前言
实现语言:Javascript
编译工具:webstorm
GitHub:https://github.com/NPjuan/WC.git
项目要求
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:
程序处理用户需求的模式为:
wc.exe [parameter] [file_name] (由于网络原因,打包工具暂时无法下载,未能实现打包成exe文件,所以需求模式目前未能完成,只能通过GUI模式,如需使用命令行需按如下方式)
node wc.js
其中
基本功能列表:
| 功能 | 实现情况 |
|---|---|
| 返回文件 file.txt 的字符数) | 已实现 |
| 返回文件 file.txt 的词的数目) | 已实现 |
| 返回文件 file.txt 的行数 | 已实现 |
| 递归处理目录下符合条件的文件 | 已实现 |
| 返回更复杂的数据(代码行 / 空行 / 注释行) | 实现注释行 |
| 调用GUI完成上述功能 | 已实现 |
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。一个有趣的例子是有些程序员会在单字符后面加注释:
} //注释
在这种情况下,这一行属于注释行。
解题思路
由于个人对JS语言较熟悉的原因,使用了JS来编写本题,对题目的理解为调用读取文件的api并利用正则表达式返回需要的数据,这里需要在node环境下执行,又由于需要打包成exe文件执行,则需要安装electron作为开发,可惜electron打包工具下载了N次依然下载失败,目前使用命令行的方式需要变为node wc.js
设计实现过程
- 调用node.js的api来实现读取文件
- 先解决对单独文件的分析
- 使用正则表达式匹配
- 先去除各种标点符号作为干扰,如
name, - 将部分缩写变为全写,如
this's --> this is - 清除无意义的换行,空行
- 区分普通单词和在注释里的单词,将其分开
- 获取单词,字母,行数等等
- 先去除各种标点符号作为干扰,如
- 通过递归调用,读取文件夹内的文件,再复用上述过程
- 对于单独文件之间输出,对于文件夹则先将数组扁平化再输出
代码说明
主要功能代码 wc.js
executor函数为主入口函数,参数可选绝对路径或相对路径或不选,返回值为文件或文件夹的详细信息
analyise函数为文本分析函数,返回文本的详细信息
ergodicDirSync为文件夹分析函数,返回值类型为数组,包含文件夹内所有符合文件类型的文本信息对象
const fs = require('fs');
const path = require('path')
// 当前目录下绝对地址
// process.argv 第一个参数为执行路径,第二个为参数
// 获取选择的路径
// 分析文件夹
function ergodicDirSync(filePath) {
try {
// 获取当前路径下的所有文件
let arr = []
let result = fs.readdirSync(filePath)
result.forEach((fileName) => {
// 获取文件的绝对地址 如果是 node_modules 则排除在外
if (fileName === 'node_modules') {
return
}
let fileDir = path.join(filePath, fileName)
let fileStatus = fs.statSync(fileDir)
// 如果是文件而非目录 // 匹配 txt js
if (fileStatus.isFile() && fileName.match(/.[txt|js]$/g)) {
arr.push(analysisFileSync(fileDir))
} else if (fileStatus.isDirectory()) {
// 递归
arr.push(ergodicDirSync(fileDir))
} else {
console.log(`${fileName} 文件格式不符合要求`)
}
})
return arr
} catch (e) {
console.warn(e)
return arr
}
}
// 分析文件
function analysisFileSync(filePath) {
let context = fs.readFileSync(filePath, 'utf-8')
let result = analysis(context)
result.filePath = filePath
return result
}
// 读取文件
function readFile(filePath){
return new Promise((resolve, reject)=>{
fs.readFile(filePath, 'utf-8', (err, file) => {
if ( err ) {
reject(err)
}
resolve(file)
})
})
}
// 文件文本分析
function analysis(context) {
let time = new Date()
if (context.length === 0) {
return {
pureWords: 0,
pureLetters: 0,
words: 0,
lines: 0,
letters: 0,
notes: 0,
multilineComment: 0,
'time': new Date()-time,
code: 0
}
}
// 清除缩写,例如 Here's // 清除标点符号
let pureText = context.replace(/'s/gm, ' is').replace(/[^\s\/\*\w\u4e00-\u9fa5]/gm, '')
// 获取单词数,不含中文
let words = pureText.match(/[a-zA-Z0-9_$]+/gm)
// 获取字母
let letters = pureText.match(/\w/gm)
// 获取行数并清除无意义的换行,这里必须用到context否则如果一行文本只有标点符号会被忽略
let lines = context.split(/\r\n/gm).filter((item)=>{
return item !== ''
})
// 获取单行注释
let notes = lines.map(temp => {
if (temp.match(/\/\/[^\n]*/)) {
return temp.match(/\/\/[^\n]*/)[0]
} else {
return ''
}
}).filter((item)=>{
return item !== ''
})
// 获取多行注释 使用 *?非贪婪模式
let multilineComment = pureText.match(/(\/\*)(.|\n|\r)*?(\*\/)/gm)
// 获取注释以外的单词
// 第一个 replace 除去单行注释 //
// 第二个 replace 除去多行注释 /**/
let pureWords = pureText.replace(/\/\/[^\n]*/gm,'').replace(/(\/\*)(.|\n|\r)*?(\*\/)/gm,
'').match(/[a-zA-Z0-9_$]+/gm)
// 获取注释以外的字母
let pureLetters = pureText.replace(/\/\/[^\n]*/gm,'').replace(/(\/\*)(.|\n|\r)*?(\*\/)/gm,
'').match(/\w/gm)
return {
pureWords: pureWords?pureWords.length:0,
pureLetters: pureLetters?pureLetters.length:0,
words: words?words.length:0,
lines: lines?lines.length:0,
letters: letters?letters.length:0,
notes: notes?notes.length:0,
multilineComment: multilineComment?multilineComment.length:0,
'time': new Date()-time,
code: 1
}
}
// 默认为当前路径
function executor(curFilePath = path.resolve(''), platform = 1) {
// 如果是从node.js 附带参数命令启动
if (process.argv[2] && platform) {
// 如果传递的是根路径
if (process.argv[2].match(/^[a-zA-Z]+:/g)) {
curFilePath = process.argv[2]
} else {
// 否则传递的是相对路径
curFilePath = ((curPath, dir)=>{
let pos = curPath.lastIndexOf('\\')
return path.join(curPath.slice(0, pos),dir?dir:'')
})(process.argv[1], process.argv[2])
}
console.log(curFilePath)
}
let result = undefined
let fileStatus = fs.statSync(curFilePath)
if (fileStatus.isFile()) {
console.log('你选择了文件')
result = analysisFileSync(curFilePath)
} else if (fileStatus.isDirectory()) {
console.log('你选择了文件夹')
result = ergodicDirSync(curFilePath)
}
console.log(result)
return result
}
主函数 main.js 调用GUI
let electron = require('electron')
let app = electron.app
let BrowserWindow = electron.BrowserWindow
let mainWindow = null
app.on('ready', ()=>{
mainWindow = new BrowserWindow({
width: 800,
height: 800,
webPreferences: {
nodeIntegration: true
}
})
mainWindow.loadFile('./index.html')
mainWindow.on('closed', ()=>{
mainWindow = null
})
})
测试运行
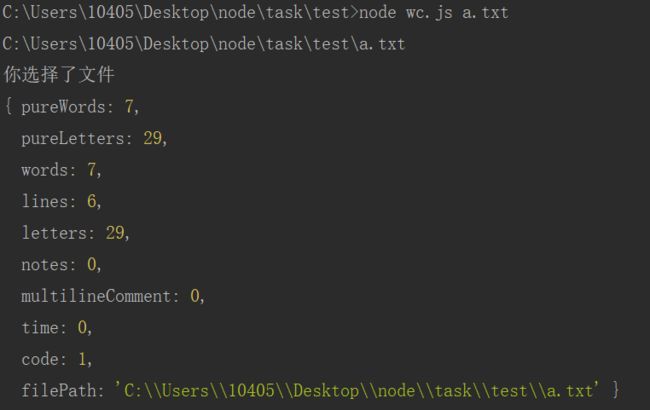
命令行模式无参数模式

命令行带参数模式
GUI

GUI多文件

其中pureWords是排除在注释内的单词,pureLetters同理
项目小结
本次项目用了很多以前不曾用过或者用的很少的知识和工具,在复习和学习新技术上使用了较多的时间,所以明白了笔记的重要性,可以快速的复习,平时需要注重积累。对于新知识的学习需要明白自己最需要的是什么,单刀直入,不在一些细枝末节浪费时间,先快速开发,能用再说,后续再回头看
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| · Estimate | ·预估这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 550 | 1025 |
| · Analysis | · 需求分析(包括学习新技术) | 180 | 210 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审(和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范(为目前开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 20 | 40 |
| · Coding | · 具体编码 | 240 | 650 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 45 |
| Reportin | 报告 | 55 | 110 |
| · Test Report | · 测试报告 | 30 | 75 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结 | 20 | 15 |
| 合计 | 605 | 1135 |