
记得前一段时间,群里的小伙伴询问我最好用的词典APP。今天我们不说词典,我们说一个比词典还要牛逼的东西,那就是语料库,英文是corpus。其实在大多数情况下,我们手中的词典,无论是Oxford、Langman or Macmillan等等,已经完全可以帮助我们解决日常英文阅读中所遇到的问题了。但是如果我们手中再多一件利器,会给我们的英文学习带来诸多方便。
那么什么是语料库呢?我们强大的“度娘”给出答案。
语料库是指经科学取样和加工的大规模电子文本库。借助计算机分析工具,研究者可开展相关的语言理论及应用研究。
再来看一下英文介绍。
corpus n. (pl. corpora) refers to a large collection of well-sampled and processed electronic texts, on which language studies, theoretical or applied, can be conducted with the aid of computer tools.
也许你会告诉我,这是什么鬼,看不懂呀。别急,通俗的讲,语料库就是一个海量的语言集。它包罗万象,无所不有,涵盖众多表达,无论书面语亦或是口头语,可谓无比丰富,取材来自电视广播、报纸杂志、学术期刊、小说电影等等,全部是真实语料。
也许你正在为你的中式英语而着急:我说的英语只有中国人可以听懂呀,老外听了都是懵逼状态......

所以学习英语时,真实的场景就显得尤为重要。我们就来看看这个强大的语料库,如果好好利用,分分钟钟带你装逼带你飞。
今天我们只看第一种在线语料库,那就是美国当代英语语料库(全称 Corpus of Contemporary American English),简称COCA。以下是来自Wikipedia的介绍。
The freely searchable 450-million-word Corpus of Contemporary American English( COCA) is the largest corpus of American English currently available, and the only publicly available corpus of American English to contain a wide array of texts from a number of genres. It was created by Mark Davies, Professor of Corpus Linguistics at Brigham Young University.
好了,我们先看一下COCA的整体页面布局,最上面是语料库名称,然后下面有4个分栏,分别是SEARCH 检索、FREQUENCY 频次、CONTEXT 文本、 ACCOUNT 账户。

我们最常用的功能就是第一个: SEARCH,也就是语料库检索主界面。请看下图。

List 检索结果列表显示
Chart 检索结果柱形图显示
Collocates 搭配,找出频繁搭配使用的词汇
Compare 比较,辨析同义词
KWIC(keyword in context) 文中关键词显示
Find matching strings查找
Reset 重置
[POS] 词性标注,点开之后就会出现如下页面。
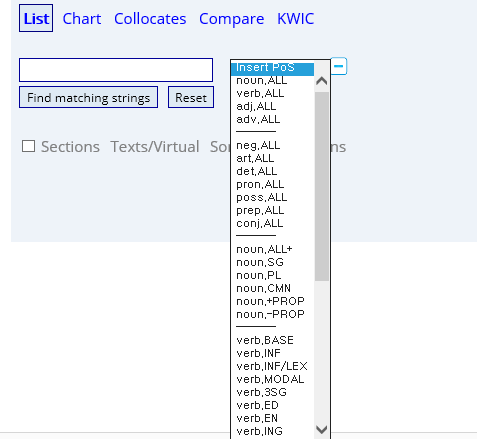
其实一开始在看到[POS]时,我也不知道什么意思,我就点开,然后出现词性选择诸多项,才知道POS = Part of Speech(词性),不禁觉得自己文化低,想要回农村的赶脚~
下面我们就看看如何使用COCA吧~
1. 频次
比如我们搜索“reading”这个单词,检索结果列表list显示,我们可以看到在语料库中这个单词出现的频次FREQUENCY是86070次。

点击显示的”reading“,我们进入文本CONTEXT页面,从左到右依次是序号、年份、文本类型(下面我会说到5大文本类型,这里是ACAD,是指academy学术期刊)、文本来源(来自某某学术机构、媒体广播等等)。后面是具体的文本,如果想查看完整文本,点击文本来源,就自动跳转到CONTEXT+页面。

同时,我们检索结果用柱状图chart显示
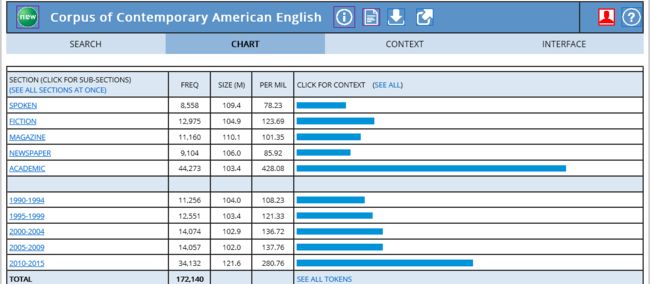
注意左边一栏的内容,也就是section文本分类,从上至下依次为spoken媒体对话、fiction小说、magazine杂志、newspaper报纸、academic学术期刊,然后下面就是时间年限分类。
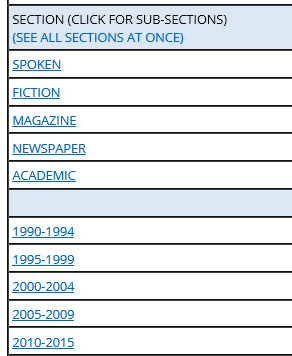
我先点开“spoken",大家看一下页面,来源有 ABC、NBC、CBS、CNN等多家媒体电视广播等。
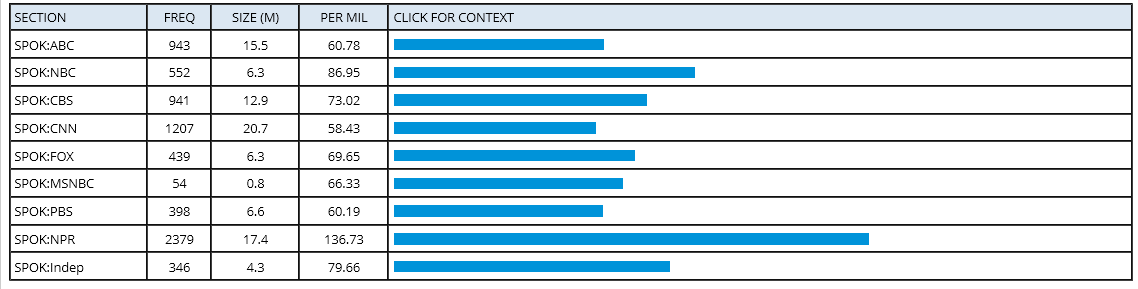
然后我再点开"1990-1994"时间段

如果我们要比较两组近义词或近义词组的使用频次,除了可以分别检索之外,还可以直接输入”think/figure“,这样更一目了然。

2. 搭配
也就是Collocates选项,如下图所示。

上面一行是需要检索的单词或短语,下面一行是搭配。
(1)譬如我需要检索的单词是”gain“,需要搭配的单词是”success“,一切默认,结果如下图所示。
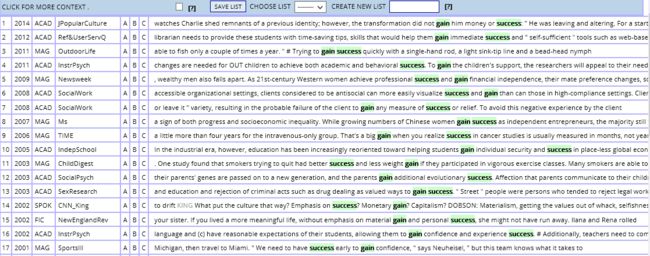
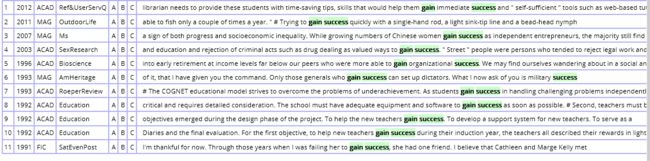
对了,你们注意到上面的绿色数字了吗?43210 01234,这具体是什么含义呢?其实通过刚才检索的结果你也能猜上一二,那就是搭配词"success"出现在检索词”gain“左边或右边4个字节内。如果我们只想让搭配词“success”出现在检索词右边,并且限制在2个字节内,那么我们可以设置为:左0,右2,结果如下图所示。

如果我们要在gain 与success 之间加一个成分呢,这时检索词后面的[POS]派上用场,如果我们想要在两者之中添加一个形容词,我们选择adj.,看下图所示。
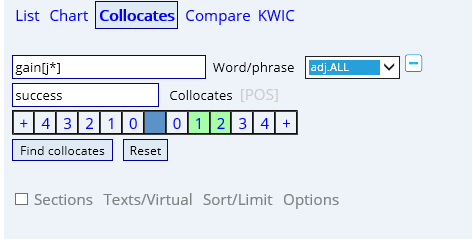
注意:这里的gain与[adj.] 之间一定要有空格,否则会有错误显示。其实你这样检索的就是gain+adj.+success的结果,同时我限制字节是左0右2。

(2)如果你不知道gain这个单词和什么词搭配比较好,譬如gain和哪个名词n.搭配比较常见,那么可以这样检索。

结果显示如下
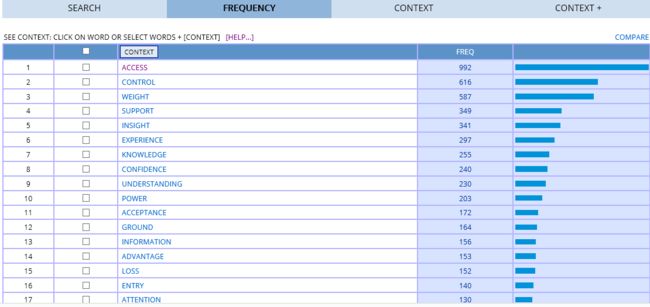
我们会看到可以和gain 搭配的名词频次从高到低有access, control,weight,support等等,如果想查看某一搭配,直接点击想要查看的搭配即可。
当然你也可以直接在list页面这样检索:gain 空格 选择[POS]中的名词格式,如下图,这样检索出来的结果和(2)是一样的。
(3)如果我们要检索某一词不与某一词搭配的情况,这时要用到减号“-”,也就是在搭配词前加上“-”, 意思是检索词不与该搭配词搭配的情况。譬如我们在list页面输入“gain-success”,所要检索的结果便是检索词gain不与success搭配而与任何一个其他的词搭配。
突然发现这个功能好强大,写作文时可以派上用场了。如果你不清楚这样的表达是否合适亦或是这样搭配的使用情况如何以及如何搭配才更恰当,不妨试试这个功能。注意:如果像(1)这样的已知搭配出现的频次是0或者很少,我们就知道这样的搭配也许native speaker 并不这样说,也就是说是不地道的表达。
3. 近义词及近义词搭配
了解了以上功能之后,我们下面的介绍就相当简单了,我就不一一截图了。
如果我们想知道brilliant的近义词,在search页面,默认list显示,输入“[=brilliant]", 检索即可。同样如果我们想知道“brilliant idea"的近义搭配,除了brilliant之外,还有哪个brilliant的近义词可以和idea搭配,这时我们可以到search页面,选择collocates选项,第一行输入idea,第二行输入[=brilliant], 左1,右0.
4. [POS] 限定词性
前面我们说到,检索一个单词gain搭配的两种方法,其中一种就是在list页面,输入 gain 然后空格 选择[POS]中词性,譬如名词的话,即“gain [nn*]”,那就是检索:gain和任意名词的搭配情况 。
如果我们想知道gain作为名词本身的使用情况呢?这时就可以在list页面,在gain和名词词性之间加一个英文状态的句号“.” 即“gain.[nn*]”,注意引号内没有空格,这就是检索gain作为名词本身在语料库中的情况。
5. Lemma检索
Lemma检索指的是查找检索词的所有变化形式,检索方式是在检索词外加“[]”。这种方式适合查找名词单复数变化,动词时态变化。比如be动词检索,我们可以这样输入“[be]”, 我们得到的结果就是“am,is,are,was,were,being,been”的情况。
6. 模糊检索
这里要提到通配符“*” 和“?”。“*” 代表的是任意数量的字符,包括数量为0,也包括空格和标点。“?”代表的是任意一个字符。注意两者的作用是一样的,只是“?”检索的更精确一些。
比如我们要检索任意以“ed”结尾的词,只需要输入“*ed”就行,如果要查找任意以ed结尾的形容词,我们可以这样检索:“*ed[j*]”, 注意后面的词性一定要点击[POS]来选择。
好了,介绍完了,以上就是我所知道的COCA语料库的功能,如果你觉得有用,赶紧收藏。
