论文指出one-stage anchor-based和center-based anchor-free检测算法间的差异主要来自于正负样本的选择,基于此提出ATSS(Adaptive Training Sample Selection)方法,该方法能够自动根据GT的相关统计特征选择合适的anchor box作为正样本,在不带来额外计算量和参数的情况下,能够大幅提升模型的性能,十分有用
来源:晓飞的算法工程笔记 公众号
论文: Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection

Introduction
在仔细比对了anchor-based和anchor-free目标检测方法后,结合实验结果,论文认为两者的性能差异主要来源于正负样本的定义,假如训练过程中使用相同的正负样本,两者的最终性能将会相差无几。为此,论文提出ATSS( Adaptive Training Sample Selection)方法,基于GT的相关统计特征自动选择正负样本,能够消除anchor-based和anchor-free算法间的性能差异
论文的主要贡献如下:
- 指出anchor-free和anchor-based方法的根本差异主要来源于正负样本的选择
- 提出ATSS( Adaptive Training Sample Selection)方法来根据对象的统计特征自动选择正负样本
- 证明每个位置设定多个anchor是无用的操作
- 不引入其它额外的开销,在MS COCO上达到SOTA
Difference Analysis of Anchor-based and Anchor-free Detection
论文选取anchor-based方法RetinaNet和anchor-free方法FCOS进行对比,主要对比正负样本定义和回归开始状态的差异,将RetinaNet的anchor数改为1降低差异性,方便与FCOS比较,后续会测试anchor数带来的作用
Inconsistency Removal

由于FCOS加入了很多trick,这里将RetinaNet与其进行对齐,包括GroupNorm、GIoU loss、限制正样本必须在GT内、Centerness branch以及添加可学习的标量控制FPN的各层的尺寸。结果如表1,最终的RetinaNet仍然与FCOS有些许的性能差异,但在实现方法上已经基本相同了
Essential Difference
在经过上面的对齐后,仅剩两个差异的地方:(i) 分类分支上的正负样本定义 (ii) 回归分支上的bbox精调初始状态(start from anchor box or anchor point)
Classification
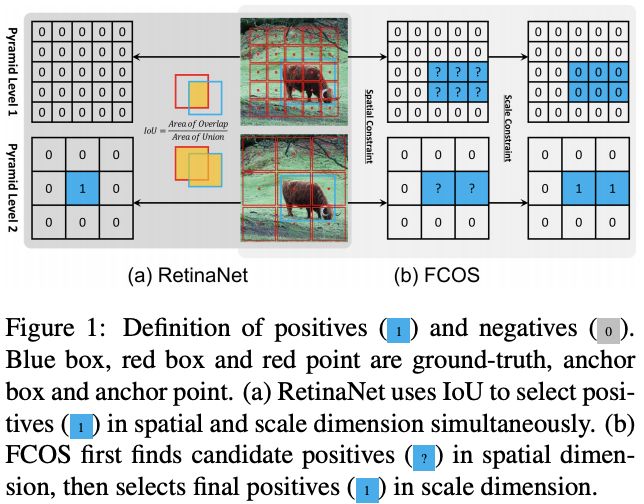
RetinaNet使用IoU阈值($\theta_p$,$\theta_n$)来区分正负anchor bbox,处于中间的全部忽略。FCOS使用空间尺寸和尺寸限制来区分正负anchor point,正样本首先必须在GT box内,其次需要是GT尺寸对应的层,其余均为负样本
Regression

RetinaNet预测4个偏移值对anchor box进行调整输出,而FCOS则预测4个相对于anchor point值对anchor box进行调整输出
Conclusion

对上面的差异进行交叉实验,发现相同的正负样本定义下的RetinaNet和FCOS性能几乎一样,不同的定义方法性能差异较大,而回归初始状态对性能影响不大。所以,基本可以确定正负样本的确定方法是影响性能的重要一环
Adaptive Training Sample Selection
Description

论文提出ATSS方法,该方法根据目标的相关统计特征自动进行正负样本的选择,具体逻辑如算法1所示。对于每个GT box $g$,首先在每个特征层找到中心点最近的$k$个候选anchor boxes(非预测结果),计算候选box与GT间的IoU $\mathcal{D}_g$,计算IoU的均值$m_g$和标准差$v_g$,得到IoU阈值$t_g=m_g+v_g$,最后选择阈值大于$t_g$的box作为最后的输出。如果anchor box对应多个GT,则选择IoU最大的GT
ATSS的思想主要考虑了下面几个方向:
Selecting candidates based on the center distance between anchor box and object
在RetinaNet中,anchor box与GT中心点越近一般IoU越高,而在FCOS中,中心点越近一般预测的质量越高
Using the sum of mean and standard deviation as the IoU threshold

均值$m_g$表示预设的anchor与GT的匹配程度,均值高则应当提高阈值来调整正样本,均值低则应当降低阈值来调整正样本。标准差$v_g$表示适合GT的FPN层数,标准差高则表示高质量的anchor box集中在一个层中,应将阈值加上标准差来过滤其他层的anchor box,低则表示多个层都适合该GT,将阈值加上标准差来选择合适的层的anchor box,均值和标准差结合作为IoU阈值能够很好地自动选择对应的特征层上合适的anchor box
Limiting the positive samples’ center to object
若anchor box的中心点不在GT区域内,则其会使用非GT区域的特征进行预测,这不利于训练,应该排除
Maintaining fairness between different objects
根据统计原理,大约16%的anchor box会落在$[m_g+v_g, 1]$,尽管候选框的IoU不是标准正态分布,但统计下来每个GT大约有$0.2 * k\mathcal{L}$个正样本,与其大小和长宽比无关,而RetinaNet和FCOS则是偏向大目标有更多的正样本,导致训练不公平
Keeping almost hyperparameter-free
ATSS仅有一个超参数$k$,后面的使用会表明ATSS的性能对$k$不敏感,所以ATSS几乎是hyperparameter-free的
Verification
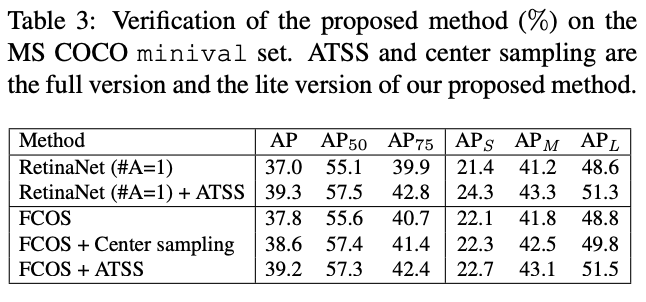
将ATSS应用到RetinaNet和FCOS上测试效果:
- 将RetinaNet中的正负样本替换为ATSS,AP提升了2.9%,这样的性能提升几乎是没有任何额外消耗的
- 在FCOS上的应用主要用两种:lite版本采用ATSS的思想,从选取GT内的anchor point改为选取每层离GT最近的top $k$个候选anchor point,提升了0.8%AP;full版本将FCOS的anchor point改为长宽为$8S$的anchor box来根据ATSS选择正负样本,但仍然使用原始的回归方法,提升了1.4%AP。两种方法找到的anchor point在空间位置上大致相同,但是在FPN层上的选择不太一样。从结果来看,自适应的选择方法比固定的方法更有效
Analysis

参数k在区间$[7,17]$几乎是一样的,过大的设置会到导致过多的低质量候选anchor,而过小的设置则会导致过少的正样本,而且统计结果也不稳定。总体而言,参数$k$是相对鲁棒的,可以认为ATSS是hyperparameter-free
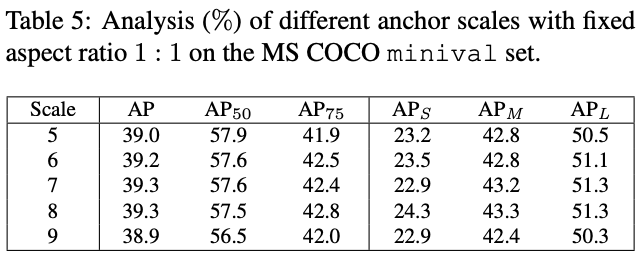

在FCOS的full版本中使用了$8S$的anchor box,论文对不同的尺寸进行了对比,如表5所示,也在$8S$基础上对不同的长宽比进行了对比,如表6所示。从结果来看,性能几乎对尺寸和长宽比无关,相对鲁棒
Discussion

前面的RetinaNet实验只用了一个anchor box,论文补充测试了不同anchor数下的性能,实验中的Imprs为表1中的提升手段。从结果来看,在每个位置设定多个anchor box是无用的操作,关键在于选择合适的正样本
Comparison

实现的是FCOS版本的ATSS,在相同的主干网络下,ATSS方法能够大幅增加准确率,十分有效
Conclusion
论文指出one-stage anchor-based和center-based anchor-free检测算法间的差异主要来自于正负样本的选择,基于此提出ATSS(Adaptive Training Sample Selection)方法,该方法能够自动根据GT的相关统计特征选择合适的anchor box作为正样本,在不带来额外计算量和参数的情况下,能够大幅提升模型的性能,十分有用
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
