本课主要是统计学常识。 很多概念都值得背诵下来。
描述统计量
- 集中趋势
- 均值
- 中位数
- 众数
- 离散程度
- 全距
- 四分位距
- 方差、标准差
- 两个变量的关系
- 协方差
- 相关系数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
df = pd.read_csv('HRSalaries.csv')
df.head()
len(df)
30284
- 一共有30284行信息
我觉得列名称太麻烦了,还是把列名改简单点吧
df.columns=['id','p_ti','dep','an_s','re_s']
df.head()
- 这是我尝试使用上节课的技巧 --修改列名
df.dep.value_counts()
- 打这行代码时,犯了很多错误。
错误记录1:value_counts是有下面横杠的,我没有写。
个人理解:value_counts方法相当于分类统计。把同一类的汇总起来,数一下有多少个。 只是groupby,是把分类成一堆,后面再接一个函数执行不同的运算。
value_counts方法就像你家里养了鸡鸭鹅三种动物,它们住在一起的。 老大去把鸡赶到一堆,鸭赶到一堆,鹅赶到一堆,然后分别数了一下,得出结论鸡5只,鸭6只,鹅3只。这就是value_counts,或者groupby()size()方法
但老二,不会数数,就只是把鸡鸭鹅赶到不同的堆数里了(groupby);然后再叫妈妈来称重,妈妈称好重后,算了一下平均每只鸡重2斤,鸭重3斤,鹅6斤,这就是groupby()mean()方法
POLICE 12461
FIRE 4798
SANITATION 2092
WATER MGMT 1796
AVIATION 1252
TRANSPORTATION 1196
EMERGENCY MGMT 1182
GENERAL SERVICES 922
PUBLIC LIBRARY 874
FAMILY & SUPPORT 719
HEALTH 568
FINANCE 533
LAW 455
CITY COUNCIL 265
BUILDINGS 261
COMMUNITY DEVELOPMENT 216
BUSINESS AFFAIRS 177
DoIT 97
MAYOR'S OFFICE 96
PROCUREMENT 77
CULTURAL AFFAIRS 76
HUMAN RESOURCES 61
ANIMAL CONTRL 57
DISABILITIES 29
TREASURER 24
Name: dep, dtype: int64
df.groupby('dep').size()
此方法与value_counts()等效。
dep
ANIMAL CONTRL 57
AVIATION 1252
BUILDINGS 261
BUSINESS AFFAIRS 177
CITY COUNCIL 265
COMMUNITY DEVELOPMENT 216
CULTURAL AFFAIRS 76
DISABILITIES 29
DoIT 97
EMERGENCY MGMT 1182
FAMILY & SUPPORT 719
FINANCE 533
FIRE 4798
GENERAL SERVICES 922
HEALTH 568
HUMAN RESOURCES 61
LAW 455
MAYOR'S OFFICE 96
POLICE 12461
PROCUREMENT 77
PUBLIC LIBRARY 874
SANITATION 2092
TRANSPORTATION 1196
TREASURER 24
WATER MGMT 1796
dtype: int64
len(df.dep.unique())
- 新知识点: .unique(). 这个方法的意思是找到列表的唯一值。
- 相当于是把dep的部门名称做成列表,再用len来计算列表长度
25
集中趋势
均值
算数平均值
$$ \frac{\sum_i x_i}{N}$$
salary = df.an_s
salary.head()
df.head()
salary.head()
0 16140
1 71506
2 61085
3 81928
4 50379
Name: an_s, dtype: int64
salary.sum()/len(salary)
## 求得工资金额,然后除以领工资人数。当然这是笨办法
60836.98560295866
np.mean(salary)
## 这是np的算法
60836.98560295866
salary.mean()
60836.98560295866
df.groupby('dep').an_s.mean().sort_values(ascending=False)
尝试默写这段代码时,也是状况百出。
- 错误记录: 1.sort_values()升降序的那个直接在括号中就是了,而我是sort_values()(ascending=False),用了两个括号。其实排序那个本来就是sort方法的参数
- 错误记录2.拼写错误ascending ,我拼写为asending,少了个c
- 个人理解:ascending这个,跟sql的语言类似
- 个人理解:先把dep分组,再然后计算不同组中的平均值。 这也跟sql里面的语言逻辑很相似,就是sql中两个排序依据的时候 。比如价格和名字,价格相同时,按顺序排列名字
dep
DoIT 73831.979381
BUILDINGS 72137.885057
FIRE 69383.989996
MAYOR'S OFFICE 68953.677083
WATER MGMT 64760.186526
COMMUNITY DEVELOPMENT 64262.597222
GENERAL SERVICES 63747.808026
TREASURER 63497.500000
POLICE 63127.904984
TRANSPORTATION 62947.504181
PROCUREMENT 61452.584416
HEALTH 61213.503521
CULTURAL AFFAIRS 61181.894737
DISABILITIES 58058.586207
BUSINESS AFFAIRS 57216.067797
HUMAN RESOURCES 57108.163934
LAW 55917.958242
AVIATION 55816.200479
SANITATION 55555.813576
FINANCE 54286.375235
ANIMAL CONTRL 47604.473684
PUBLIC LIBRARY 44241.731121
EMERGENCY MGMT 42845.754653
CITY COUNCIL 38046.547170
FAMILY & SUPPORT 31193.307371
Name: an_s, dtype: float64
中位数
len(salary)
#计算一共有多少个人领工资
30284
sa_s = salary.sort_values()
sa_s.head()
16629 3128
2247 3132
20961 3133
13423 3135
25422 3135
Name: an_s, dtype: int64
(sa_s.iloc[15142]+sa_s.iloc[15141])/2
中值
61836.0
salary.median()
61836.0
np.median(salary)
61836.0
plt.hist(salary,bins=30,rwidth=0.5)
plt.show()
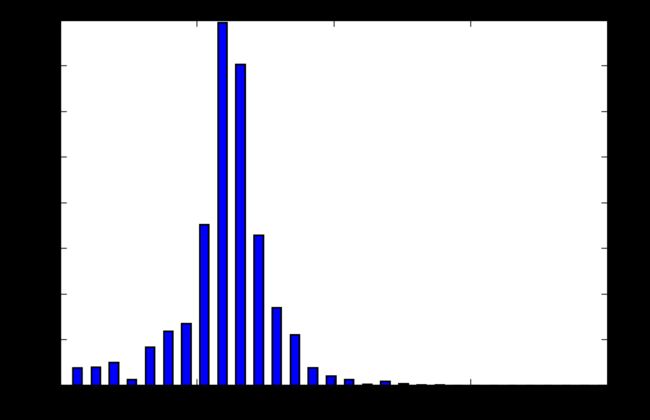
np.mean(salary)>np.median(salary)
均值是否大于中值呢 结论为否,那么就是均值小于中值,那么就是往左偏的
False
救火人员收入分布
f_s = df[df.dep=='FIRE'].an_s
plt.hist(f_s,bins=30,rwidth=0.6)
plt.show()
我的命名都是简写,正式场合还是不能这样么用,不然只有我自己看得懂
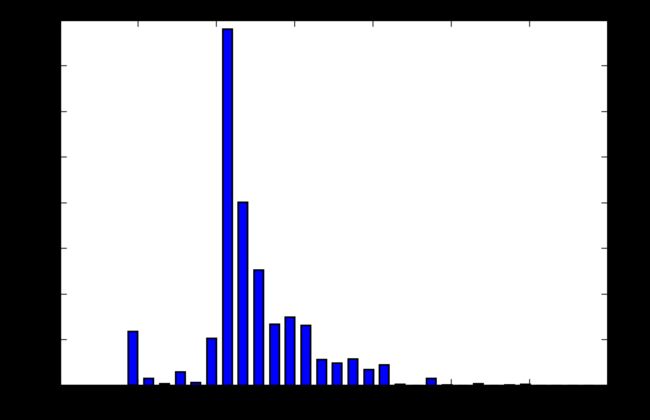
f_s.median()
66260.0
f_s.mean()
69383.9899958316
f_s.median()True
均值大于中值,所以图形偏右
离散程度
全距 range
salary.max()-salary.min()
笨办法算全距
198320
salary.range()
这是一次错误尝试,看看有没有直接算全距的方法,看来没有。
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
in ()
----> 1 salary.range()
F:\Program Files\conda\lib\site-packages\pandas\core\generic.py in __getattr__(self, name)
2670 if name in self._info_axis:
2671 return self[name]
-> 2672 return object.__getattribute__(self, name)
2673
2674 def __setattr__(self, name, value):
AttributeError: 'Series' object has no attribute 'range'
四分位距
Q1 = salary.quantile(0.25)
Q1
- 错误记录:拼写错误,quantile被我拼写为quartile了
55671.75
Q3 = salary.quantile(0.75)
Q3
68558.5
IQR=Q3-Q1
IQR
12886.75
salary.quantile(0.5) - salary.median()
中位数就是0.5分位数
0.0
salary.plot(kind='box',vert=False,figsize=(6,3))
个人理解:这种作图的思路是先把数据摆出来,再说是画图。 相当于是我有这一堆棉花,再说做成棉被;
但还有中思路,先说我要做棉被,你把棉花拿出来呢,比如plt.plot(salary)
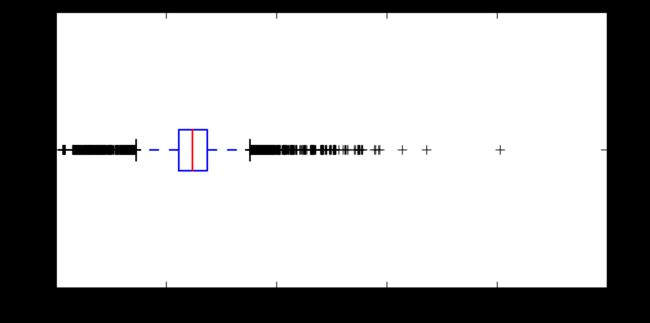
plt.boxplot(salary)
{'boxes': [],
'caps': [,
],
'fliers': [],
'means': [],
'medians': [],
'whiskers': [,
]}
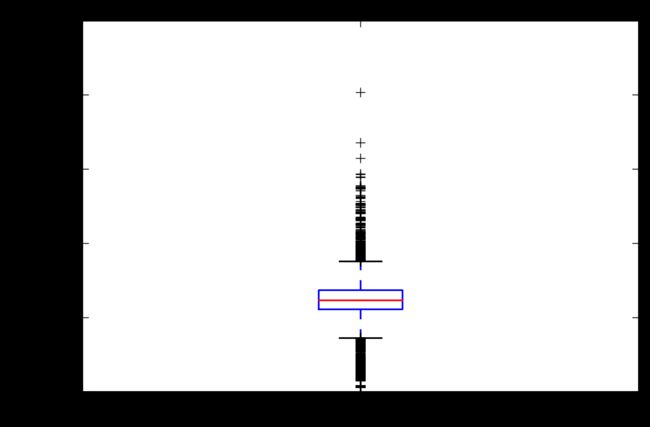
IT从业人员工资
it_s =df[df.dep=='DoIT'].an_s.tolist()
什么意思呢,是一个列表吗?
- 新增知识点,列表化。 把这些数字转化为列表格式
- 错误记录:拼写错误DoIT,我写成了DOIT。 全大写了
plt.boxplot(it_s)
疑问:这段如果不列表化,就读不出数据,这是为什么呢?
{'boxes': [],
'caps': [,
],
'fliers': [],
'means': [],
'medians': [],
'whiskers': [,
]}
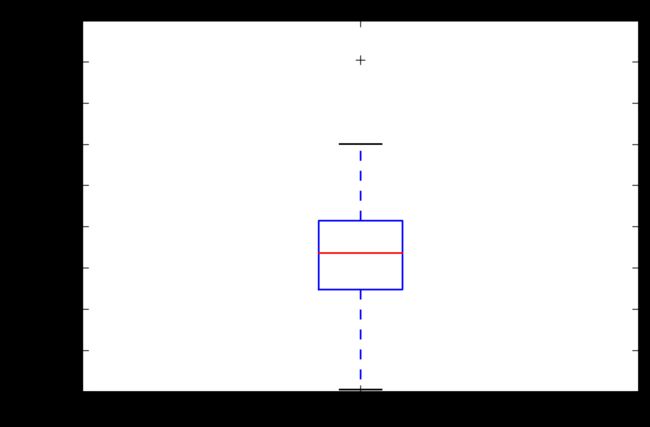
建筑行业和it行业的收入比较
还以同时画两类图
bld_s =df[df.dep=='BUILDINGS'].an_s
bld_s.head()
158 60255
395 75517
523 60633
608 66145
884 68463
Name: an_s, dtype: int64
plt.boxplot([it_s,bld_s],labels=["IT","BUILDING"])
{'boxes': [,
],
'caps': [,
,
,
],
'fliers': [,
],
'means': [],
'medians': [,
],
'whiskers': [,
,
,
]}
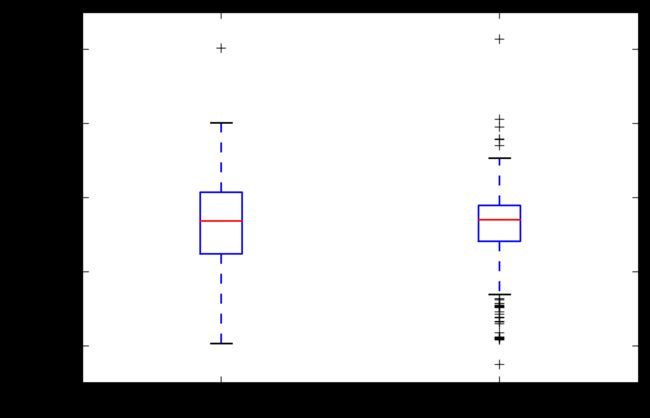
错误记录:
- 1.参数data部分应用【】括起来,因为这只是一个参数位置,如果用逗号分隔,会把第二个data放在另外一个参数位置上。
- 2.labels 参数应该放在括号内
-
- labels=["IT","BUILDING"]我也没有加方括号。,可是区分参数位置很重要的符号,不能乱用
所有部门雇员收入的box图
- 哈哈放大招啦,我喜欢这个
import seaborn as sns
sns.boxplot(data=df,x='dep',y='an_s')
plt.show()
## 意外发现用cmd安装真的好方便啊
# 不过太拥挤了,能不能设置大一点啊
我之前没有安装seaborn包。然后在cmd命令框里,输入conda install seaborn 发现太好用啦
疑惑:seaborn如何设置图形的大小呢?

mean = salary.mean()
var =np.sum((salary-mean)**2)/(len(salary)-1)
var
- 错误记录:sum((salary-mean)**2) 没有加外层括号,使得运算顺序出错。 可能是先相加,再平方去了。
271490393.4177519
std =np.sqrt(var)
std
- 错误记录:sqrt()不能直接用,是numpy的,所以要加上np。即np.sqrt(data)
16476.965540346071
#接下来是简单方法s
np.var(salary)
271481428.6048666
salary.var()
271490393.4177519
salary.std()
16476.96554034607
mean = salary.mean()
np.sum((salary - mean)**2) / (len(salary) - 1)
271490393.4177519
我发现两种算法的方差和标准差,是有误差的。
验证拇指规则
拇指规则是指68%集中在均值周围正负一个标准差的区间
- 大约有68% 的数据处在离均值一个标准差的范围内,
- 大约有95% 的数据处在离均值两个标准差的范围内。
len(salary[salary.between(mean - std, mean + std)])/len(salary)
- 错误记录
- between前面面要加点
- 方括号用错啦,应该是内部那个方括号应该是圆括号
0.7666094307224938
len(salary[salary.between(mean - 2*std, mean + 2*std)])/len(salary)
0.933364152687888
还真差不多呢。
两个变量的关系
协方差
$$ cov(x,y) = \frac{\sum(x_i - \bar{x})(y_i - \bar{y})}{N-1} $$
df.head()
score = df.re_s
score.tail()
30279 4.8
30280 4.9
30281 6.2
30282 6.7
30283 5.5
Name: re_s, dtype: float64
mean_s=np.mean(score)
np.sum((salary-mean)*(score-mean_s))/len(score)
- *总觉得这个思路和余玄定理很像。 就是用于计算新闻分类的余玄定理
7.747344090350171
以上求出来的是协方差。 是标准差的晋级版。 标准差是一个变量和均值之间的关系;协方差是两个变量之间的关系,不对呀,是两个变量和均值的关系,还是两个变量之间的关系呢?
cov = np.cov(salary,score)[0,1]
cov
7.7475999218100222
相关系数
$$ \rho = \frac{cov(x,y)}{\sigma_x \sigma_y} $$
- 其实就是用协方差除以标准差
corrcoef =cov/(np.std(salary)*np.std(score))
corrcoef
0.00045634837652977272
np.corrcoef(salary,score)[0,1]
0.00045633330757003586
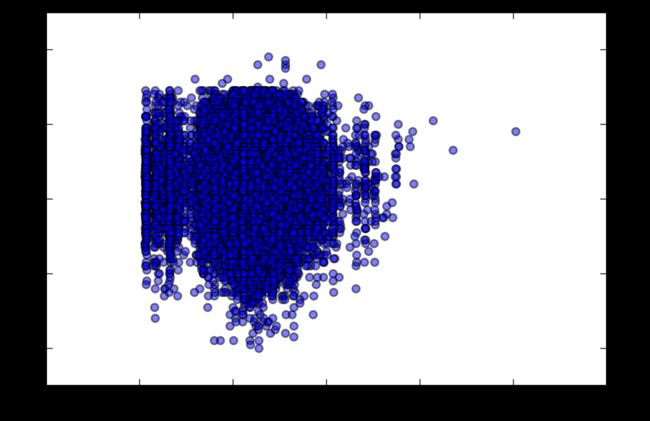
结果有点小误差。
plt.scatter(salary,score,alpha=0.5)
plt.show()
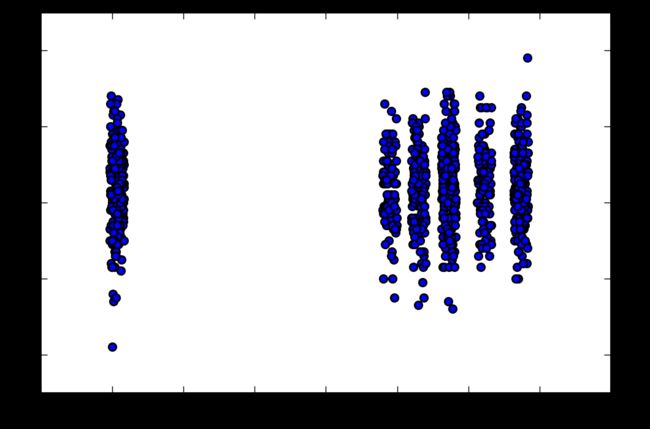
position = df[df.p_ti == 'FIREFIGHTER']
print(np.corrcoef(position.an_s, position.re_s)[1,0])
plt.scatter(position.an_s, position.re_s)
plt.show()
0.0571267765462
df.head()
第三课作业
1、计算 HRSalaries 数据中评分Review_Score 的均值和中位数,并判断其偏度是左偏还是右偏?
print(df.re_s.mean())
print(df.re_s.median())
df.re_s.median()6.4558908994849205
6.5
(array([ 25., 101., 560., 2480., 5199., 8858., 7821., 4088.,
1140., 12.]),
array([ 2. , 2.78, 3.56, 4.34, 5.12, 5.9 , 6.68, 7.46, 8.24,
9.02, 9.8 ]),
)
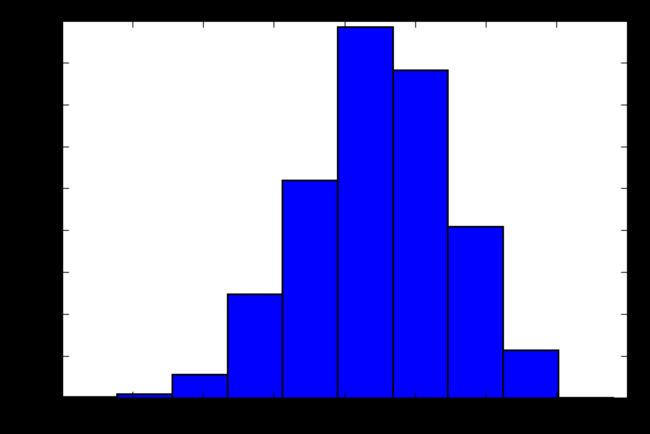
均值小于中值,是往左偏的
- 2、 Review_Score 的IQR是多少?并绘制该数据的box图。
print("Review_ScoreIQR:",df.re_s.quantile(0.75)-df.re_s.quantile(0.25))
Review_ScoreIQR: 1.4
df.re_s.plot(kind="box",vert=False,figsize=(9,6))
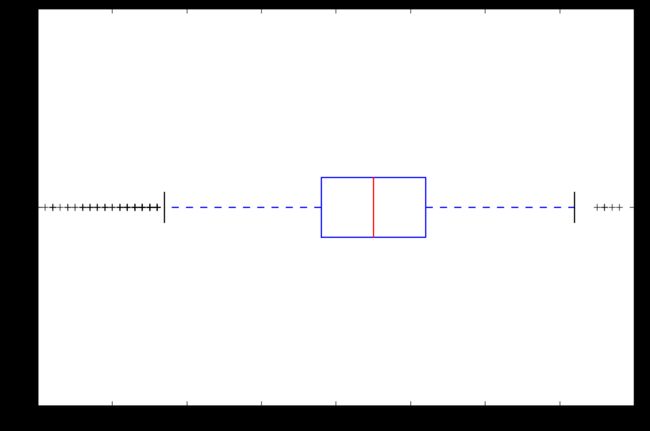
plt.boxplot(df.re_s)
{'boxes': [],
'caps': [,
],
'fliers': [],
'means': [],
'medians': [],
'whiskers': [,
]}
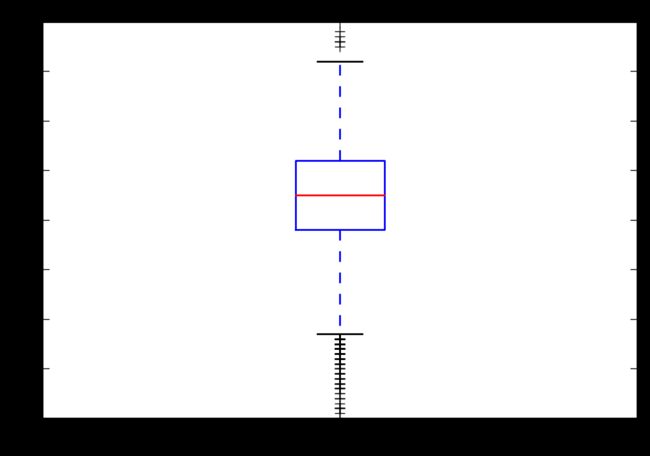
sns.boxplot(data=df.re_s)
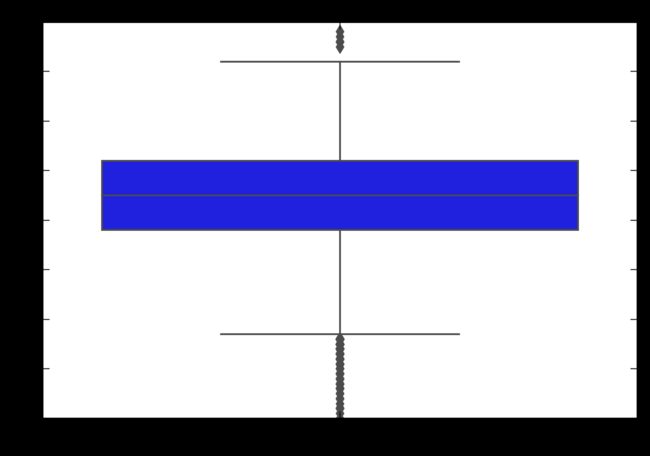
3、Review_Score的标准差是多少?
score.var()
1.0617336150160495
4、在Review_Score中,求落在两个标准差内的数据占总数的百分比。
mean_rs = score.mean()
var_rs=score.var()
#len(np.between[mean_rs-var_rs,mean_rs+var_rs])/len(score)
#错误记录:本应该是data.between,但我写成了np.between
len(score[score.between(mean_rs-var_rs,mean_rs+var_rs)])/len(score)
0.7091203275657113
5、对于 DoIT 部门,计算其收入和评分的相关系数。
it_s=df[df.dep=="DoIT"].an_s
print(it_s.head())
it_rs = df[df.dep=="DoIT"].re_s
print(it_rs.head())
708 64986
879 80746
1656 63777
1904 91184
2038 90967
Name: an_s, dtype: int64
708 5.5
879 6.3
1656 8.4
1904 7.4
2038 5.1
Name: re_s, dtype: float64
np.corrcoef(it_s,it_rs)[0,1]
0.0060245710104947512
plt.scatter(it_s,it_rs)
plt.show()
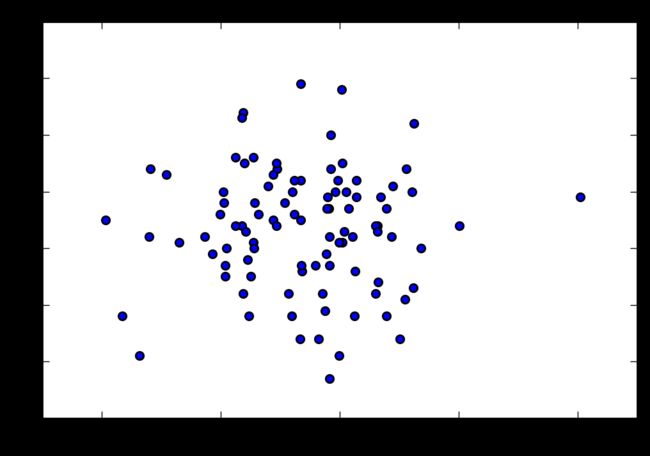
几乎看不到相关性