多进程
- 什么是进程
一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
不仅可以通过线程完成多任务,进程也是可以的
- 进程的状态
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态
- 就绪态:运行的条件都已经慢去,正在等在cpu执行
- 执行态:cpu正在执行其功能
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
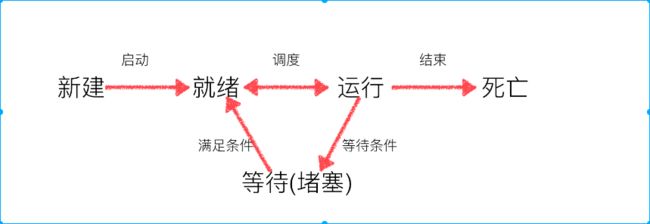
image.png
进程的创建-multiprocessing
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
例1
# -*- coding:utf-8 -*-
from multiprocessing import Process
import time
def run_proc():
"""子进程要执行的代码"""
while True:
print("----2----")
time.sleep(1)
if __name__=='__main__':
p = Process(target=run_proc)
p.start()
while True:
print("----1----")
time.sleep(1)
注意:创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
例2
# -*- coding:utf-8 -*-
from multiprocessing import Process
import os
import time
def run_proc():
"""子进程要执行的代码"""
print('子进程运行中,pid=%d...' % os.getpid()) # os.getpid获取当前进程的进程号
print('子进程将要结束...')
if __name__ == '__main__':
print('父进程pid: %d' % os.getpid()) # os.getpid获取当前进程的进程号
p = Process(target=run_proc)
print(p.name)
p.start()
- Process参数如下:
Process(group, target, name, args , kwargs)
- target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码
- args:给target指定的函数传递的参数,以元组的方式传递
- kwargs:给target指定的函数传递命名参数
- name:给进程设定一个名字,可以不设定
- group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法: - start():启动子进程实例(创建子进程)
- is_alive():判断进程子进程是否还在活着
- join([timeout]):是否等待子进程执行结束,或等待多少秒
- terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性: - name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
- pid:当前进程的pid(进程号)
- 给子进程指定的函数传递参数
# -*- coding:utf-8 -*-
from multiprocessing import Process
import os
from time import sleep
def run_proc(name, age, **kwargs):
for i in range(10):
print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid()))
print(kwargs)
sleep(0.2)
if __name__=='__main__':
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
p.start()
sleep(1) # 1秒中之后,立即结束子进程
p.terminate()
p.join()
- 进程间不同享全局变量
from multiprocessing import Process
import time,queue
queue = queue.Queue(200)
def write_data():
for i in range(0,200):
global queue
queue.put(i)
print(queue.full())
def get_data():
print('-----')
global queue
while queue.empty() is not True:
print(queue.get())
if __name__ == '__main__':
process1 = Process(target=write_data)
process1.start()
process1.join()
process2 = Process(target=get_data)
process2.start()
进程间通信-Queue:
Process之间有时需要通信,操作系统提供了很多机制来实现进程间的通信。
- Queue的使用 可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序
#coding=utf-8
from multiprocessing import Queue
q=Queue(3) #初始化一个Queue对象,最多可接收三条put消息
q.put("消息1")
q.put("消息2")
print(q.full()) #False
q.put("消息3")
print(q.full()) #True
#因为消息列队已满下面的try都会抛出异常,第一个try会等待2秒后再抛出异常,第二个Try会立刻抛出异常
try:
q.put("消息4",True,2)
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
try:
q.put_nowait("消息4")
except:
print("消息列队已满,现有消息数量:%s"%q.qsize())
#推荐的方式,先判断消息列队是否已满,再写入
if not q.full():
q.put_nowait("消息4")
#读取消息时,先判断消息列队是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
说明:
- Queue.qsize():返回当前队列包含的消息数量;
- Queue.empty():如果队列为空,返回True,反之False ;
- Queue.full():如果队列满了,返回True,反之False;
- Queue.get(block, timeout):获取队列中的一条消息,然后将其从列队中移除,block默认值为True;
- Queue.get_nowait():相当Queue.get(False);
- Queue.put(item,block,timeout):将item消息写入队列,block默认值为True;
- Queue.put_nowait(item):相当Queue.put(item, False);
进程池的概念
python中,进程池内部会维护一个进程序列。当需要时,程序会去进程池中获取一个进程。
如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止。
multiprocessing.Pool常用函数解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
- close():关闭Pool,使其不再接受新的任务;
- terminate():不管任务是否完成,立即终止;
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用;
进程池中中进程通信Manager().Queue()
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
代码
#如何使用进程池
# from multiprocessing import Pool
# import requests
# def download_data_by_page(page,name):
# print(page,name)
# #http://blog.jobbole.com/all-posts/page/2/
# full_url = 'http://blog.jobbole.com/all-posts/page/%s/' % str(page)
# req_headers = {
# 'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
# }
# response = requests.get(full_url,headers=req_headers)
# if response.status_code == 200:
# print(response.text)
# #可以在这里做数据解析
# if __name__ == '__main__':
# #创建一个进程池
# process_pool = Pool(4)
# for page in range(0,1000):
# #往进程池中添加任务
# process_pool.apply_async(download_data_by_page,(1,'进程池'))
# #关闭进程池,后面不能再添加任务了
# process_pool.close()
# #子进程先执行,执行完毕后,再继续执行主进程代码
# process_pool.join()
#python自带的进程池模块
from concurrent.futures import ProcessPoolExecutor
import requests
def download_data_by_page(page,name):
print(page,name)
full_url = 'http://blog.jobbole.com/all-posts/page/%s/' % str(page)
req_headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
response = requests.get(full_url,headers=req_headers)
if response.status_code == 200:
print(response.status_code)
#可以在这里做数据解析
return response.text
#可以在回调函数中做数据解析
def download_done(future):
print(future.result())
if __name__ == '__main__':
#创建一个进程池
pool = ProcessPoolExecutor(4)
for page in range(0,100):
handler = pool.submit(download_data_by_page,page,'下载任务')
handler.add_done_callback(download_done)
pool.shutdown()
# python的多线程:
# 有一个全局解释器锁(GIL):意味着python中的多线程其实是并发的操作
# 对比线程和进程
# 1.定义:
# 进程:是操作系统分配资源和调度的基本单元
# 线程:是依赖于进程执行,线程是cpu执行调度的最小单元
# 2.区别:
# 进程是会分配资源空间,每一个进程之间的资源不共享
# 线程不占用资源空间,线程之间的资源是共享的,为了防止资源错乱,我们一般加线程锁
# 3.使用场景:
# 进程一般情况下处理计算密集型任务
# 线程一般处理I/O密集型任务