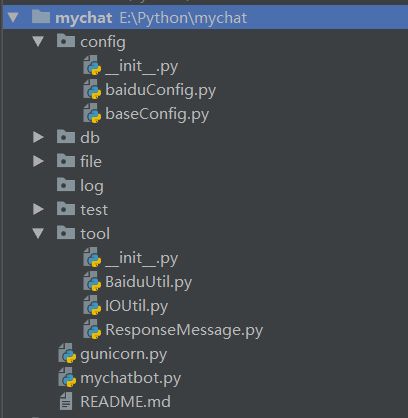
1. 文件结构说明
(1)config包文件夹,放配置文件
(2)db路径文件夹,放本地sqlite3数据库,只需建文件夹即可
(3)file路径文件夹,放临时上传和下载文件,只需建文件夹即可
(4)log路径文件夹,放在服务器运行的日志(只在服务器部署需要)
(5)test包文件夹,放测试代码等,可忽略
(6)tool包文件夹,放封装的公用函数的代码
(7)gunicorn.py,服务器启动配置文件(只在服务器部署需要)
(8)mychatbot.py,系统入口文件
(9)README.md,说明文件
2. 配置config文件
(1)基本配置,含路径baseConfig.py
1 import os 2 3 # 运行路径 4 runPath = os.getcwd() 5 6 # 数据库地址 7 databasePath = "sqlite:///"+os.path.join(runPath, "db/mychat.sqlite3") 8 # databasePath = 'mongodb://localhost:27017/mychat' 9 10 # 导出文件路径 11 export_json_path = os.path.join(runPath, r"file/my_export.json") 12 13 # 导入文件保存路径前缀 14 import_json_path = os.path.join(runPath, r"file")
(2)百度配置baiduConfig.py
其中百度的秘钥和私钥,是博主在百度智能云申请,仅供个人学习使用,禁止作为其它用途 !!!
1 # 百度图像 2 Img_App_ID = "10681976" 3 Img_API_Key = "cHNlTXmj8FG9ZHXtRwQMRXwa" 4 Img_Secret_Key = "CYgOfjxKr2qWGGd8zpmiVgFCPTwK9ivC" 5 Img_Options = { 6 'detect_direction': 'true', 7 'language_type': 'CHN_ENG', 8 } 9 10 # 百度语音 11 Voice_App_ID = "10623076" 12 Voice_API_Key = "2NagVAULCYCnOnamrc8MNUPc" 13 Voice_Secret_Key = "af4860b64e77d187643db05ccdb060e4" 14 Voice_Api_Url = r"http://tts.baidu.com/text2audio" 15 # 参数设置 16 Voice_Api_Set = {"idx": 1, "cuid": "baidu_speech_demo", "cod": 2, "lan": "zh", 17 "ctp": 1, "pdt": 1, "spd": 4, "per": 4, "vol": 5, "pit": 5} 18 # Token认证 19 Voice_OpenApi_Url = r"https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&" \ 20 r"client_id="+Voice_API_Key+"&client_secret="+Voice_Secret_Key 21 # 上传路径 22 Voice_Up_Url = r"http://vop.baidu.com/server_api"
3. 工具tool文件
(1)ResponseMessage.py封装返回的统一接口格式
1 #!/usr/bin/python3 2 # -*- coding: utf-8 -*- 3 """ 4 Created on Feb 23, 2020 5 @author: Vrapile 6 """ 7 8 import json 9 10 retutn_format = {"code": 200, "success": True, "data": "", "message": "", "flag": 0} 11 12 13 def ok(data, code=200): 14 return_dict = retutn_format 15 return_dict["code"] = code 16 return_dict["success"] = True 17 return_dict["data"] = data 18 return_dict["message"] = None 19 return_dict["flag"] = 0 20 return json.dumps(return_dict, ensure_ascii=False) 21 22 23 def error(message, code=500): 24 return_dict = retutn_format 25 return_dict["code"] = code 26 return_dict["success"] = False 27 return_dict["data"] = None 28 return_dict["message"] = message 29 return_dict["flag"] = 1 30 return json.dumps(return_dict, ensure_ascii=False) 31 32 33 def res(data): 34 if data[0]: 35 return ok(data[1]) 36 else: 37 return error(data[1])
(2)BaiduUtil.py百度智能识别封装
1 import json 2 import random 3 import urllib.request 4 import base64 5 from aip import AipOcr 6 from config import baiduConfig 7 from tool import IOUtil 8 9 10 # 百度语音转文本 11 def get_image_content(path): 12 # noinspection PyBroadException 13 try: 14 # 初始化AipFace对象 15 aip = AipOcr(baiduConfig.Img_App_ID, baiduConfig.Img_API_Key, baiduConfig.Img_Secret_Key) 16 # 调用通用文字识别接口 17 result = aip.basicGeneral(IOUtil.get_file_content(path), baiduConfig.Img_Options) 18 return True, result['words_result'] 19 except: 20 return False, "Something Wrong!" 21 22 23 # 百度语音转文本 24 def get_voice_content(path): 25 # 获取access_token 26 token = get_token() 27 data = {} 28 data['format'] = 'wav' 29 data['rate'] = 16000 30 data['channel'] = 1 31 data['cuid'] = str(random.randrange(123456, 999999)) 32 data['token'] = token 33 wav_fp = open(path, 'rb') 34 voice_data = wav_fp.read() 35 data['len'] = len(voice_data) 36 data['speech'] = base64.b64encode(voice_data).decode('utf-8') 37 post_data = json.dumps(data) 38 r_data = urllib.request.urlopen(baiduConfig.Voice_Up_Url, data=bytes(post_data, encoding="utf-8")).read() 39 print(json.loads(r_data)) 40 err = json.loads(r_data)['err_no'] 41 if err == 0: 42 return True, json.loads(r_data)['result'][0] 43 else: 44 return False, json.loads(r_data)['err_msg'] 45 46 47 # 获取百度API调用的认证,实时生成,因为有时间限制 48 def get_token(): 49 token_url = baiduConfig.Voice_OpenApi_Url 50 r_str = urllib.request.urlopen(token_url).read() 51 token_data = json.loads(r_str) 52 token_str = token_data['access_token'] 53 return token_str 54 55 if __name__ == '__main__': 56 filepath = r'E:\Python_Doc\voice_say\beijing.wav' 57 print(get_voice_content(filepath))
(3)IOUtil.py文件交互封装
1 # 读取文件 2 def get_file_content(path): 3 with open(path, 'rb') as fp: 4 return fp.read()
4. gunicorn.py文件,服务器配置文件,只在本地运行不需要
1 #!/usr/bin/python3 2 # -*- coding: utf-8 -*- 3 """ 4 Created on Feb 23, 2020 5 @author: Vrapile 6 """ 7 import multiprocessing 8 9 bind = "127.0.0.1:8000" 10 timeout = 30 11 daemon = True 12 workers = multiprocessing.cpu_count() * 2 + 1 #进程数 13 threads = 2 #指定每个进程开启的线程数 14 loglevel = 'info' #日志级别,这个日志级别指的是错误日志的级别,而访问日志的级别无法设置 15 access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"' #设置gunicorn访问日志格式,错误日志无法设置 16 # proc_name = 'jlchat' 17 accesslog = "/home/python/mychat/log/gunicorn_access.log" #访问日志文件 18 errorlog = "/home/python/mychat/log/gunicorn_error.log" #错误日志文件
5. mychatbot.py文件,启动文件,启动系统运行此文件即可
1 #!/usr/bin/python3 2 # -*- coding: utf-8 -*- 3 """ 4 Created on Feb 23, 2020 5 @author: Vrapile 6 """ 7 8 import os 9 import json 10 from chatterbot import ChatBot 11 from flask import Flask, request 12 from chatterbot.trainers import ListTrainer 13 from chatterbot.trainers import ChatterBotCorpusTrainer 14 from config.baseConfig import databasePath, import_json_path, export_json_path 15 from tool import ResponseMessage, BaiduUtil 16 17 18 mychatbot = Flask(__name__) 19 20 mychat = ChatBot( 21 "mychat", 22 storage_adapter='chatterbot.storage.SQLStorageAdapter', 23 logic_adapters=[ 24 { 25 'import_path': 'chatterbot.logic.BestMatch' 26 }, 27 { 28 'import_path': 'chatterbot.logic.BestMatch', 29 'default_response': 'I am sorry, but I do not understand.', 30 'maximum_similarity_threshold': 0.90 31 } 32 ], 33 read_only=True, # 为False会记录对话并录入训练 34 database_uri=databasePath) 35 36 37 @mychatbot.errorhandler(404) 38 def not_found(error): 39 return ResponseMessage.error("Not found !", 404) 40 41 42 @mychatbot.route("/get_answer", methods=['POST', 'GET']) 43 def get_answer(): 44 # noinspection PyBroadException 45 try: 46 question = request.args.to_dict().get('question') 47 answer = mychat.get_response(question) 48 except: 49 return ResponseMessage.error("Something Wrong!") 50 finally: 51 return ResponseMessage.ok(str(answer)) 52 53 54 @mychatbot.route("/import_qa", methods=["POST"]) 55 def import_qa(): 56 # noinspection PyBroadException 57 try: 58 question = request.values.get("question") 59 answer = request.values.get("answer") 60 except: 61 return ResponseMessage.error("Something Wrong!") 62 list_trainer = ListTrainer(mychat) 63 list_trainer.train([question, answer]) 64 return ResponseMessage.ok("问答对话训练成功!") 65 66 67 @mychatbot.route("/import_jsonfile", methods=["POST"]) 68 def import_jsonfile(): 69 # noinspection PyBroadException 70 try: 71 jsonfile = request.files['jsonfile'] 72 filepath = os.path.join(import_json_path, jsonfile.filename) 73 jsonfile.save(filepath) 74 except: 75 return ResponseMessage.error("Something Wrong!") 76 corpus_trainer = ChatterBotCorpusTrainer(mychat) 77 corpus_trainer.train(filepath) 78 return ResponseMessage.ok("JsonFile训练成功!") 79 80 81 @mychatbot.route("/export_json", methods=['POST', 'GET']) 82 def export_json(): 83 corpus_trainer = ChatterBotCorpusTrainer(mychat) 84 corpus_trainer.export_for_training(export_json_path) 85 with open(export_json_path, 'r', encoding='utf8')as fp: 86 json_data = json.load(fp) 87 return ResponseMessage.ok(json_data) 88 89 90 @mychatbot.route("/get_image_content", methods=["POST"]) 91 def get_image_content(): 92 # noinspection PyBroadException 93 try: 94 imgefile = request.files['imgefile'] 95 filepath = os.path.join(import_json_path, imgefile.filename) 96 imgefile.save(filepath) 97 except: 98 return ResponseMessage.error("Something Wrong!") 99 return ResponseMessage.res(BaiduUtil.get_image_content(filepath)) 100 101 102 @mychatbot.route("/get_voice_content", methods=["POST"]) 103 def get_voice_content(): 104 # noinspection PyBroadException 105 try: 106 voicefile = request.files['voicefile'] 107 filepath = os.path.join(import_json_path, voicefile.filename) 108 voicefile.save(filepath) 109 except: 110 return ResponseMessage.error("Something Wrong!") 111 return ResponseMessage.res(BaiduUtil.get_voice_content(filepath)) 112 113 114 if __name__ == "__main__": 115 mychatbot.run(debug=True)
三、本地运行
1. 打开mychatbot.py,Ctrl+Shift+F10运行此文件,可看控制台是否启动成功,成功情况如下:

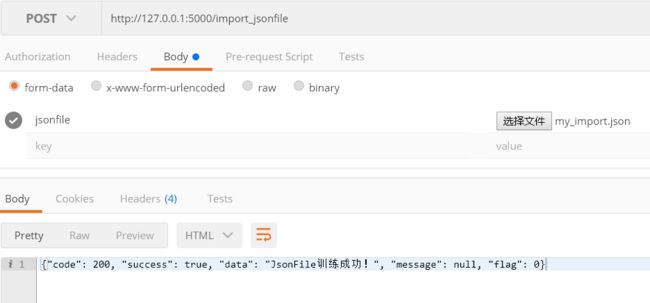
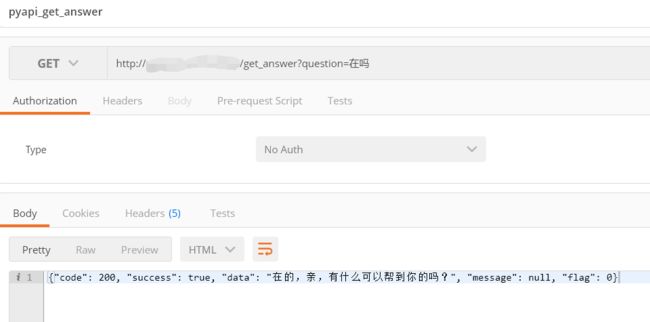
2. Postman请求测试
四、服务器部署
1. 服务器安装python3.8
说明a:博主保留默认python2.7环境变量为python变量,新装python3.8变量为python3
说明b:网上有改python2.7位改为python2,新装python3.8改变量为python,看个人喜好
(1)安装依赖包
yum install -y libffi-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel zlib zlib-devel gcc make
(2)下载python3.8压缩包(最好在/home路径下载,方便后期管理)
wget https://www.python.org/ftp/python/3.8.0/Python-3.8.0.tgz
(3)解压
tar -zxvf Python-3.8.0.tgz
(4)配置安装
cd Python-3.8.0
./configure --prefix=/usr/local/python3
make && make install
(5)添加软链接(如果已经有,改-s为-sf强行替换)
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
2. 服务器安装gunicorn,用于启动python项目
(1)直接pip安装
pip3 install gunicorn
(2)添加软链接
ln -s /usr/local/python3/bin/gunicorn /usr/bin/gunicorn
(3)常用命令介绍
开启服务:gunicorn -c gunicorn.py filename:flaskname
查看服务:pstree -ap|grep gunicorn
重启服务:kill -HUP 99999(99999为上一步查到的主进程ID,上传修改项目文件后,重启即可生效)
关闭服务:kill -9 99999
(4)将常用命令添加到/root/.bashrc
vi /root/.bashrc
****添加内容****
alias cdmychat='cd /home/python/mychat'
alias psgun='pstree -ap|grep gunicorn'
alias gunc='gunicorn -c gunicorn.py'
****添加内容****
source /root/.bashrc
3. 服务器安装mychat项目的依赖
说明a. 我用的全局环境成功的,最好用网上说的Python配置虚拟环境
说明b. 我的方式是,服务器运行报错了,缺什么安装什么的,最好用本地生成requirements.txt方式
(1)安装chatterbot
命令:pip3 install chatterbot,安装的是1.0.5版本,如果失败可以选择源码安装,源码实时是1.1.0版本(2020/03/06),命令如下:
git clone https://github.com/gunthercox/ChatterBot.git
pip install ./ChatterBot
chatterbot会请求spacy>=2.1,<2.2依赖,这个有时会不成功,博主因升级python出现的问题状况比较复杂,但最终还是解决了,如果失败,可以评论区留言询问
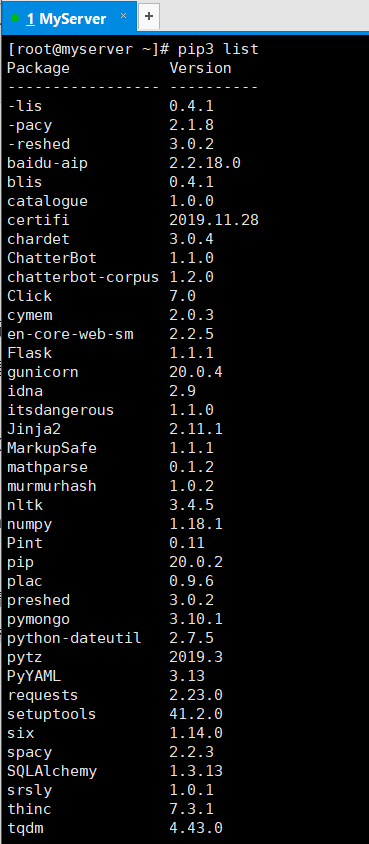
(2)安装其它依赖,以下是本人服务器安装依赖包情况,不必完全一样或者照搬,能运行就好
查看所有依赖的命令:pip3 list
(3)运行项目系统
将文件上传到服务器
启动命令:gunc mychatbot:mychatbot
查看命令:psgun
(如果运行报错,查看/home/python/mychat/loggunicorn_error.log报错内容,一般是缺少依赖,对应安装依赖就好)
(3)nginx把域名转接到gunicorn.py中配置的端口,在nginx.conf添加并重启nginx
# python的api应用
server {
listen 80;
server_name 你的API域名地址;
location / {
root html;
index index.html index.htm;
proxy_pass http://127.0.0.1:8000;
}
}
(不用nginx也可以端口地址访问,需阿里云开启8000端口,如果服务器上防火墙开启也要开启8000端口)
(4)验证是否成功,同上面可以用浏览或Postman测试
五、前端开发
1. 此部分不做详细介绍只放效果图
(1)脚手架直接弄个Vue工程
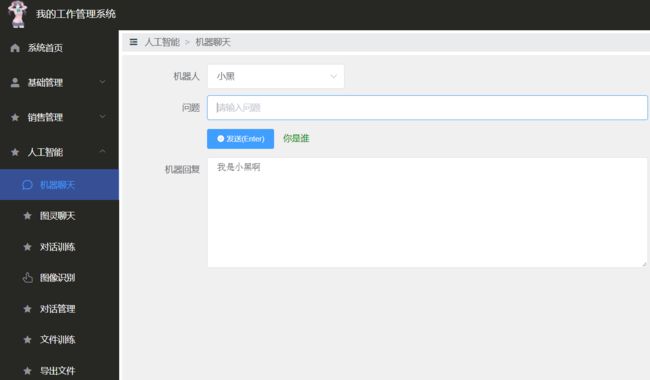
(2)所写API接口可以嵌入其它任何项目,部署后部分效果界面(python源码需相应改动支持)
(机器聊天,选择机器人,我这里有sqlite3和mongo两种数据库的机器人,每个机器人我分开建立一个数据库)
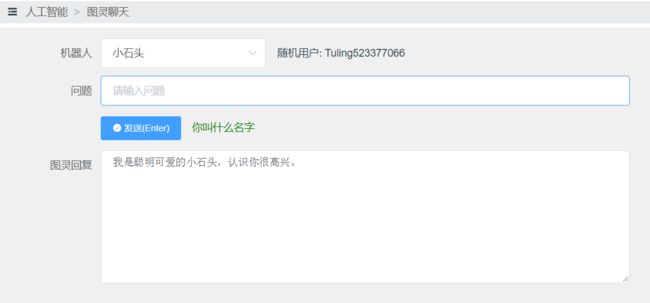
(图灵聊天,调用Tuling的Api实现)
(Json训练,可直接导入Json文件训练,适合数据库迁移)

(对话管理,可对训练语句进行删改查导出)

(手机端-只加了聊天界面)
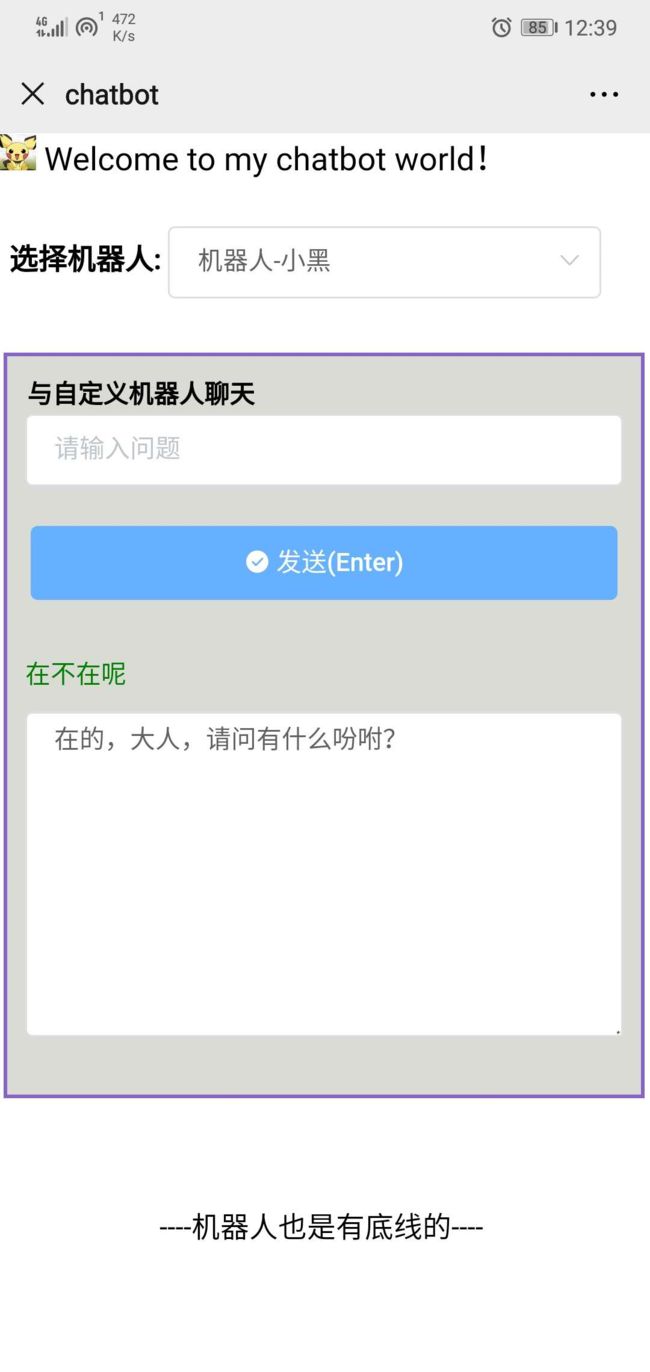
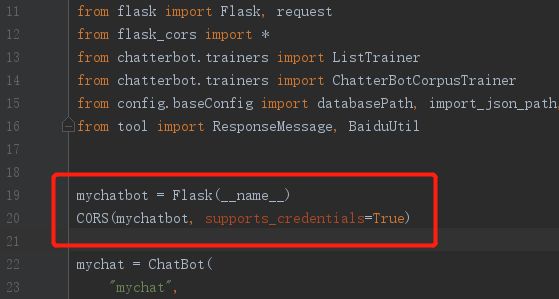
(3)VUE访问会有跨域问题,我选择在mychatbot.py中引入flash_cors包,在接口添加:CORS(mychatbot, supports_credentials=True)
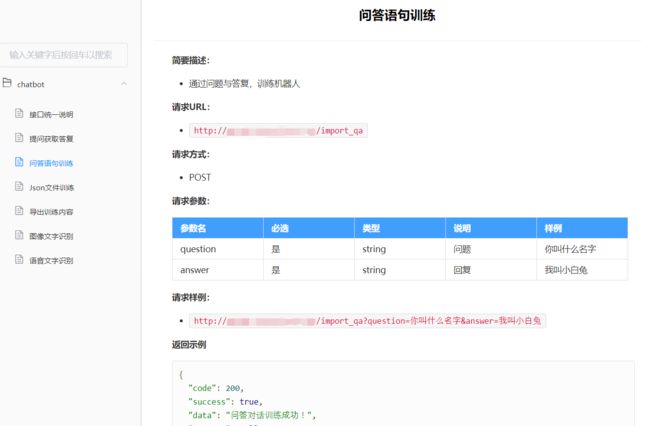
六、编写接口文档
1. 博主自己服务器搭建的showdoc,用起来挺方便的,下面是接口文档样式
七、总结
1. 后端开发的代码较简单,难的环境搭建,我本地环境从Python3.6升级到3.8折腾了一两天,服务器搭建也折腾了两三天,最终证实这个是可以实现的。
2. chatterbot的主要工作在于训练,核心价值在于取相似问题的算法,深入学习和了解可以自行注入算法。
3. 作为商用聊天机器人,还需要一个相似问题查看的API接口,目前还在钻研中(场景类似于:输入一个问题,匹配返回最相似的五个问题,选择要问的那个问题)
4. 上文中的图像识别和语音识别是调用百度的API,如果商用还需考虑费用问题