欢迎关注“百度NLP”官方微信公众号,及时获取更多自然语言处理领域的技术干货!
语义解析(Semantic Parsing)是自然语言处理技术的核心任务之一,涉及语言学、计算语言学、机器学习以及认知语言等多个学科,在近几年中获得了广泛关注,语义解析任务有助于促进机器语言理解的快速发展。
本文重点介绍语义解析技术中的Text-to-SQL任务,让机器自动将用户输入的自然语言问题转成数据库可操作的SQL查询语句,实现基于数据库的自动问答能力。
任务介绍及研究动机
当前,大量信息存储在结构化和半结构化知识库中,如数据库。对于这类数据的分析和获取需要通过SQL等编程语言与数据库进行交互操作,SQL的使用难度限制了非技术用户,给数据分析和使用带来了较高的门槛。人们迫切需要技术或工具完成自然语言与数据库的交互,因此诞生了Text-to-SQL任务。
我们通过图1中的实例来介绍一下Text-to-SQL任务。该任务包含两部分:Text-to-SQL解析器和SQL执行器。
解析器的输入是给定的数据库和针对该数据库的问题,输出是问题对应的SQL查询语句,如图中红色箭头标示。SQL执行器在数据库上完成该查询语句的执行,及给出问题的最终答案,如图中绿色箭头标示。
SQL执行器有很多成熟的系统,如MySQL,SQLite等,该部分不是本文重点。本文主要介绍解析器,学术界中Text-to-SQL任务默认为Text-to-SQL解析模型。

图1
首先,我们介绍一下术语“数据库”和“SQL查询语句”:
1、数据库由一张或多张表格构成,表格之间的关系通过外键给出。在该实例中,数据库由表 “中国城市”和“2018年宜居城市” 构成,两张表通过外键:“中国城市”的“名称”列和“2018年宜居城市”的“名称”列关联;
2、SQL是数据库查询语言,其构成来自3部分:数据库(如实例SQL查询语句中蓝色标注的成分)、问题(如实例SQL查询语句红色标注的成分)、SQL关键词(如实例SQL查询语句中的Select、From、Where等)。
其次,我们介绍一下Text-to-SQL解析模型。根据SQL的构成,解析器需要完成两个任务,即“问题与数据库的映射”和“SQL生成”。
在问题与数据库的映射中,需要找出问题依赖的表格以及具体的列,如图1实例中,问题“绿化率前5的城市有哪些,分别隶属于哪些省?”依赖的数据库内容包括:表格“中国城市”,具体的列“名称”、“所属省”、“绿化率”(SQL查询语句蓝色标注成分)。
在SQL生成中,结合第一步识别结果以及问题包含信息,生成满足语法的SQL查询语句,如实例中的“Select 名称,所属省 From 中国城市 Where 绿化率 > 30%”。
Text-to-SQL研究进展
Text-to-SQL技术能够有效地辅助人们对海量的数据库进行查询,因其有实用的应用场景,引起了学术界和工业界的广泛关注。我们接下来将从相关数据集和模型两方面介绍该技术的研究进展。
1、数据集介绍
图2给出了Text-to-SQL数据集发展趋势,代表数据集参见表1。

图2
其中术语介绍:
- 根据包含领域数量,数据集分为单领域和多领域。
- 根据每个数据库包含表的数量,数据集分为单表和多表模式。在多表模式中,SQL生成涉及到表格的选择。
- 根据问题复杂度,数据集分为简单问题和复杂问题模式,其中问题复杂度由SQL查询语句涉及到的关键词数量、嵌套层次、子句数量等确定。
- 根据完整SQL生成所需轮数,数据集分为单轮和多轮。
- 若SQL生成融进渐进式对话,则数据集增加“结合对话”标记。当前只有CoSQL数据集是融进对话的数据集。
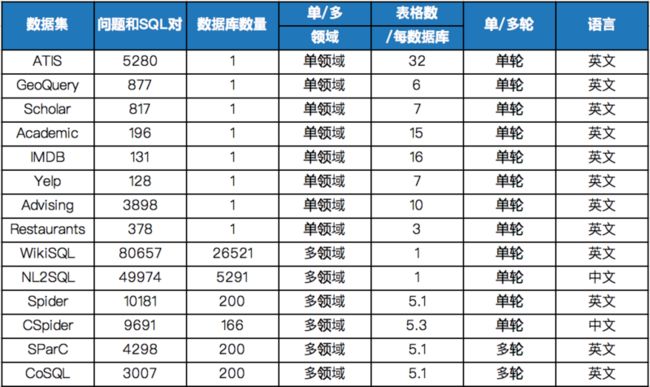
表1
由图2和表1可知,当前主流数据集都是多领域的,这就要求Text-to-SQL解析模型除了满足问题无关外,还要满足领域无关。
2、模型介绍
SQL查询语句是一个符合语法、有逻辑结构的序列,其构成来自三部分:数据库、问题、SQL关键词。
在当前深度学习研究背景下,Text-to-SQL任务可被看作是一个类似于神经机器翻译的序列到序列的生成任务,主要采用Seq2Seq模型框架。基线Seq2Seq模型加入注意力、拷贝等机制后,在单领域数据集上可以达到80%以上的准确率,但在多领域数据集上效果很差,准确率均低于25%。
从编码和解码两个方面进行原因分析。
在编码阶段,问题与数据库之间需要形成很好的对齐或映射关系,即问题中涉及了哪些表格中的哪些元素(包含列名和表格元素值);同时,问题与SQL语法也需要进行映射,即问题中词语触发了哪些关键词操作(如Group、Order、Select、Where等)、聚合操作(如Min、Max、Count等)等;最后,问题表达的逻辑结构需要表示并反馈到生成的SQL查询语句上,逻辑结构包括嵌套、多子句等。
在解码阶段,SQL语言是一种有逻辑结构的语言,需要保证其语法合理性和可执行性。普通的Seq2Seq框架并不具备建模这些信息的能力。
当前基于Seq2Seq框架,主要有以下几种改进。
1)基于Pointer Network的改进
首先,SQL组成来自三部分:数据库中元素(如表名、列名、表格元素值)、问题中词汇、SQL关键字。其次,当前公开的多领域数据集为了验证模型数据库无关,在划分训练集和测试集时要求数据库无交叉,这种划分方式导致测试集数据库中很大比例的元素属于未登录词。传统的Seq2Seq模型是解决不好这类问题的。
Pointer Network很好地解决了这一问题,其输出所用到的词表是随输入而变化的。具体做法是利用注意力机制,直接从输入序列中选取单词作为输出。在Text-to-SQL任务中,将问题中词汇、SQL关键词、对应数据库的所有元素作为输入序列,利用Pointer Network从输入序列中拷贝单词作为最终生成SQL的组成元素。
由于Pointer Network可以较好的满足具体数据库无关这一要求,在多领域数据集上的模型大多使用该网络,如Seq2SQL[1]、STAMP[8]、Coarse2Fine[9]、IRNet[16]等模型。
2)基于Sequence-to-set的改进
在简单问题对应的数据集合上,其SQL查询语句形式简单(仅包含Select和Where关键词),为了解决Seq2Seq模型中顺序错误带来的影响(如“条件1 And 条件2”,预测为“条件2 And 条件1”,属于顺序错误,但对应的SQL是正确的),SQLNet[10]提出了Sequence-to-set模型,基于所有的列预测其属于哪个关键词(即属于Select还是Where,在SQLNet模型中仅预测是否属于Where),针对SQL 中每一个关键词选择概率最高的前K个列。
该模式适用于SQL形式简单的数据集,在WikiSQL和NL2SQL这两个数据集合上使用较多,且衍生出很多相关模型,如TypeSQL[11]、SQLova[12]、X-SQL[13]等。

图3 Sequence-to-Set
3)基于TRANX(自顶向下文法生成)的改进
复杂问题对应的SQL查询语句形式也复杂,涉及到多关键词组合、嵌套、多子句等。并且,测试集合中的某些SQL查询语句形式在训练集合中没有见过,这就要求模型不仅对新数据库具有泛化能力,对新SQL查询语句形式也要有泛化能力。
针对这种情况,需要更多关注生成SQL的逻辑结构。为了保证SQL生成过程中语法合理,一些模型开始探索及使用语法树生成的方法。
TRANX_[14]_框架借鉴了AST[15]论文思想,根据目标语言的语法构建规约文法,基于该文法可以将生成目标表示为语法树(需要保证生成目标与语法树表示一一对应),然后实现了自顶向下的语法树生成系统,图4给出了该系统流程。
我们简单介绍一下基于该系统实现Text-to-SQL任务。
首先,根据SQL语法制定规约文法(对应图4中的ASDL Grammar),需要保证每一条SQL查询语句均可由该文法产出。
其次,设计动作集合用于转移系统(图4中的Transition System),基于该转移系统选择合理的规约文法生成语法树,该转移系统将语法树的生成转成动作序列的生成,即转成一系列文法的选择序列,文法在选择过程中保证了合理性(即孩子节点文法均在父节点允许的文法范围内);该动作序列的生成可基于Seq2Seq等框架进行。
该框架在代码生成、SQL生成等任务上都已验证过,在Text-to-SQL任务上的模型包括IRNet[16]、Global GNN[17]、RATSQL[18]等。
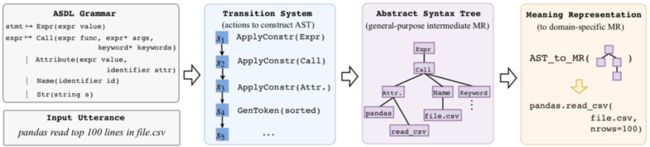
图4:基于TRANX的code生成
4)其他改进
在多表数据集合上,一些模型加入图网络来增强数据库的表示,如Global GNN[17]、RATSQL[18]等。在WikiSQL数据集合上,由于该数据集给出了SQL执行系统,部分模型通过加入执行指导[19]来提升SQL的可执行性和准确率。
3、评价方法
Text-to-SQL任务的评价方法主要包含两种:精确匹配率(Exact Match, Accqm)、执行正确率(Execution Accuracy, Accex)。
精确匹配率指,预测得到的SQL语句与标准SQL语句精确匹配成功的问题占比。为了处理由成分顺序带来的匹配错误,当前精确匹配评估将预测的SQL语句和标准SQL语句按着SQL关键词分成多个子句,每个子句中的成分表示为集合,当两个子句对应的集合相同则两个子句相同,当两个SQL所有子句相同则两个SQL精确匹配成功;

执行正确指,执行预测的SQL语句,数据库返回正确答案的问题占比。

目前仅WikiSQL数据集支持Acc_ex_,其他数据集仅支持Accqm。大部分数据集发布了对应的评估脚本,方便大家在同一个评估标准下进行算法研究。
参考文献
[1] Seq2sql: Generating structured queries from natural language using reinforcement learning (Victor Zhong, Caiming Xiong, Richard Socher. CoRR2017)
[2] Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task (Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, etc. EMNLP2018)
[3] A Pilot Study for Chinese SQL Semantic Parsing (Qingkai Min, Yuefeng Shi, Yue Zhang. EMNLP2019)
[4] SParC: Cross-Domain Semantic Parsing in Context (Tao Yu, Rui Zhang, Michihiro Yasunaga, Yi Chern Tan, etc. ACL2019)
[5] CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases (Tao Yu, Rui Zhang, He Yang Er, Suyi Li, Eric Xue, etc. EMNLP2019)
[6] https://tianchi.aliyun.com/ma..._cn
[7] Pointer Networks (OriolVinyals, Meire Fortunato, Navdeep Jaitly. NIPS2015)
[8] Semantic Parsing with Syntax- and Table-Aware SQL Generation (Yibo Sun, Duyu Tang, Nan Duan, etc. ACL2018)
[9] Coarse-to-Fine Decoding for Neural Semantic Parsing (Li Dong, Mirella Lapata. ACL2018)
[10] SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning (Xiaojun Xu, Chang Liu, DawnSong. CoRR 2018)
[11] TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation (Tao Yu, Zifan Li, Zilin Zhang, Rui Zhang, Dragomir Radev. NAACL2018)
[12] Achieving 90% accuracy in WikiSQL (Wonseok Hwang, Jinyeong Yim, SeungHyun Park, Mnjoon Seo. CoRR2019)
[13] X-SQL: Reinforce Context Into Schema Representation (Pengcheng He, Yi Mao, Kaushik Chakrabarti, Weizhu Chen. CoRR2019)
[14] TRANX: A Transition-based Neural Abstract Syntax Parser for Semantic Parsing and Code Generation (Pengcheng Yin, Graham Neubig, EMNLP 2018 )
[15] Abstract syntax networks for code generation and semantic parsing (Maxim Rabinovich, Mitchell Stern, Dan Klein. ACL2017)
[16] Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation (Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, Dongmei Zhang. ACL2019)
[17] Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing (Ben Bogin, Matt Gardner, Jonathan Berant. ACL2019)
[18] RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers (Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, Matthew Richardson. Submitted to ACL2020)
[19] Robust Text-to-SQL Generation with Execution-Guided Decoding (Chenglong Wang, Kedar Tatwawadi, Marc Brockschmidt, Po-Sen Huang, Yi Mao, Oleksandr Polozov, Rishabh Singh. CoRR2018)
百度自然语言处理(Natural Language Processing,NLP)以『理解语言,拥有智能,改变世界』为使命,研发自然语言处理核心技术,打造领先的技术平台和创新产品,服务全球用户,让复杂的世界更简单。
