写在前面
SQL注入算是CTF,网站安全的一大部分,为了挖掘更骚的姿势,方便以后使用,小白特地温习了MySQL的文档,希望从里面寻找到更多的财富。
0x0 SELECT 语法
select语句,首先,看看select语句的用法,很多网站的注入点都是从select入手的:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
这是文档中select的用法,这是我们平时最常用的语句之一,很多在select_expr之前的东西,我们使用的很少,方括号中都是可选项。
这里明确的是,select的对象是select_expr,其他都是辅助的,为了获取特定的数据,我们就需要这些辅助,select_expr之前的我挑选几个比较常用的解释下:
第一个[ALL | DISTINCT | DISTINCTROW ],主要是我们需要的数据是以什么样的形式去显示,默认是 all,distinct和distinctrow是去除重复项显示结果,后两者不同的是,DISTINCTROW 省略基于整个重复记录的数据,而不只是基于重复字段的数据,distinct则是基于重复字段的数据。

接下来,主要是对select的优化,我们可以不去理会。
SQL_CALC_FOUND_ROWS则是能够在查询时为事先准备好符合where条件的记录数目,然后只要在随后执行一句
select FOUND_ROWS(); 就能获得总记录数。
然后,我们了解下select_expr之后的东西:
有很多我们都经常使用,比如什么from,where,order by之类的,这里,我想请大家注意下这些语句后面可以加的东西,表达式,操作符之类的。如果你注意到了文件操作,那也是很棒的,但是,能文件操作的SQL注入并不多,但是也是需要了解的。
接下来,我们寻找select的一些骚操作吧
0x1 select_expr别名
这个东西,非常重要!!!
很多人会忽略别名,其实,别名在select语句中是非常重要的一部分。
A select_expr can be given an alias using AS alias_name. The alias is used as the expression's column name and can be used in GROUP BY, ORDER BY, or HAVING clauses
这是官方文档中的话,select的表达式是可以被赋予别名,并用于group,order by,having之类的。
这里其实并不完全,被赋予别名的select表达式,在某种意义上就和正常的select表达式一样,是可以被select查询的,这就很骚了。
后面,我们会提到很多这个东西,这个别名的重要程度也会慢慢在你脑中提升,顺便提一下:
The AS keyword is optional when aliasing a select_expr with an identifier.
文档中的这句话表示,其实as是可以省略的:

这两句效果是一样的
现在,我们再玩玩这个别名,下面的子查询会解释为什么可以这么玩:

可以看到,这里列名变成了1,而不是先前的那样,那么,如果我们用在数据库中呢?

也就是说,这里就是正常显示了我们别名要查的内容,那么,我们能不能骚点呢?比如换换列名?

对,你没有看错,这个玩意是可以玩union的,下文会讲为什么,回到上文,别名在某种意义上就是表达式。那么我们可以这样玩:

也就是说,我们可以知道列名而查到单独的列,在有的网站,只显示某一特殊列,你又不知道列名时,这个就比较厉害了。
别名先玩到这里
0x2 UNION
union是将多select_expr的查询结果返回出来。也就是说,union查询的对象是select_expr,栗子:

在这样的效果下,我们的两个select_expr就出来了,但是,值得注意的是,尽管是联合查询,两个select_expr的column数量必须是匹配的,而且column的名称是以第一个select_expr为标准的,所以,我们可以回顾下,上面的那个不用column名而去查询的语句,这里就可以解释,为什么我们使用union可以返回的column名是1和2了。
了解了这些原理,我们就可以知道,所有我们讲的select_expr都是可以在union里适用的,于是,这里有很多能发挥的地方。现在,union先说到这里。
0x3 JOIN
这个join的语法不是和union一样基于一种简单的select_expr的拼接,这里我专门贴出join的用法:
table_references:
table_reference [, table_reference] …
table_reference:
table_factor
| join_table
table_factor:
tbl_name [[AS] alias]
[{USE|IGNORE|FORCE} INDEX (key_list)]
| ( table_references )
| { OJ table_reference LEFT OUTER JOIN table_reference
ON conditional_expr }
join_table:
table_reference [INNER | CROSS] JOIN table_factor [join_condition]
| table_reference STRAIGHT_JOIN table_factor
| table_reference STRAIGHT_JOIN table_factor ON condition
| table_reference LEFT [OUTER] JOIN table_reference join_condition
| table_reference NATURAL [LEFT [OUTER]] JOIN table_factor
| table_reference RIGHT [OUTER] JOIN table_reference join_condition
| table_reference NATURAL [RIGHT [OUTER]] JOIN table_factor
join_condition:
ON conditional_expr
| USING (column_list)
这些就是join的语法,join用于select的table_references部分。当然,join还可以用于多表delete和update。上面也提到了,join的对象是table,于是,join主要操作的是table,但是,我们也可以回想上面说过的别名,别名在一定程度上是可以代替table的,于是,这个join的语法就有了够有意思的用法。
上面的语法也许是不太直观,我们来示例几种常见的用法:
首先,列下来:
SELECT * FROM table1 JOIN table2
SELECT * FROM table1 JOIN table2 ON table1.id=table2.id;
SELECT * FROM table1 JOIN table2 USING (id);
个人认为,这是比较常用的三种,其实,本人认为这样的总结并不好,因为,我认为,每个语法都是有一个主要的框架,这这个语法中,有我们必须提供的,其他的都是为修饰框架和优化框架,迎合用户所用的装饰。所以,其实,很多用法正是我们阅读上面一大堆的官方用法而得到的。当然,我还是列出了我常用的用法。
第一种,就是我所说的框架的主干了:

这就是效果了,为什么有这么多重复的呢,当然是为了匹配啊,这里我们也可以看出join的用法,是一个table和另一table的值逐一匹配然后显示出来。看到结果,其实你都能大概猜出他的运行原理了。。。。。。。
所以也就有了我们的第二句,这个on就是限制条件的情况。考虑到join的特点,其实,我们是在跨表查询特定的数据用到的,当然,这就会有条件。比如,我的两个表都有学号这个column,一个表存放成绩,一个表存放姓名。为了获取某一特定学号的学生的姓名和成绩,我们就可以使用的join用on来限制学号相同,这样的话,我们的数据库分类更整齐,而且还能得到我们需要的效果。
简单示例下:

这样就得到了想要实现的效果。
最后一种,我们可以注意到上面的join语句都是只能显示table里的所有column,这样有时候不是很方便,于是,using的用法就比较有用了。但是这里的using主要是面对table2的,举个栗子:
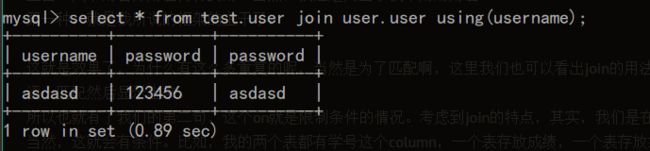
这里再来看看,整个的显示就是一行,注意一下,会发现,这里的username是两个表共有的而password则是与之匹配的table1和table2中的password。也就是查询的其实并不是username,而是用username去分别查两个表,只有都能查到才会写到结果中
所以,我就瞎* 总结了下,join其实是把多表逐个匹配,合成一个大的table_references,然后,在这里面以一定的条件而查询的。
这里有个比较有意思的地方,join两个一样的表是会报错的:

但是,如果是join别名的时候,join是不会检查内容的,于是,你想查询两个一样的表可以这么写:

当然,using和on都是可以在这个条件下用的,于是,你可以试试这个:

可能会有人不解,但是,下面的可是干货哦,这样有什么用呢?
我们就必须讲到报错了,如果一个表里出现两个名字一样的column会怎么样呢?如果你查询时,程序会告诉你表里有重复的column名,关键是报错时,为了让你更好的纠错,他会打印重复的column名,结合上面的例子,再想想,别名时可以作为类似table被查询的,那么如果你在不知道表中列名的情况下,而且在有报错的情况下,就可以这么玩了:
仔细观察我们使用的语句,我们其实并不知道表中还有password的column。
结合:

如此一来,我们就可以在有报错的情况下,得到column的字符串。
0x04 子查询
子查询是指另一个语句中的一个SELECT语句
A subquery is a SELECT statement within another statement
关于子查询,我有一些自己的理解,select得到的结果其实和table的结构很类似,select查询本身就是在table和select_expr中进行,那么,只要是结果是这两者的,我们都可以使用select去查询,于是就有上面的很多骚操作。
回归主题,我们继续来看看子查询,子查询可以存在于很多地方,我们其实也很常见到这个,盲注时,我们往往就是在原有的语句里插入另一个select语句,我们需要的只是个别结果,很多盲注,我们需要的就是个table中的字符串。那么,我们来了解下,官方如何搞这个subqurey
There are few restrictions on the type of statements in which subqueries can be used. A subquery can
contain many of the keywords or clauses that an ordinary SELECT can contain: DISTINCT, GROUP BY,
ORDER BY, LIMIT, joins, index hints, UNION constructs, comments, functions, and so on
很多语句(虽然原文是few,但是,我就这么写233333)都可以使用子查询。对这些语句的类型基本没有限定。子查询可以包括普通SELECT可以包括的任何关键词或子句: DISTINCT, GROUP BY, ORDER BY, LIMIT, 联合, 索引提示, UNION结构化, 评注和函数等。我想说,这个子查询范围很广,广到什么程度呢,如果,你能明白框架中添加修饰那个原理,你就会明白,只要是操作对象是字符串,table一类的,都是可以的。
其实,我们之前已经举过很多栗子了,再举两个:


就是这么熟悉,其实我们已经使用很多次了,也呼应了上文的别名用法,在from后面的子查询,是必须使用别名的。
其实,我们注入时更多是使用和操作符结合的子查询:

这样的语句大概已经习惯了。值得一提的是,我们可以多组比较,如下,我们可以在一定条件下得到column的个数

0x05 未完待续
其实select的语法是和很多语句拼凑在一起的,MySQL包括其他数据库,都不可能通过select这个小点而得到select全部用法,select是框架,具体还是要我们自己去修饰这个框架