最近需要在Windows上配置python 开发 Spark应用,在此做一个总结笔记。
Spark 简介
Spark的介绍及运行环境要求,引自 Spark 官方文档
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark runs on both Windows and UNIX-like systems (e.g. Linux, Mac OS). It’s easy to run locally on one machine — all you need is to have java installed on your systemPATH, or the JAVA_HOME environment variable pointing to a Java installation.
Spark runs on Java 7+, Python 2.6+/3.4+ and R 3.1+. For the Scala API, Spark 2.1.0 uses Scala 2.11. You will need to use a compatible Scala version (2.11.x).
下载Spark
从官方网站下载tar包 http://spark.apache.org/downloads.html
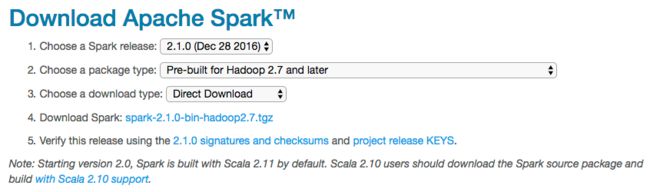
Spark 由 Scala语言开发,而Scala也是运行于JVM之上,因此也可以看作是跨平台的,所以在下载 spark-2.1.0-bin-hadoop2.7.tgz 之后, 在Windows 平台直接解压即可。
在Spark 的 sbin 目录下,并没有提供Spark作为 Master 启动脚本,所以在windows下,我们借助spark-shell, pyspark等方式启动并调用Spark。
配置环境变量
假设 spark-2.1.0-bin-hadoop2.7.tgz 已被解压至E:\Spark, 接下来需要配置环境变量。 对于python开发来说,有三个环境变量至关重要。 开始-> 计算机, 右键点击 -> 属性->高级系统设置->环境变量,在系统环境变量中添加环境变量 SPARK_HOME和PYTHONPATH,并将Spark\bin加入到系统Path变量中。
SPARK_HOME=E:\Spark
Path=%SPARK_HOME%\bin;%Path%
PYTHONPATH=%SPARK_HOME%\Python;%SPARK_HOME%\Python\lib\py4j-0.10.4-src.zip
切记,如果在windows下已经通过cmd打开命令窗口,则需要退出命令窗口再重新打开,以上设置的环境变量才会生效。
Python Spark入门示例
在Spark的安装包,提供了经典的入门示例程序,通过这些示例程序演示了基本的Spark开发和API调用过程。
1. Word Count
统计文本中某一单词的重复次数,是在技术面试中,特别是考察编程能力经常遇到的面试题,网络中也有各种语言的解题代码。在Spark的示例中,通过非常精悍的代码展示了Spark的强大。
from __future__ import print_function
import sys
from operator import add
# SparkSession:是一个对Spark的编程入口,取代了原本的SQLContext与HiveContext,方便调用Dataset和DataFrame API
# SparkSession可用于创建DataFrame,将DataFrame注册为表,在表上执行SQL,缓存表和读取parquet文件。
from pyspark.sql import SparkSession
if __name__ == "__main__":
# Python 常用的简单参数传入
if len(sys.argv) != 2:
print("Usage: wordcount ", file=sys.stderr)
exit(-1)
# appName 为 Spark 应用设定一个应用名,改名会显示在 Spark Web UI 上
# 假如SparkSession 已经存在就取得已存在的SparkSession,否则创建一个新的。
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
# 读取传入的文件内容,并写入一个新的RDD实例lines中,此条语句所做工作有些多,不适合初学者,可以截成两条语句以便理解。
# map是一种转换函数,将原来RDD的每个数据项通过map中的用户自定义函数f映射转变为一个新的元素。原始RDD中的数据项与新RDD中的数据项是一一对应的关系。
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0])
# flatMap与map类似,但每个元素输入项都可以被映射到0个或多个的输出项,最终将结果”扁平化“后输出
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
# collect() 在驱动程序中将数据集的所有元素作为数组返回。 这在返回足够小的数据子集的过滤器或其他操作之后通常是有用的。由于collect 是将整个RDD汇聚到一台机子上,所以通常需要预估返回数据集的大小以免溢出。
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
spark.stop()
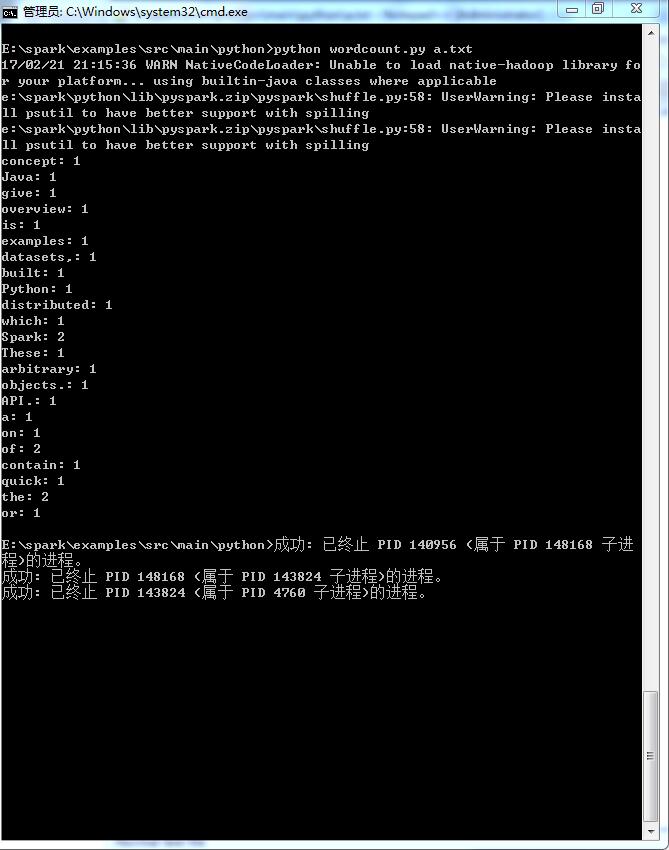
测试数据, 可以拷贝下面的文字存入一个文本文件,比如a.txt
These examples give a quick overview of the Spark API. Spark is built on the concept of distributed datasets, which contain arbitrary Java or Python objects.
执行测试结果
概念介绍
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作
RDD有两种操作算子:
- Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作
- Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
常见执行错误
初次执行Python Spark可能会遇到类似错误提示
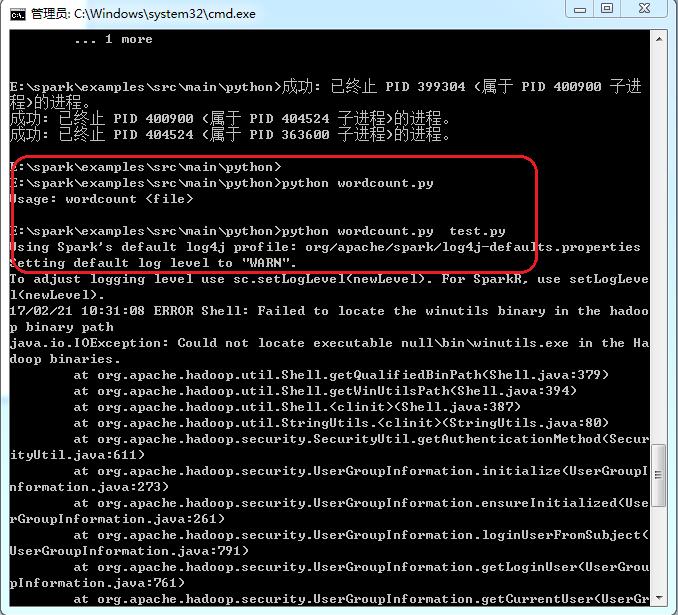
之所以有上面提示的内容,主要包含两部分配置问题
1. 日志输出
Spark在执行过程中,很多INFO日志消息都会打印到屏幕,方便执行者获得更多的内部细节。开发者可以根据需要设置$SPARK_HOME/conf下的log4j。在 $SPARK_HOME/conf 下 已经预先存放了一份模版log4j.properties.template文件,开发者可以拷贝出一份 log4j.properties, 并设置成WARN
将log4j.properties.template 中的 INFO
# Set everything to be logged to the console
log4j.rootCategory=INFO, console
修改为 WARN, 存入log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
2. Could not locate executable null\bin\winutils.exe
首先,下载 winutils.exe,并保存至 c:\hadoop\bin
https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
其次,设置HADOOP_HOME环境变量,指向 c:\hadoop, 并将HADOOP_HOME加到系统变量PATH中
set HADOOP_HOME=c:\hadoop
set PATH=%HADOOP_HOME%\bin;%PATH%
参考:
https://spark.apache.org/docs/preview/api/python/pyspark.sql.html
https://spark.apache.org/docs/latest/programming-guide.html#transformations
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-tips-and-tricks-running-spark-windows.html