- 导言
- 二叉堆
- 简单提一下树
- 完全二叉树
- 堆
- 堆的存储方式
- 简单提一下树
- 堆的操作
- 调整堆
- 伪代码
- 代码实现
- 建初堆
- 伪代码
- 代码实现
- 调整堆
- 优先级队列
- 按照优先级出队列
- 优先级队列结构体定义
- 入队列操作
- 上滤
- 模拟入队列
- 伪代码
- 代码实现
- 出队列操作
- 下滤
- 模拟出队列
- 伪代码
- 代码实现
- C++ STL priority_queue
- 容器定义形式
- 使用例
- 容器定义形式
- 简单应用
- 应用解析
- 代码实现(STL 库实现)
- 运行结果
- 按照优先级出队列
- 情景应用
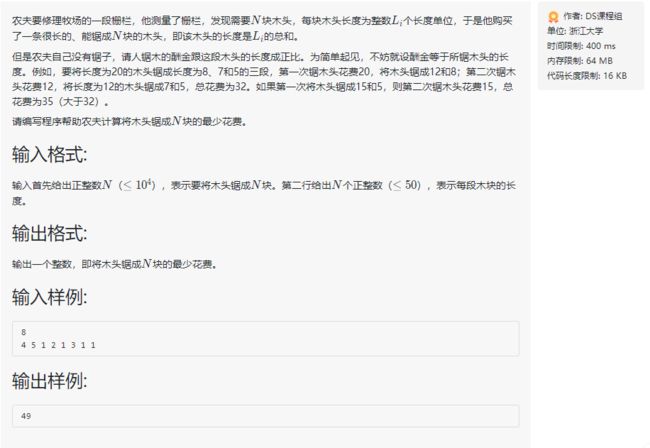
- 修理牧场
- 情景模拟
- 代码实现
- 堆排序
- 参考资料
导言
“聚沙成塔,集腋成裘”,使我们非常熟悉的名言警句,其中“聚沙成塔意思”是聚细沙成宝塔,原指儿童堆塔游戏,后比喻积少成多。如果我们把这座塔抽象成一个数据结构的话,那么每一粒沙子都是结构中的元素,而这些元素不断地往上堆积,最终形成了沙堆,对于这个沙堆来说,如果我们把沙堆按高度分成多层,那么每一层的沙子数量都各不相同,上层的沙子数小于下层的沙子数。这样的描述就和能够大致地理解我们要提的堆结构。

二叉堆
简单提一下树
树结构是 n 个结点的有限集合,有且仅有一个根结点,其余结点可分为m个根结点的子树。例如:

二叉树是每个节点最多拥有两个子节点,左子树和右子树是有顺序的不能任意颠倒。

满二叉树是层数为 n,结点数量为 2n-1 个的二叉树结构。
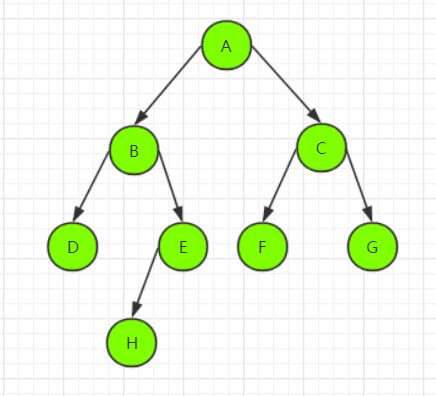
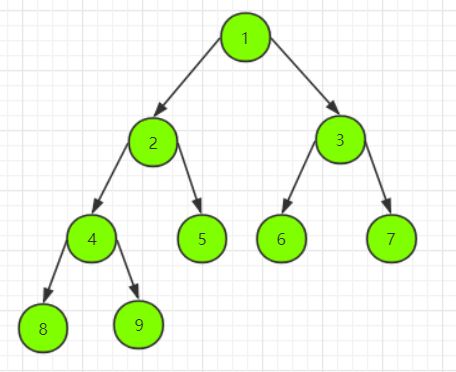
完全二叉树
完全二叉树的特点在于,二叉树生成结点的顺序必须严格按照从上到下,从左往右的顺序来生成结点,例如下面3张图片都是完全二叉树。
而这种二叉树就不属于完全二叉树。

堆
一个数据结构是堆结构,需要满足两个条件:第一,结构是一个完全二叉树;第二,每个父结点的值都不小于其子结点的值,这样的堆结构被称为大顶堆,而每个父结点的值都不大于其子结点的值的堆为小顶堆。例如图一是大顶堆,图二是小顶堆:


这样的结构又叫做二叉堆,其根结点叫做堆顶,无论是大顶堆还是小顶堆,都决定了堆顶元素的值是整个堆中的最大或最小元素。
堆的存储方式
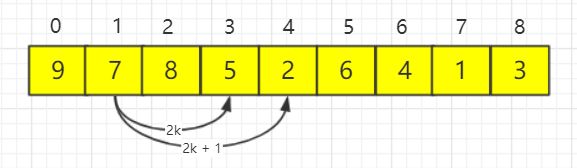
我们在描述二叉堆时,虽然它是完全二叉树,但它适合的的存储方式并不是链式存储,而是顺序存储,我们可以用一个数组来组织。这是因为如果我们按照从上到下,从左到右的顺序遍历完全二叉树时,顺序是这样的:
那么我们就会发现,设父结点的序号为 k,则子结点的序号会分别为 2k 和 2k + 1,子结点的序号和父结点都是相互对应的,因此我们可以用顺序存储结构来描述二叉堆,例如上文的大顶堆:
堆的操作
调整堆
首先我们先来解决数据调整的问题,也就是说当我们去掉堆顶的元素之后,我们需要保证剩下的元素能够重构成一个新的堆。直接放个例子,假设有如图所示大顶堆:

下面我们把堆顶贬到最底层,然后根据插入的规则从上到下,从左到右来选择替换的结点,得到这样的状态:
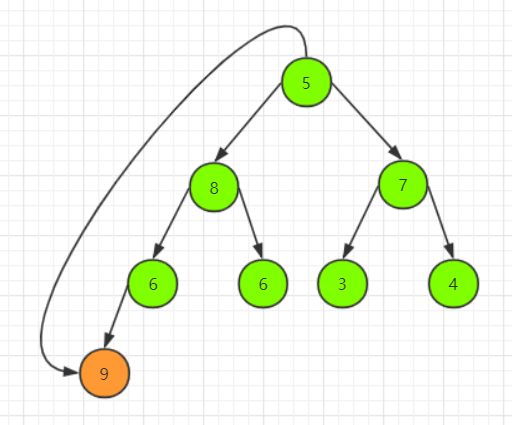
此时我们就需要进行堆的调整,由于此时除根结点外,其余结点均满足堆的两个条件,由此仅需由上向下调整一条路径的结点即可。首先以堆顶元素 5 和其左、右子树根结点的值进行比较,由于左子树根结点的值 8 大于右子树根结点的值 7 且大于根结点的值,因此进行操作使 5 下沉,8上浮。由于 8 替代了 5 之后破坏了左子树的子堆,因此需从上向下进行和上述相同的调整:
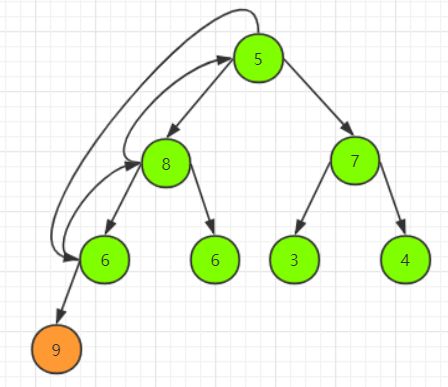
我们需要重复执行直至叶子结点,调整后得到新的堆:

现在请你自行模拟一遍上述大顶堆堆顶退出的过程,得到的新堆为:
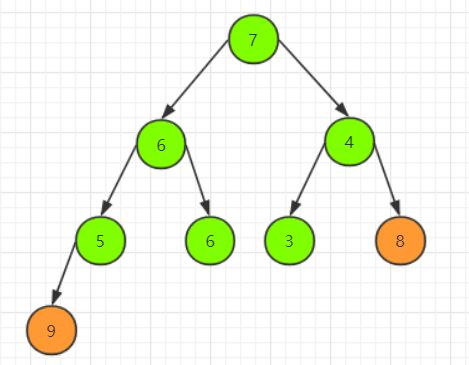
在模拟中,我们使用了从上到下,层层筛选,合适的元素上浮,不合适的元素下沉,就像筛子一样把合适的数据筛选出来一样,这种调整堆的方式被称为筛选法。
伪代码

代码实现
void Heapify(SqList &L,int s,int m)
{ //假设线性表的 data 成员中,data[s + 1…m] 已经是堆,现将 data[s…m] 调整为以 data[s] 为根的大顶堆
data_root = L.data[s];
for(i = 2*s; i <= m; i *= 2) //沿着 key 较大的子结点向下筛选
{
if(i < m && L.data[i].key < L.data[i].key) //i 记录 key 较大的下标
i++;
if(data_root.key >= L.data[i].key) //找到 data_root 的插入位置
break;
L.data[s] = L.data[i];
s = i;
}
L.data[s] = data_root;
}
建初堆
现在我们有个顺序表,这个顺序表的数据是无序的,因此要把这个顺序表描述为堆结构,就必须令其满足上述两个条件,即完全二叉树中的每一个结点的子树都要是一个堆结构。对于一个完全二叉树来说,所有序号大于 n / 2 的结点都是子叶,而只有一个结点的树显然是堆,因此建初堆的操作本质上就是一个所有非叶子节点依次下沉的过程。例如有如图顺序表:

首先我们需要操作的是 1 号结点,1 号结点小于它的子结点,因此它需要下沉:

接下来是 7 号结点,7 号结点小于它的子结点,因此它需要下沉:

接下来是 9 号结点,7 号结点不小于它的子结点,因此它不需要下沉。接下来是 4 号结点,4 号结点小于它的子结点,因此它需要下沉:
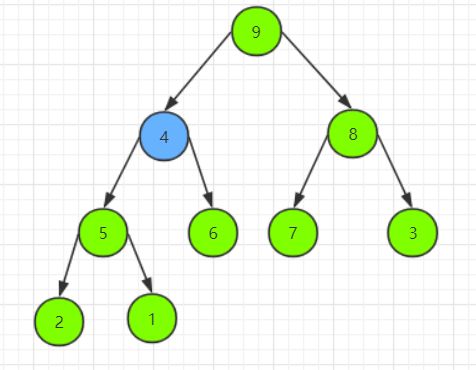
此时 4 号结点仍小于它的子结点,因此它需要继续下沉:

现在我们就把一个无序的完全二叉树整理为一个堆结构了。
伪代码
其实思路是很明确的,我们只需要吧序号为 n / 2、n / 2 - 1、…、1 的结点作为根的子树统统搞成堆即可。加上我们在刚才已经写了筛选法的代码,现在这件事情就变得简单了。

代码实现
void CreatHeap(SqList &L)
{ //现以无序序列 data[1…n] 建立大顶堆
for(int i = L.length / 2; i > 0; i--)
{
Heapify(L,i,L.length);
}
}
优先级队列
按照优先级出队列
对于一个队列结构而言,队列中的元素遵循着先进先出,后进后出的规则,元素只能队列尾进入,出队列则是队列头的元素。而我们现在要谈的优先级队列则是队列不再遵循先入先出的原则,而是分为两种情况:最大优先队列,无论入队顺序,当前最大的元素优先出队。最小优先队列,无论入队顺序,当前最小的元素优先出队。例如这个队列,我们设这个队列是个最小优先队列,因此当这个队列执行出队操作的时候,出队的元素为 1。要满足如此的需求,我们利用线性表的基本操作同样可以实现,但是这么做最坏时间复杂度O(n),也就是我们要遍历这个队列,显然这并不是最佳的方式。

我们来回忆一下二叉堆,对于一个二叉堆而言,大顶堆的堆顶是整个堆中的最大元素,小顶堆的堆顶是整个堆中的最小元素。因此,当我们使用大顶堆来实现最大优先队列时,入队列操作就是堆的插入操作,出队列操作就是删除堆顶节点。假设我们有如图所示大顶堆:

优先级队列结构体定义
同顺序表,不过我们的目的是用顺序存储结构描述堆结构。
typedef struct HeapStruct
{
int size;
ElemType data[MAXSIZE];
}*PriorityQueue;
入队列操作
上滤
入队列操作一般使用的策略叫做上滤(percolate up,即新元素在堆中上滤直到找出正确的位置(设堆为 H,待插入的元素为 e,首先在 size + 1 的位置建立一个空穴,然后比较 e 和空穴的父结点的大小,把较小的父亲换下来,以此推进,最后把 e 放到合适的位置,该算法时间复杂度为O(㏒n)。
模拟入队列
假设要在上述大顶堆插入结点 10,首先我们直接将结点按照完全二叉树的规则入堆:

接着我们将结点依次上浮到合适的位置:



伪代码

代码实现
void Insert( ElemType e, PriorityQueue H )
{
if (H->Size == MAXSIZE)
{
cout << "Priority queue is full" ;
return ;
}
for (int i = ++H->size; H->data[i / 2] < e; i /= 2) //查找合适的位置
H->data[i] = H->Elements[i / 2]; //上浮操作
H->data[i] = e; //插入元素
}
出队列操作
下滤
出队列的算法就是直接将堆顶元素出队列,然后将堆顶的元素替换为在完全二叉树中对应最后一个元素,接着使用筛选法,逐层推进把较大的子结点换到上层,该算法时间复杂度为O(㏒n)。
模拟出队列
直接将堆顶元素出堆即可。

接下来令完全二叉树的最后一个结点成为堆顶,即结点 4。
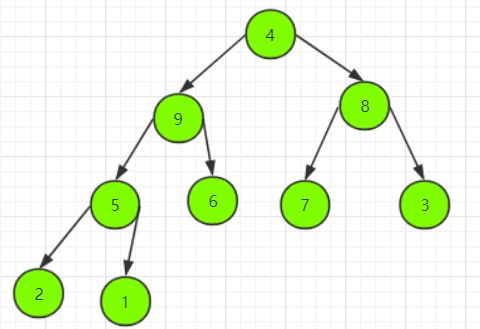
然后利用筛选法将结点 4 下沉到合适的位置,完成操作。
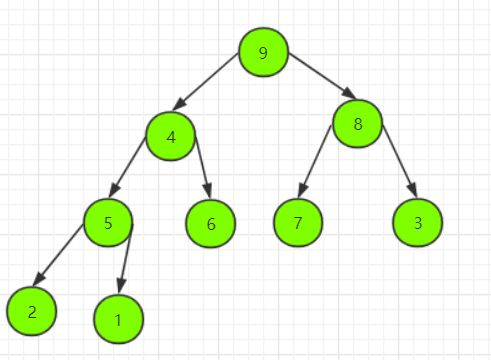

伪代码

代码实现
ElemType DeleteMax( PriorityQueue H )
{
int Child;
ElemType Max, LastElem;
if ( H->size == 0 )
{
cout << "Priority queue is empty!";
return H->data[0];
}
Max = H->data[1]; //最大元素出队列
LastEleme = H->data[H->Size--]; //最后一个结点替代堆顶
for (int i = 1; i * 2 <= H->size; i = Child )
{
Child = i * 2; //定位到下一层,寻找更大的子结点
if ( Child != H->Size && H->data[Child + 1] > H->data[Child] )
Child++;
if ( LastElem > H->data[Child] ) //结点下沉
H->data[i] = H->data[Child];
else //下沉结束
break;
}
H->data[i] = LastElem;
return Max;
}
C++ STL priority_queue
STL 真是 C++ 为我们提供的神兵利器,STL 中为我们封装好了最小优先队列和最大优先队列,包含于头文件:
#include
优先队列具有队列的所有特性,只是在这基础上添加了优先级出队列的机制,它本质是一个堆实现的,不过能够使用队列的基本操作:
| 方法 | 操作 |
|---|---|
| top | 访问队头元素 |
| empty | 判断是否为空队列 |
| size | 返回队列内元素个数 |
| push | 元素从队尾入队列(并排序) |
| emplace | 构造一个结点并入队列 |
| pop | 队头元素出队里 |
| swap | 交换元素内容 |
容器定义形式
priority_queue
| 参数 | 作用 |
|---|---|
| Type | 数据类型 |
| Container | 容器类型,必须是用数组实现的容器,例如vector(默认)、deque,不能用 list |
| Functional | 比较的方式 |
这些参数当我们需要用自定义的数据类型时才需要传入,使用基本数据类型时只需要传入数据类型,默认使用大顶堆实现优先级队列。
使用例
priority_queue ,greater > q; //升序队列
priority_queue ,less >q; //降序队列
简单应用
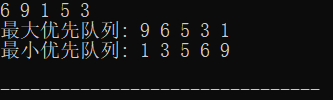
要求构造两个优先级队列,分别是最小优先队列和最大优先队列,随机输入 5 个数字,分别用大顶堆和小顶堆进行组织,之后将两个队列输出。
应用解析
我们可以将上述代码封装好,引入顺序队列的其他操作函数来构造队列,或者是直接使用 C++ 的 STL 库来实现也能达成目的。
代码实现(STL 库实现)

运行结果
情景应用
修理牧场
情景模拟
为了使费用最省,我们使用贪心算法的思想,每一次选择最小的两段木头拼回去,直到将所有木头拼成一段完整的木头,每次一拼接都计算一次费用。我们发现,优先级队列也是可以实现贪心算法的。

我们首先需要先把这个队列修改成小顶堆,方便我们实现优先级队列。

接下来令两个元素出队列,计算一次费用,然后将两个元素之和的数字入队列。

重复上述操作,使的队列只剩一个元素。






代码实现
#include
using namespace std;
void heapify(int a_heap[], int idx1, int idx2);
void creatHeap(int a_heap[], int n);
int main()
{
int a_heap[10001];
int count;
int i;
int num1, num2;
int money = 0;
cin >> count;
for (i = 1; i <= count; i++)
{
cin >> a_heap[i];
}
creatHeap(a_heap, count);
while (count != 1)
{
num1 = a_heap[1]; //最小的两个数字出队列
if (count == 2 || a_heap[2] <= a_heap[3])
i = 2;
else
i = 3;
num2 = a_heap[i];
money += num1 + num2; //计算一次费用
a_heap[1] = num1 + num2; //两个数字之和入队列
a_heap[i] = a_heap[count--];
creatHeap(a_heap, count); //调整堆
/*for (int j = 1; j <= count; j++)
{
cout << a_heap[j] << " ";
}
cout << money << endl;*/
}
cout << money;
return 0;
}
void heapify(int a_heap[], int idx1, int idx2)
{
int insert_node = a_heap[idx1];
for (int i = 2 * idx1; i <= idx2; i *= 2)
{
if (i < idx2 && a_heap[i] > a_heap[i + 1])
{
i++;
}
if (insert_node <= a_heap[i])
{
break;
}
a_heap[idx1] = a_heap[i];
idx1 = i;
}
a_heap[idx1] = insert_node;
}
void creatHeap(int a_heap[], int n)
{
for (int i = n / 2; i > 0; i--)
{
heapify(a_heap, i, n);
}
}
堆排序
参考资料
《大话数据结构》—— 程杰 著,清华大学出版社
《数据结构教程》—— 李春葆 主编,清华大学出版社
《数据结构(C语言版|第二版)》—— 严蔚敏 李冬梅 吴伟民 编著,人民邮电出版社
《数据结构与算法分析 (C语言描述)》—— Mark Allen Weiss著
二叉堆
堆排序(heapsort)
c++优先队列(priority_queue)用法详解
优先队列(堆) - C语言实现(摘自数据结构与算法分析 C语言描述)
漫画:什么是优先队列?
树、二叉树(完全二叉树、满二叉树)概念图解