写在前面
由于看其他文章的需要,最近刚看ICCV一篇的关于图像语义分割的文章,作为小白的我是第一次接触图像语义分割(好吧,其实CNN也是菜鸟),阅读文章之余做一些笔记,以便以后的查阅。我挑出文章的重点部分进行讲解,有不妥之处还希望指出。
整体架构
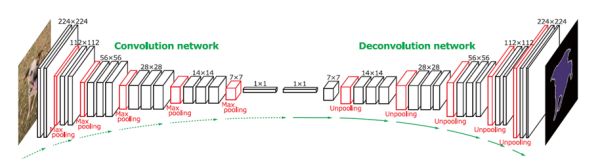
比较类似于SegNet的 "Encode-Decode"的过程,网络的架构如下图,与SegNet有着很大的相似的地方,整体是一个VGG 16中卷积操作部分的架构。
作者在文中指出,FCN在图像语义分割的时候主要是注重物体的整体轮廓,而忽略了物体的细小的特征,本文正是改善了FCN这样的缺点。
Detail
unpooling
相信也有跟我一样的小白虽然知道convolution 和 pooling,但对deconvolution 和 unpooling却不了解,这边我稍微解释一下unpooling,关于deconvolution我贴出一个链接以及论文。

上图左边是我们熟悉的pooling过程,相当于对图片的下采样过程,右边为unpooling的过程。
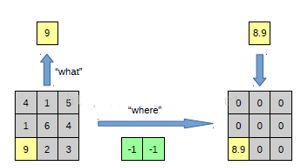
unpooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到3*3个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。
deconvolution
关于deconvolution其实不是字面意思的逆卷积,容易产生误解,deconvolution可以解释为三个方面,这篇论文中的deconvolution主要起的作用就是其中一种的upsampling,具体的阅读这篇论文(正在读):《Visualizing and Understanding Convolutional Networks》,CNN可视化的开山之作。
Analysis
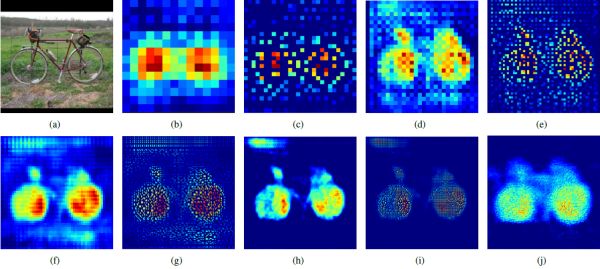
作者发现,神经网络的lower layer主要关注的是物体的大体轮廓,但是随着层数的增加,到了higher layer的时候网络主要关注物体的class-specific shapes。
Training
在training过程中,作者也用了一些小技巧让网络能够在小样本上训练,有以下几点:
BN
大家耳熟能详了,作者在每一层之间都加入了一个BN过程,为standard Gaussian distribution。
two-stage Training
训练过程分为两步,第一步作者使用一些比较容易的样本训练网络,比如手工指定proposal的位置,背景不复杂的图片等;
而在第二步中,为了能够使网络达到instance-wise的效果(很好的分割出单个物体),作者使用一些较难的样本来对网络进行fine-tune。
Aggregating
由于图像在分割之前会被分为多张proposals,所以在最终输出图像的时候需要将这些分割之后的proposal进行聚合。聚合主要有两种聚合的策略:
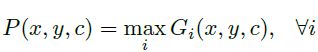
or

其中每个Gi都是由多个proposal gi组成的。
Ensemble with FCN
由于FCN在分割物体大体形状方面有着一定的优势,所以作者还将FCN结合到自己的整个系统当中,整个网络的架构如下(自己画的渣图):

值得一说的是两个网络的输出是通过平均之后再丢给CRF进行最后的处理,最终输出为一张分割之后的图像。
实验
实验这部分,可以看出,随着proposal的数量增多,更多微小的物体被分割了出来,达到了instance-wise的效果。

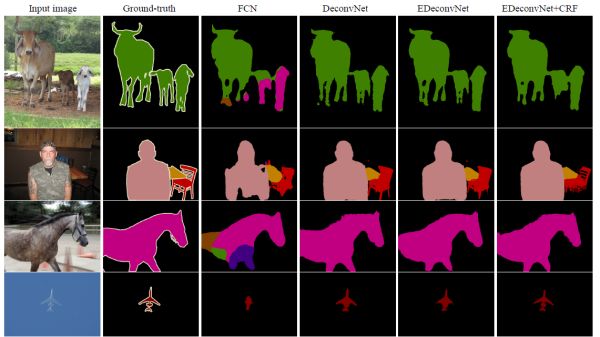
同时可以看出DeconvNet的总体效果要好于FCN,当ensemble了FCN 和 CRF效果会更好。
以上就是我对这篇文章的一些非常浅显的理解,总体来说算是比较容易读懂的,有不当的地方还请指出。