区块链共识算法总结 | 原力计划


作者 | 日月ton光
责编 | 王晓曼
出品 | CSDN博客

常见共识算法介绍
在异步系统中,需要主机之间进行状态复制,以保证每个主机达成一致的状态共识。而在异步系统中,主机之间可能出现故障,因此需要在默认不可靠的异步网络中定义容错协议,以确保各个主机达到安全可靠的状态共识。
共识算法其实就是一组规则,设置一组条件,筛选出具有代表性的节点。在区块链系统中,存在很多这样的筛选方案,如在公有链中的POW、POS、DPOS等,而在不需要货币体系的许可链或私有链中,绝对信任的节点、高效的需求是公有链共识算法不能提供的,对于这样的区块链,传统的一致性共识算法成为首选,如PBFT、PAXOS、RAFT等。

BFT(拜占庭容错技术)
拜占庭容错技术是一类分布式计算领域的容错技术。拜占庭假设是由于硬件错误、网络拥塞或中断以及遭到恶意攻击的原因,计算机和网络出现不可预测的行为。拜占庭容错用来处理这种异常行为,并满足所要解决问题的规范。
拜占庭容错系统是一个拥有n台节点的系统,整个系统对于每一个请求,满足以下条件:
1)所有非拜占庭节点使用相同的输入信息,产生同样的结果;
2)如果输入的信息正确,那么所有非拜占庭节点必须接收这个信息,并计算相应的结果。
拜占庭系统普遍采用的假设条件包括:
1)拜占庭节点的行为可以是任意的,拜占庭节点之间可以共谋;
2)节点之间的错误是不相关的;
3)节点之间通过异步网络连接,网络中的消息可能丢失、乱序并延时到达,但大部分协议假设消息在有限的时间里能传达到目的地;
4)服务器之间传递的信息,第三方可以嗅探到,但是不能篡改、伪造信息的内容和验证信息的完整性。
拜占庭容错由于其理论上的可行性而缺乏实用性,另外还需要额外的时钟同步机制支持,算法的复杂度也是随节点的增加而指数级增加。

PBFT(实用拜占庭容错算法)
实用拜占庭容错降低了拜占庭协议的运行复杂度,从指数级别降低到多项式级别。
PBFT是一种状态机副本复制算法,即服务作为状态机进行建模,状态机在分布式系统的不同节点进行副本复制。PBFT要求共同维护一个状态。需要运行三类基本协议,包括一致性协议、检查点协议和视图更换协议。
一致性协议。一致性协议至少包含若干个阶段:请求(request)、序号分配(pre-prepare)和响应(reply),可能包含相互交互(prepare),序号确认(commit)等阶段。
PBFT通信模式中,每个客户端的请求需要经过5个阶段。由于客户端不能从服务器端获得任何服务器运行状态的信息,PBFT中主节点是否发生错误只能由服务器监测。如果服务器在一段时间内都不能完成客户端的请求,则会触发视图更换协议。
整个协议的基本过程如下:
1)客户端发送请求,激活主节点的服务操作。
2)当主节点接收请求后,启动三阶段的协议以向各从节点广播请求。
[2.1]序号分配阶段,主节点给请求赋值一个序列号n,广播序号分配消息和客户端的请求消息m,并将构造PRE-PREPARE消息给各从节点;
[2.2]交互阶段,从节点接收PRE-PREPARE消息,向其他服务节点广播PREPARE消息;
[2.3]序号确认阶段,各节点对视图内的请求和次序进行验证后,广播COMMIT消息,执行收到的客户端的请求并给客户端以响应。
3)客户端等待来自不同节点的响应,若有m+1个响应相同,则该响应即为运算的结果。
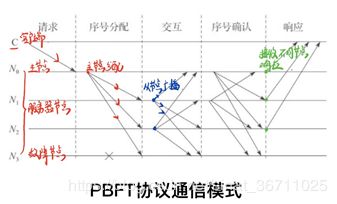
PBFT一般适合有对强一致性有要求的私有链和联盟链,例如,在IBM主导的区块链超级账本项目中,PBFT是一个可选的共识协议。在 Hyperledger 的Fabric项目中,共识模块被设计成可插拔的模块,支持像PBFT、Raft等共识算法。

PAXOS
在有些分布式场景下,其假设条件不需要考虑拜占庭故障,而只是处理一般的死机故障。在这种情况下,采用PAXOS等协议会更加高效。。PAXOS是一种基于消息传递且具有高度容错特性的一致性算法。
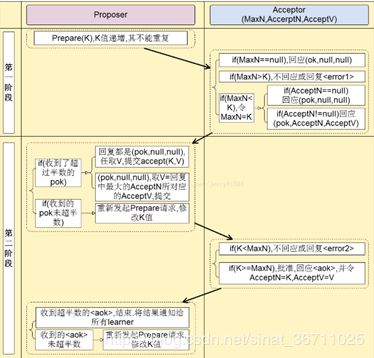
PAXOS中有三类角色Proposer、Acceptor及Learner,主要交互过程在Proposer和Acceptor之间。算法流程分为两个阶段:
1、phase1
a)proposer向网络内超过半数的acceptor发送prepare消息
b)acceptor正常情况下回复promise消息
2、phase2
a) 在有足够多acceptor回复promise消息时,proposer发送accept消息
b) 正常情况下acceptor回复accepted消息
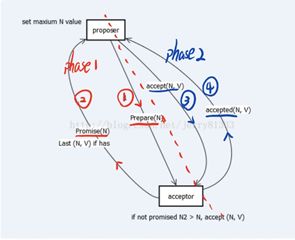
流程图如图所示:
PAXOS协议用于微信PaxosStore中,每分钟调用PAXOS协议过程数十亿次量级。

Raft
PAXOS是Lamport设计的保持分布式系统一致性的协议。但由于PAXOS非常复杂,比较难以理解,因此后来出现了各种不同的实现和变种。Raft是由Stanford提出的一种更易理解的一致性算法,意在取代目前广为使用的PAXOS算法。
Raft最初是一个用于管理复制日志的共识算法,它是在非拜占庭故障下达成共识的强一致协议。Raft实现共识过程如下:首先选举一个leader,leader从客户端接收记账请求、完成记账操作、生成区块,并复制到其他记账节点。leader有完全的管理记账权利,例如,leader能够决定是否接受新的交易记录项而无需考虑其他的记账节点,leader可能失效或与其他节点失去联系,这时,重新选出新的leader。
在Raft中,每个节点会处于以下三种状态中的一种:
(1)follower:所有节点都以follower的状态开始。如果没收到leader消息则会变成candidate状态;
(2)candidate:会向其他节点“拉选票”,如果得到大部分的票则成为leader。这个过程就叫做Leader选举(Leader Election);
(3)leader:所有对系统的修改都会先经过leader。每个修改都会写一条日志(log entry)。leader收到修改请求后的过程如下:此过程叫做日志复制(Log Replication)
1)复制日志到所有follower节点
2)大部分节点响应时才提交日志
3)通知所有follower节点日志已提交
4)所有follower也提交日志
5)现在整个系统处于一致的状态
Raft阶段主要分为两个,首先是leader选举过程,然后在选举出来的leader基础上进行正常操作,比如日志复制、记账等。
(1)leader选举
当follower在选举时间内未收到leader的消息,则转换为candidate状态。在Raft系统中:
1)任何一个服务器都可以成为候选者candidate,只要它向其他服务器follower发出选举自己的请求。
2)如果其他服务器同意了,发出OK。如果在这个过程中,有一个follower宕机,没有收到请求选举的要求,此时候选者可以自己选自己,只要达到N/2+1的大多数票,候选人还是可以成为leader的。
3)这样这个候选者就成为了leader领导人,它可以向选民也就是follower发出指令,比如进行记账。
4)以后通过心跳消息进行记账的通知。
5)一旦这个leader崩溃了,那么follower中有一个成为候选者,并发出邀票选举。
6)follower同意后,其成为leader,继续承担记账等指导工作。
(2)日志复制
记账步骤如下所示:
1)假设leader已经选出,这时客户端发出增加一个日志的要求;
2)leader要求follower遵从他的指令,将这个新的日志内容追加到各自日志中;
3)大多数follower服务器将交易记录写入账本后,确认追加成功,发出确认成功信息;
4)在下一个心跳消息中,leader会通知所有follower更新确认的项目。
对于每个新的交易记录,重复上述过程。
在这一过程中,若发生网络通信故障,使得leader不能访问大多数follower了,那么leader只能正常更新它能访问的那些follower服务器。而大多数的服务器follower因为没有了leader,他们将重新选举一个候选者作为leader,然后这个leader作为代表与外界打交道,如果外界要求其添加新的交易记录,这个新的leader就按上述步骤通知大多数follower。当网络通信恢复,原先的leader就变成follower,在失联阶段,这个老leader的任何更新都不能算确认,必须全部回滚,接收新的leader的新的更新。

POW(工作量证明)
在去中心账本系统中,每个加入这个系统的节点都要保存一份完整的账本,但每个节点却不能同时记账,因为节点处于不同的环境,接收不同的信息,如果同时记账,必然导致账本的不一致。因此通过同时来决定那个节点拥有记账权。
在比特币系统中,大约每10分钟进行一轮算力竞赛,竞赛的胜利者,就获得一次记账的权力,并向其他节点同步新增账本信息。
PoW系统的主要特征是计算的不对称性。工作端要做一定难度的工作才能得出一个结果,而验证方却很容易通过结果来检查工作端是不是做了相应的工作。该工作量的要求是,在某个字符串后面连接一个称为nonce的整数值串,对连接后的字符串进行SHA256哈希运算,如果得到的哈希结果(以十六进制的形式表示)是以若干个0开头的,则验证通过。
比特币网络中任何一个节点,如果想生成一个新的区块并写入区块链,必须解出比特币网络出的PoW问题。关键的3个要素是工作量证明函数、区块及难度值。工作量证明函数是这道题的计算方法,区块决定了这道题的输入数据,难度值决定了这道题所需要的计算量。
(1)工作量证明函数就是SHA256
比特币的区块由区块头及该区块所包含的交易列表组成。拥有80字节固定长度的区块头,就是用于比特币工作量证明的输入字符串。

(2)难度的调整是在每个完整节点中独立自动发生的。每2016个区块,所有节点都会按统一的公式自动调整难度。如果区块产生的速率比10分钟快则增加难度,比10分钟慢则降低难度。
公式可以总结为:新难度值=旧难度值×(过去2016个区块花费时长/20160分钟)
工作量证明需要有一个目标值。比特币工作量证明的目标值(Target)的计算公式:目标值=最大目标值/难度值
其中最大目标值为一个恒定值:
0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
目标值的大小与难度值成反比。比特币工作量证明的达成就是矿工计算出来的区块哈希值必须小于目标值。
(3)POW能否解决拜占庭将军问题
比特币的POW共识算法是一种概率性的拜占庭协议(Probabilistic BA)
当不诚实的算力小于网络总算力的50%时,同时挖矿难度比较高(在大约10分钟出一个区块情况下)比特币网络达到一致性的概念会随确认区块的数目增多而呈指数型增加。但当不诚实算力具一定规模,甚至不用接近50%的时候,比特币的共识算法并不能保证正确性,也就是,不能保证大多数的区块由诚实节点来提供。
比特币的共识算法不适合于私有链和联盟链。其原因首先是它是一个最终一致性共识算法,不是一个强一致性共识算法。第二个原因是其共识效率低。
扩展知识:一致性

严格一致性,是在系统不发生任何故障,而且所有节点之间的通信无需任何时间这种理想的条件下,才能达到。这个时候整个系统就等价于一台机器了。在现实中,是不可能达到的。
强一致性,当分布式系统中更新操作完成之后,任何多个进程或线程,访问系统都会获得最新的值。
弱一致性,是指系统并不保证后续进程或线程的访问都会返回最新的更新的值。系统在数据成功写入之后,不承诺立即可以读到最新写入的值,也不会具体承诺多久读到。但是会尽可能保证在某个时间级别(秒级)之后。可以让数据达到一致性状态。
最终一致性是弱一致性的特定形式。系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。也就是说,如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。

POS(权益证明)
在股权证明POS模式下,有一个名词叫币龄,每个币每天产生1币龄,比如你持有100个币,总共持有了30天,那么,此时你的币龄就为3000,这个时候,如果你发现了一个POS区块,你的币龄就会被清空为0。你每被清空365币龄,你将会从区块中获得0.05个币的利息(假定利息可理解为年利率5%),那么在这个案例中,利息 = 3000 * 5% / 365 = 0.41个币,这下就很有意思了,持币有利息。
点点币(Peercoin)是首先采用权益证明的货币。,点点币的权益证明机制结合了随机化与币龄的概念,未使用至少30天的币可以参与竞争下一区块,越久和越大的币集有更大的可能去签名下一区块。一旦币的权益被用于签名一个区块,则币龄将清为零,这样必须等待至少30日才能签署另一区块。
POS机制虽然考虑到了POW的不足,但依据权益结余来选择,会导致首富账户的权力更大,有可能支配记账权。股份授权证明机制(Delegated Proof of Stake,DPOS)的出现正是基于解决POW机制和POS机制的这类不足。

DPOS(委任权益证明)
比特股(Bitshare)是一类采用DPOS机制的密码货币。它的原理是,让每一个持有比特股的人进行投票,由此产生101位代表 , 我们可以将其理解为101个超级节点或者矿池,而这101个超级节点彼此的权利是完全相等的。如果代表不能履行他们的职责(当轮到他们时,没能生成区块),他们会被除名,网络会选出新的超级节点来取代他们。
比特股引入了见证人这个概念,见证人可以生成区块,每一个持有比特股的人都可以投票选举见证人。得到总同意票数中的前N个(N通常定义为101)候选者可以当选为见证人,当选见证人的个数(N)需满足:至少一半的参与投票者相信N已经充分地去中心化。
见证人的候选名单每个维护周期(1天)更新一次。见证人然后随机排列,每个见证人按序有2秒的权限时间生成区块,若见证人在给定的时间片不能生成区块,区块生成权限交给下一个时间片对应的见证人。
比特股还设计了另外一类竞选,代表竞选。选出的代表拥有提出改变网络参数的特权,包括交易费用、区块大小、见证人费用和区块区间。若大多数代表同意所提出的改变,持股人有两周的审查期,这期间可以罢免代表并废止所提出的改变。这一设计确保代表技术上没有直接修改参数的权利以及所有的网络参数的改变最终需得到持股人的同意。

Ripple
Ripple(瑞波)是一种基于互联网的开源支付协议,在Ripple的网络中,交易由客户端(应用)发起,经过追踪节点(tracking node)或验证节点(validating node)把交易广播到整个网络中。
追踪节点的主要功能是分发交易信息以及响应客户端的账本请求。验证节点除包含追踪节点的所有功能外,还能够通过共识协议,在账本中增加新的账本实例数据。
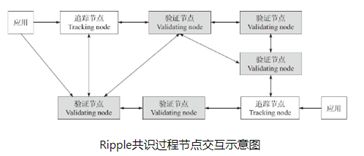
Ripple的共识达成发生在验证节点之间,每个验证节点都预先配置了一份可信任节点名单,称为UNL(Unique Node List)。在名单上的节点可对交易达成进行投票。每隔几秒,Ripple网络将进行如下共识过程:
1)每个验证节点会不断收到从网络发送过来的交易,通过与本地账本数据验证后,不合法的交易直接丢弃,合法的交易将汇总成交易候选集(candidate set)。交易候选集里面还包括之前共识过程无法确认而遗留下来的交易。
2)每个验证节点把自己的交易候选集作为提案发送给其他验证节点。
3)验证节点在收到其他节点发来的提案后,如果不是来自UNL上的节点,则忽略该提案;如果是来自UNL上的节点,就会对比提案中的交易和本地的交易候选集,如果有相同的交易,该交易就获得一票。在一定时间内,当交易获得超过50%的票数时,则该交易进入下一轮。没有超过50%的交易,将留待下一次共识过程去确认。
4)验证节点把超过50%票数的交易作为提案发给其他节点,同时提高所需票数的阈值到60%,重复步骤3)、步骤4),直到阈值达到80%。
5)验证节点把经过80%UNL节点确认的交易正式写入本地的账本数据中,称为最后关闭账本(Last Closed Ledger),即账本最后(最新)的状态。

在Ripple的共识算法中,参与投票节点的身份是事先知道的。该共识算法只适合于权限链(Permissionedchain)的场景。Ripple共识算法的拜占庭容错(BFT)能力为(n-1)/5,即可以容忍整个网络中20%的节点出现拜占庭错误而不影响正确的共识。
在区块链网络中,由于应用场景的不同,所设计的目标各异,不同的区块链系统采用了不同的共识算法。一般来说,在私有链和联盟链情况下,对一致性、正确性有很强的要求。一般来说要采用强一致性的共识算法。而在公有链情况下,对一致性和正确性通常没法做到百分之百,通常采用最终一致性(Eventual Consistency)的共识算法。
共识算法的选择与应用场景高度相关,可信环境使用paxos 或者raft,带许可的联盟可使用pbft ,非许可链可以是pow,pos,ripple共识等,根据对手方信任度分级,自由选择共识机制。

版权声明:本文为CSDN博主「日月ton光」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/sinat_36711025/article/details/104837558

推荐阅读
从特斯拉CEO到推特CEO ,细数这9位持有比特币的顶级富豪
斗地主吗?能学区块链那种! | 原力计划
《哈利波特》作者J.K.罗琳求科普比特币,V神、马斯克积极响应,1500万粉丝围观
国产数据库 OceanBase 二次刷榜 TPC-C,7 亿 tpmC!
腾讯人均月薪 8 万,恍恍惚惚,又被平均了?
一文带你彻底搞懂什么是「缓存」!
出任 Twitter 独立董事,AI 女神李飞飞的传奇人生
老铁们在看签个到!