基于javascript用olamisdk实现web端语音识别语义理解(speex压缩)
转载请注明原文地址:http://blog.csdn.net/ls0609/article/details/73920229
olami开放平台sdk除了支持语音识别功能外,更强大的在于支持语义理解功能,在Android平台和iOS平台都有示例demo供大家下载。
语音在线听书demo:http://blog.csdn.net/ls0609/article/details/71519203
语音记账demo:http://blog.csdn.net/ls0609/article/details/72765789
在web端,基于JavaScript用olami开放平台sdk也可以实现语音识别语义理解。本文就实现了这样一个小程序,web客户端本地用麦克风录音,录音的数据用speex压缩,然后跨域向服务器发送请求,返回识别的语音和语义字符串并显示。
先上图:
如下图刚载入的时候,未录音前界面
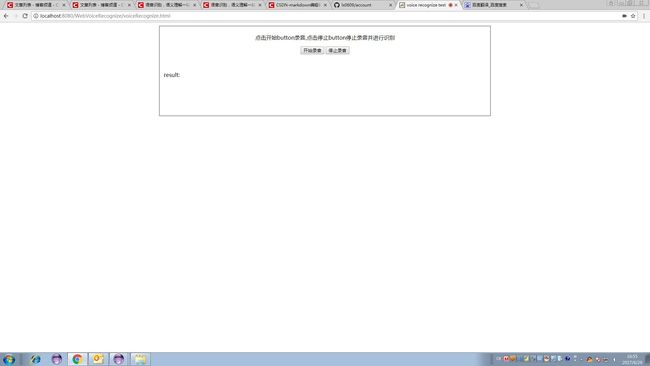
点击开始录音button后

一句话说完自动检测尾音结束标志然后压缩上传给服务器进行识别

将从服务器获取的识别结果显示到界面上
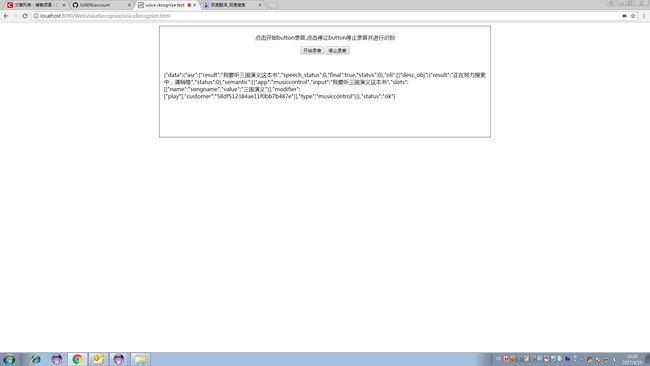
本例中说的语音是:“我要听三国演义这本书”,用的是android平台听书app建立的语法。
返回的json字串如下:
{
“data”: {
“asr”: {
“result”:“我要听三国演义这本书”,
“speech_status”: 0,
“final”: true,
“status”: 0
},
“nli”: [
{
“desc_obj”: {
“result”:“正在努力搜索中,请稍等”,
“status”: 0
},
“semantic”: [
{
“app”: “musiccontrol”,
“input”:“我要听三国演义这本书”,
“slots”: [
{
“name”:“songname”,
“value”:“三国演义”
}
],
“modifier”: [
“play”
],
“customer”: “58df512384ae11f0bb7b487e”
}
],
“type”: “musiccontrol”
}
]
},
“status”: “ok”
}
通过解析这段json,可以得到app类型,songname(用于查询书名),modifier是play表示行为是播放。
这段json的语法当然是用户自定义的,获得了json字串就可以解析得到程序需要的字段用于对应的操作,从而实现了语义理解功能。olami开放平台语法编写介绍http://blog.csdn.net/ls0609/article/details/71624340
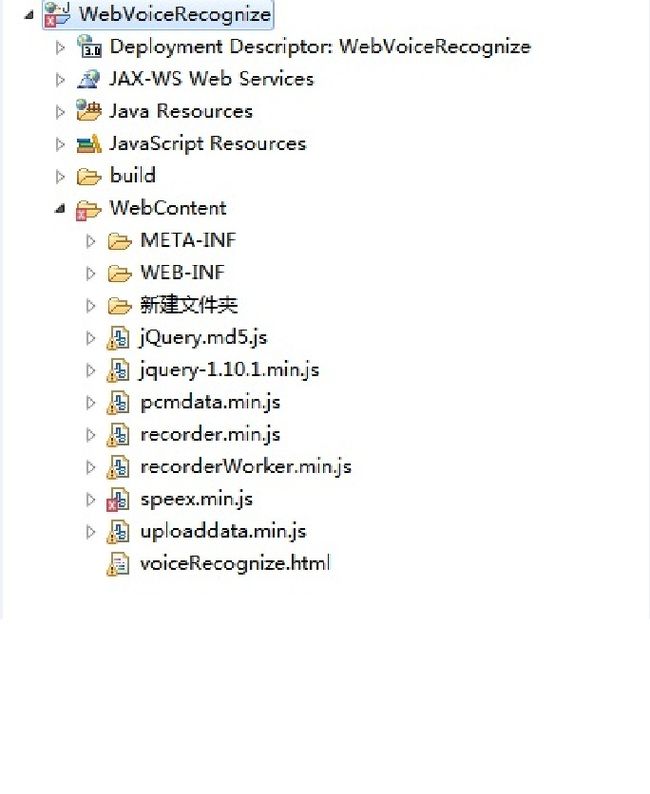
下面来看看实现的code,用eclipse建立J2EE工程WebVoiceRecognize
初次搭建可以参考如下网站:
http://jingyan.baidu.com/article/1709ad808caf9d4634c4f0f8.html
下面是建立的工程目录结构,发布后,网页打开运行在chrome或者QQ浏览器均可。
下面讲述下voiceRecognize.html这个文件,其他都是min.js,只需知道如何调用就可以了。
HTML>
voice recognize test
"load()">
点击开始button录音,点击停止button停止录音并进行识别
result:
window.AudioContext =window.AudioContext || window.webkitAudioContext;
varaudioContext =newAudioContext();
varaudioInput =null,
realAudioInput =null,
inputPoint =null,
audioRecorder =null;
varrafID =null;
varanalyserContext =null;
varrecIndex =0;
varrecording =false;
varbRecorded =false;
functionload(){
initAudio();//初始化recorder
setAuthorization("http://cn.olami.ai/cloudservice/api","51a4bb56ba954655a4fc834bfdc46af1","asr","68bff251789b426896e70e888f919a6d","nli");
setCallBackFromServerResult(getResultFromServer);
}
functioninitAudio(){
if(!navigator.getUserMedia)
navigator.getUserMedia =navigator.webkitGetUserMedia || navigator.mozGetUserMedia;
if(!navigator.cancelAnimationFrame)
navigator.cancelAnimationFrame = navigator.webkitCancelAnimationFrame ||navigator.mozCancelAnimationFrame;
if(!navigator.requestAnimationFrame)
navigator.requestAnimationFrame = navigator.webkitRequestAnimationFrame|| navigator.mozRequestAnimationFrame;
navigator.getUserMedia({audio:true}, gotStream,function(e){
alert('Error getting
audio');
console.log(e);
});
}
functiongotStream(stream){
inputPoint = audioContext.createGain();
// Create an AudioNode from the stream.
realAudioInput =audioContext.createMediaStreamSource(stream);
audioInput = realAudioInput;
audioInput.connect(inputPoint);
audioRecorder =newRecorder(inputPoint );
}
functionStartRecording()
{
// start recording
if(audioRecorder ==null)
{
initAudio();
alert("need initialize media");
}
audioRecorder.clear();
audioRecorder.record();
recording =true;
bRecorded =false;
ToggleLabels();
RegisterCallBackToRecorder();
}
functionStopRecording()
{
audioRecorder.stop();
audioRecorder.getBuffers(gotBuffers );
}
functionRegisterCallBackToRecorder()
{//检测语音结束后回调
audioRecorder.setCallBack(speexEncode);
}
functionToggleLabels()
{
if(recording)
{
document .getElementById("recordbutton").value ="录音中ֹ";
document .getElementById("speexEncodebutton").value ="停止录音";
varbtn = document .getElementById("recordbutton").value;
}else{
document .getElementById("speexEncodebutton").value ="识别中";
document .getElementById("recordbutton").value ="停止录音ֹ";
}
}
window.record =function(e)
{
if(!recording)
{
StartRecording();
recording =true;
bRecorded =false;
}
else
{
StopRecording();
recording =false;
bRecorded =true;
}
ToggleLabels();
};
window.speexEncode =function()
{
exportSpeex();
};
functionexportSpeex()
{
recording =false;
bRecorded =true;
ToggleLabels();
audioRecorder.stop();
audioRecorder.exportPCM(uploadSpeexData);
}
functiongetResultFromServer()
{
document .getElementById('result').innerText =JSON.stringify(result);
document .getElementById("speexEncodebutton").value ="停止录音";
document .getElementById("recordbutton").value ="开始录音ֹ"
}
浏览器载入的时候,先调用load()进行初始化
functionload(){
setAuthorization(
"http://cn.olami.ai/cloudservice/api",//serverurl
"51a4bb56ba954655a4fc834bfdc46af1",//appkey
"asr",//api类型
"68bff251789b426896e70e888f919a6d",//appSecret
"nli");//seq
setCallBackFromServerResult(getResultFromServer);
}
initAudio()中初始化了recorder用于获取麦克风资源做录音使用。
setAuthorization函数,参数分别是
url服务器地址
appkey开放平台注册应用后获得的appkey
api api类型选asr为语音
appSecret开放平台注册应用后获得的appSecret
nli为seq表示包含语音语义返回,为stt表示只有语音返回
setCallBackFromServerResult(getResultFromServer)注册录音介绍并且识别出结果后的回调,在回调函数中可以把结果输出到界面上。
当点击开始录音button后,调用
functionStartRecording()
{
// start recording
if(audioRecorder ==null)
{
initAudio();
alert("need initialize media");
}
audioRecorder.clear();
audioRecorder.record();
recording =true;
bRecorded =false;
ToggleLabels();
RegisterCallBackToRecorder();//注册recoder回调
}
当在录音的js代码中,会自动检测尾音结束,然后回调注册的函数speexEncode (),点击停止录音button一样调用这个函数
window.speexEncode=function()
{
exportSpeex();
};
functionexportSpeex()
{
recording =false;
bRecorded =true;
ToggleLabels();//更新界面的button状态
audioRecorder.stop();
audioRecorder.exportPCM(uploadSpeexData);
}
audioRecorder.exportPCM(uploadSpeexData)实现了将录好的16Kpcm语音压缩成speex格式并上传到服务器,从服务器取得结果后调用注册的setCallBackFromServerResult(getResultFromServer)函数,然后再函数getResultFromServer中进行结果的输出显示。
代码下载地址:
用olamisdk实现web端语音识别语音理解
相关网站链接:
olami开放平台语法官方介绍:https://cn.olami.ai/wiki/?mp=nli&content=nli2.html
olami开放平台语法编写简介:http://blog.csdn.net/ls0609/article/details/71624340