一、Node.js来历
随着智能手机和H5的不断普及,JavaScript脚本语言的重要性也随之不断提升,2009年,it界指定了commonJS标准,用于标准化服务器JavaScript脚本云,制定服务器JavaScript脚本语言中所需要实现的处理,同年,美国人Ryan Dahl推出了一个遵循commonJS标准的服务器端JavaScript脚本语言开发框架——Node.js ,在Node.js内部,运行的是Google开发的高性能的V8 JavaScript脚本语言,该语言可以运行在服务器端。
二、Node.js的特点
单线程
在Java、PHP或者.net等服务器端语言中,会为每一个客户端连接创建一个新的线程。而每个线程需要耗费大约2MB内存。也就是说,理论上,一个8GB内存的服务器可以同时连接的最大用户数为4000个左右。要让Web应用程序支持更多的用户,就需要增加服务器的数量,而Web应用程序的硬件成本当然就上升了。
Node.js不为每个客户连接创建一个新的线程,而仅仅使用一个线程。当有用户连接了,就触发一个内部事件,通过非阻塞I/O、事件驱动机制,让Node.js程序宏观上也是并行的。使用Node.js,一个8GB内存的服务器,可以同时处理超过4万用户的连接。
另外,单线程的带来的好处,还有操作系统完全不再有线程创建、销毁的时间开销。
坏处,就是一个用户造成了线程的崩溃,整个服务都崩溃了,其他人也崩溃了。
非阻塞I/O non-blocking I/O
JavaScript脚本语言一个特征就是它只支持单线程。但是Node.js中为V8 JavaScript脚本语言提供了非阻塞I/0机制。
例如,当在访问数据库取得数据的时候,需要一段时间。在传统的单线程处理机制中,在执行了访问数据库代码之后,整个线程都将暂停下来,等待数据库返回结果,才能执行后面的代码。也就是说,I/O阻塞了代码的执行,极大地降低了程序的执行效率。
由于Node.js中采用了非阻塞型I/O机制,因此在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率。
当某个I/O执行完毕时,将以事件的形式通知执行I/O操作的线程,线程执行这个事件的回调函数。为了处理异步I/O,线程必须有事件循环,不断的检查有没有未处理的事件,依次予以处理。
阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,这个线程的CPU核心利用率永远是100%。
事件驱动 event-driven
在Node中,客户端请求建立连接,提交数据等行为,会触发相应的事件。在Node中,在一个时刻,只能执行一个事件回调函数,但是在执行一个事件回调函数的中途,可以转而处理其他事件(比如,又有新用户连接了),然后返回继续执行原事件的回调函数,这种处理机制,称为“事件环”机制
三、Node.js 适合开发的应用程序
当应用程序需要处理大量并发的输入/输出,而在向客户端发出响应之前,应用程序内部并不需要进行非常复杂的处理的时候,我们可以考虑使用Node.js来进行该应用程序的开发,例如如下应用:
1、聊天服务器:在一个具有很高人气的聊天应用程序中,在同一刻可能存在大量用户和服务器之间的并发连接,而服务器本身不存在非常复杂的处理。
2、综合服务类网站或电子商务网站的服务器:这些网站旺旺可能每秒接收上千条数据并且需要写入数据库,Node.js对于实现这些数据到数据库中的写入,而不必再为每条数据的写入等待一段时间。
四、安装Node.js
Node.js官网(http://nodejs.cn/api/fs.html)上提供了Windows与Mac版本的安装程序,以及Linux版本的源代码,执行安装程序就可以将Node.js安装在我们的计算机中。
在Windows操作系统中默认安装路径是C:\Program Files\nodejs,执行文件为node.exe ;在Mac操作系统中的默认安装路径为/usr/local/bin,执行文件是node。
五、Node.js中的模块
在客户端可以将所有JavaScript代码分割为几个JS文件,然后在浏览器中将这些js文件合并运行,但是在Node.js中是通过以模块为单位 来划分所有功能的,每一个模块为一个js文件,每一个模块中定义的全局变量或函数的作用范围也被先定在这个模块之内,只有使用exports对象才能将其传递到外部。
exports.printPoo = function(){ return "foo" }
在上面这行代码中,定义一个printPoo函数,同时用exports对象使模块外部可以访问这个printPoo函数。
在引用模块时,我们需要使用require函数。例如,我们将上行代码保存为foo.js文件之后,可以通过以下代码来访问模块中的printPoo函数。
var foo = require(./foo.js) ; //通过foo.js文件路径加载foo.js模块
console.log( foo.printPoo() ) ;//访问foo.js模块内的printPoo函数
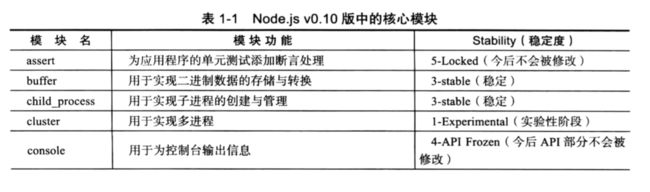
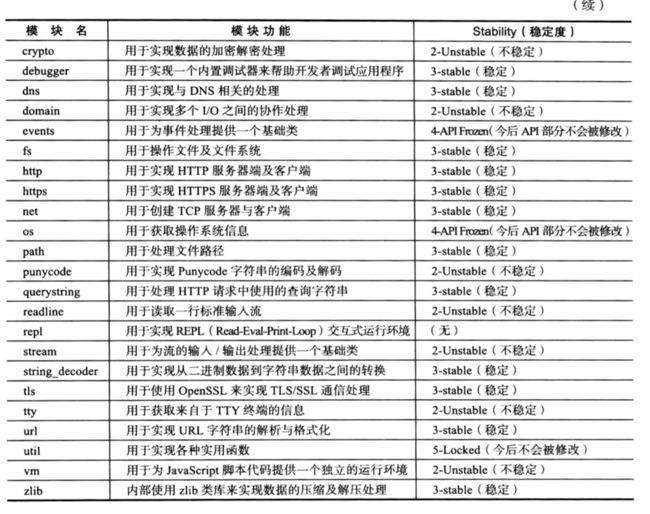
在Node.js中,提供了一些核心代码块,其中v0.10版中的魔铠以及作用见表
六、一个简单的示例应用程序
//使用http对象来引用http模块
var http = require("http");
// 创建一个服务器,回调函数表示接收到请求之后做的事情
var server = http.createServer(function(req,res){
// req参数表示请求,res表示相应
res.writeHead(200,{"Content-type":"text/html;charset=UTF-8"});
// req.url表示请求地址
console.log("服务器请求了"+req.url)
// 每一个请求都要res.end()
res.write("我是标题
")
res.write("我是标题
")
res.write("我是标题
")
res.write("我是标题
")
res.write("我是标题
")
res.end("我是文字");
// res.end() 里面必须设置成字符串或者是buffer类型
});
//监听3000端口
server.listen(3000,"127.0.0.1");
那我现在打开本地的3000端口,就可以显示页面内容

今天就这样了,已凌晨2点,不胡思乱想的最好方式是让自己忙起来。
程序媛妹子不易,喜欢就点赞,后续会陆续更新。