引言
Java 网络爬虫具有很好的扩展性可伸缩性,其是目前搜索引擎开发的重要组成部分。例如,著名的网络爬虫工具 Nutch 便是采用 Java 开发,该工具以 Apache Hadoop 数据结构为依托,提供了良好的批处理支持。
Java 网络爬虫涉及到 Java 的很多知识。本篇中将会介绍网络爬虫中需要了解的 Java 知识以及这些知识主要用于网络爬虫的哪一部分,具体包括以下内容:
小编整理了一些java进阶学习资料和面试题,需要资料的请加JAVA高阶学习Q群:664389243 这是小编创建的java高阶学习交流群,加群一起交流学习深造。群里也有小编整理的2019年最新最全的java高阶学习资料!
Maven 的使用;
log4j 的使用;
对象的创建;
集合的使用;
正则表达式的使用;
HTTP 状态码;
其他。
Maven 的使用
Maven 是什么
Maven 是由 Apache 软件基金会所提供一款工具,用于项目管理及自动构建。我们知道在构建一个 Java 工程时,需要使用到很多 Jar 包,例如操作数据库需要使用到 mysql-connector-java 以及其相关依赖的 Jar 包。而 Maven 工具便可以很方便的对我们在项目中使用到的开源 Jar 包,进行很好的管理,比如下载某 Java 工程需要的 Jar 包及相关依赖 Java 包。
Maven 如何使用
Maven 使用项目对象模型(Project Object Model,POM)来配置,项目对象模型存储在名为 pom.xml 的文件中。以 Java 为例,我们可以在 Eclipse 中创建一个 Maven 工程。其中,Maven Dependencies 便存放着由 Maven 管理的 Jar 包。
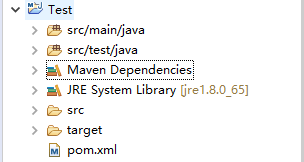
正如前面所说,构建一个 Java 工程需要使用很多 Jar 包,比如,在 Java 网络爬虫中,我们需要用到数据库连接、请求网页内容、解析网页内容的相关 Jar 包时,我们可以在上图所示的 pom 文件中添加如下语句:
之后,我们会惊讶地发现,工程的 Maven Dependencies 中自动下载了相关 Jar 包以及其依赖的 Jar 包。

读者可以在 Maven Repository 网站中检索自己想要的 Jar 包,以及 Maven 操作语句。

log4j 的使用
log4j 是什么
log4j 是一个基于 Java 的日志记录工具,曾是 Apache 软件基金会的一个项目。目前,日志是应用软件中不可或缺的部分。
log4j 怎么使用
1. 使用 Maven 下载 log4j 的 Jar 包,代码如下:
2. 在 src 目录下创建 log4j.properties 文本文件,并做相关配置(关于每个配置的具体含义,读者可参考博文 《详细的 Log4j 使用教程》):
### 设置###
log4j.rootLogger = debug,stdout,D,E
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
### 输出DEBUG 级别以上的日志到=error.log ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = E://logs/log.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
### 输出ERROR 级别以上的日志到=error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =E://logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
3. 实例程序,如下所示:
package log4j;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class Test {
static final Log logger = LogFactory.getLog(Test.class);
public static void main(String[] args) {
System.out.println("hello");
logger.info("hello world");
logger.debug("This is debug message.");
logger.warn("This is warn message.");
logger.error("This is error message.");
}
}
基于此程序,我们就可以看到在我们工程的根目录下会产生一个日志文件 error.log 和 log.log。

在网络爬虫中,我们可以使用日志记录程序可能出错的地方,监控程序的运行状态。
对象的创建
在 Java 中,经常使用 new 关键字来创建一个对象。例如,在爬取京东商品的id、product_name(商品名称)、price(价格)时,我们需要将每个商品的信息封装到对象里。
JdInfoModel jingdongproduct = new JdInfoModel();
在爬虫中,我们要操作 JdInfoModel 类中的变量(即id、product_name、price),可以使用 private 变量定义的方式。并且,使用 set() 与 get() 方法对数据进行设置(爬取数据的封装)和获取使用(爬取数据的存储)。下面的代码为 JdInfoModel 类:
package model;
public class JdInfoModel {
private int id;
private String product_name;
private double price;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getProduct_name() {
return product_name;
}
public void setProduct_name(String product_name) {
this.product_name = product_name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
集合的使用
网络爬虫离不开对集合的操作,这里涉及到 List、Set、Queue、Map 等集合的操作。
List 和 Set 集合的使用
List 的特征是其元素以线性方式存储,集合中可以存放重复对象。对比而言,Set 集合中的对象不按特定的方式排序,并且没有重复对象。在网络爬虫中,可以使用 List
//List集合的创建
List
urllist.add("https://movie.douban.com/subject/27608425");
urllist.add("https://movie.douban.com/subject/26968024");
//第一种遍历方式
for( String url : urllist ){
System.out.println(url);
}
//第二种遍历方式
for( int i=0; i System.out.println(i+":"+urllist.get(i)); } //第三种遍历方式 Iterator while ( it.hasNext() ){ System.out.println(it.next()); } 同时我们也可以使用上面 List Map 的使用 Map 是一种把键对象和值对象进行映射的集合,它的每一个元素都包含一对键对象和值对象,其中键对象不可以重复。Map 不仅在网络爬虫中常用,也常在文本挖掘算法的编写中使用。在网络爬虫中,可以使用 Map 过滤一些重复数据,但并建议使用 Map 对大规模数据去重过滤,原因是 Map 有空间大小的限制。比如,使用网络爬虫爬取帖子时,可能遇到置顶帖,而置顶帖可能会与下面的帖子重复出现。以下程序为 Map 的使用案例: //Map的创建 Map //值的添加,这里假设是爬虫中的产品id以及每个产品id对应的销售量 map.put("jd1515", 100); map.put("jd1516", 300); map.put("jd1515", 100); map.put("jd1517", 200); map.put("jd1518", 100); //第一种方法遍历 for (String key : map.keySet()) { Integer value = map.get(key); System.out.println("Key = " + key + ", Value = " + value); } //第二种方法遍历 Iterator while (entries.hasNext()) { Entry System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); } //第三种方法遍历 for (Entry System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); } Queue 的使用 队列(Queue)使用链表结构存储数据,是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作。LinkedList 类实现了 Queue 接口,因此我们可以把 LinkedList 当成 Queue 来用。Queue 常用来存待爬 URL 队列。 Queue //添加元素 queue.offer("https://www.douban.com/people/46077896/likes/topic/"); queue.offer("https://www.douban.com/people/1475408/likes/topic"); queue.offer("https://www.douban.com/people/3853295/likes/topic/"); boolean t = true; while (t) { //如果Url队列为空,停止执行程序,否则请求Url if( queue.isEmpty() ){ t = false; }else { //请求的url String url = queue.poll(); System.out.println(url); //这里要写请求数据,获取相应状态码,如果状态码为200,则解析数据;如果为404,url移除队列;否则该url重新如列 } 正则表达式的使用 正则表达式,是在解析数据(HTML 或 JSON 等)时,常用的方法。举个列子,我想从下面的语句中提取用户的 id(75975500): 后面,我会介绍解析工具 jsoup,其可以解析获得 “//i.autohome.com.cn/75975500”。接着,便可以使用正则表达式提取 75975500。 String url = "//i.autohome.com.cn/75975500"; String user_id = url.replaceAll("D", ""); //取代所有的非数字字符 System.out.println(user_id); //输出的结果即为75975500 如下表所示,是 Java 中一些常用的基本正则表达式。 HTTP 状态码 当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含 HTTP 状态码的信息头(Server Header)用以响应浏览器的请求。在网络爬虫向后台请求一个 URL 地址时,便会返回状态码,该状态码中包含丰富的信息。例如,200表示请求成功,成功获取到了后台传的数据(HTML 或 JSON 等);301资源(网页等)被永久转移到其它 URL;404请求的资源(网页等)不存在等。以下是 HTTP 状态码的分类。 详细的 HTTP 状态码列表,读者可以参考这个地址。 其他 另外,网络爬虫还涉及到其他方面的 Java 知识,比如说Java 输入输出流、Java 操作数据库、Java 多线程操作、Java 对日期的处理、Java 中的接口与继承。所以,以网络爬虫,入门 Java 编程是非常好的方式。 小编整理了一些java进阶学习资料和面试题,需要资料的请加JAVA高阶学习Q群:664389243 这是小编创建的java高阶学习交流群,加群一起交流学习深造。群里也有小编整理的2019年最新最全的java高阶学习资料!