from Tools.Plot import plot_confusion_matrix,macro_roc
from sklearn.metrics import classification_report,confusion_matrix,log_loss,auc
from sklearn.preprocessing import (
MinMaxScaler, label_binarize, OneHotEncoder, LabelEncoder)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import StratifiedKFold, GridSearchCV,train_test_split
from sklearn.ensemble import GradientBoostingClassifier,RandomForestClassifier,AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from itertools import cycle, product
import datetime
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from itertools import cycle
import seaborn as sns
import warnings
from tqdm import tqdm_notebook
warnings.filterwarnings('ignore')
%matplotlib inline
RawData
##################### 加载数据 ##########################
train = pd.read_csv('data/train_all.csv')
test = pd.read_csv('data/test_all.csv')
# label encoding
label_dict = {'Normal': 0,
'Probe': 1,
'DoS': 2,
'U2R': 3,
'R2L': 4}
X_train = train.drop(['label_num'],axis=1)
X_test = test.drop(['label_num'],axis=1)
y_train = train['label_num']
y_test = test['label_num']
print('Shape of training set:', X_train.shape)
print('Shape of testing set:', X_test.shape)
# print('Columns: \n', list(X_train.columns))
labels = [key for i in sorted(label_dict.values()) for key,val in label_dict.items() if val==i]
labels_number = sorted(label_dict.values()) # [0, 1, 2, 3, 4]
train_set_dict = {}
train_set_dict['RawData'] = (X_train,y_train)
Shape of training set: (125973, 15)
Shape of testing set: (22544, 15)
train.label_num.value_counts()
0 67343
2 45927
1 11656
4 995
3 52
Name: label_num, dtype: int64
Over-sampling
RandomOverSample
# 简单的复制样本
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0,return_indices=True)
X_resampled ,y_resampled,indx= ros.fit_resample(X_train,y_train)
from collections import Counter
print(sorted(Counter(y_resampled).items()))
train_set_dict['RandomOverSampler'] = (X_resampled ,y_resampled)
[(0, 67343), (1, 67343), (2, 67343), (3, 67343), (4, 67343)]
SMOTE
from imblearn.over_sampling import SMOTE, ADASYN
X_resampled, y_resampled = SMOTE().fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['SMOTE'] = (X_resampled ,y_resampled)
[(0, 67343), (1, 67343), (2, 67343), (3, 67343), (4, 67343)]
ADASYN
from imblearn.over_sampling import SMOTE, ADASYN
X_resampled, y_resampled = ADASYN().fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['ADASYN'] = (X_resampled ,y_resampled)
[(0, 67343), (1, 67348), (2, 67312), (3, 67344), (4, 67304)]
BorderlineSMOTE
from imblearn.over_sampling import BorderlineSMOTE
X_resampled, y_resampled = BorderlineSMOTE(kind='borderline-1').fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['BorderlineSMOTE-1'] = (X_resampled ,y_resampled)
[(0, 67343), (1, 67343), (2, 67343), (3, 67343), (4, 67343)]
from imblearn.over_sampling import BorderlineSMOTE
X_resampled, y_resampled = BorderlineSMOTE(kind='borderline-2').fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['BorderlineSMOTE-2'] = (X_resampled ,y_resampled)
[(0, 67343), (1, 67343), (2, 67342), (3, 67342), (4, 67342)]
Under-sampling
ClusterCentroids
from imblearn.under_sampling import ClusterCentroids
cc = ClusterCentroids(random_state=0)
X_resampled, y_resampled = cc.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['ClusterCentroids'] = (X_resampled ,y_resampled)
[(0, 52), (1, 52), (2, 52), (3, 52), (4, 52)]
RandomUnderSampler
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_resampled, y_resampled = rus.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['RandomUnderSampler'] = (X_resampled ,y_resampled)
[(0, 52), (1, 52), (2, 52), (3, 52), (4, 52)]
NearMiss
from imblearn.under_sampling import NearMiss
nm1 = NearMiss(version=1)
X_resampled_nm1, y_resampled = nm1.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['NearMiss-1'] = (X_resampled ,y_resampled)
[(0, 52), (1, 52), (2, 52), (3, 52), (4, 52)]
from imblearn.under_sampling import NearMiss
nm1 = NearMiss(version=2)
X_resampled_nm1, y_resampled = nm1.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['NearMiss-2'] = (X_resampled ,y_resampled)
[(0, 52), (1, 52), (2, 52), (3, 52), (4, 52)]
# from imblearn.under_sampling import NearMiss
# nm1 = NearMiss(version=3)
# X_resampled_nm1, y_resampled = nm1.fit_resample(X_train, y_train)
# print(sorted(Counter(y_resampled).items()))
# train_set_dict['NearMiss-3'] = (X_resampled ,y_resampled)
EditedNearestNeighbours
from imblearn.under_sampling import EditedNearestNeighbours
enn = EditedNearestNeighbours()
X_resampled, y_resampled = enn.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['EditedNearestNeighbours'] = (X_resampled ,y_resampled)
[(0, 66485), (1, 11314), (2, 45818), (3, 52), (4, 898)]
RepeatedEditedNearestNeighbours
from imblearn.under_sampling import RepeatedEditedNearestNeighbours
renn = RepeatedEditedNearestNeighbours()
X_resampled, y_resampled = renn.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['RepeatedEditedNearestNeighbours'] = (X_resampled ,y_resampled)
[(0, 66419), (1, 11256), (2, 45806), (3, 52), (4, 898)]
AllKNN
from imblearn.under_sampling import AllKNN
allknn = AllKNN()
X_resampled, y_resampled = allknn.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['AllKNN'] = (X_resampled ,y_resampled)
[(0, 66695), (1, 11360), (2, 45808), (3, 52), (4, 902)]
CondensedNearestNeighbour
from imblearn.under_sampling import CondensedNearestNeighbour
cnn = CondensedNearestNeighbour(random_state=0)
X_resampled, y_resampled = cnn.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['CondensedNearestNeighbour'] = (X_resampled ,y_resampled)
[(0, 139), (1, 43), (2, 20), (3, 52), (4, 33)]
OneSidedSelection
from imblearn.under_sampling import OneSidedSelection
oss = OneSidedSelection(random_state=0)
X_resampled, y_resampled = oss.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['OneSidedSelection'] = (X_resampled ,y_resampled)
[(0, 29210), (1, 8530), (2, 11655), (3, 52), (4, 713)]
NeighbourhoodCleaningRule
from imblearn.under_sampling import NeighbourhoodCleaningRule
ncr = NeighbourhoodCleaningRule()
X_resampled, y_resampled = ncr.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['NeighbourhoodCleaningRule'] = (X_resampled ,y_resampled)
[(0, 66968), (1, 11470), (2, 45859), (3, 52), (4, 909)]
InstanceHardnessThreshold
from sklearn.linear_model import LogisticRegression
from imblearn.under_sampling import InstanceHardnessThreshold
iht = InstanceHardnessThreshold(random_state=0,
estimator=LogisticRegression(
solver='lbfgs', multi_class='auto'))
X_resampled, y_resampled = iht.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['InstanceHardnessThreshold'] = (X_resampled ,y_resampled)
[(0, 62), (1, 52), (2, 52), (3, 52), (4, 52)]
Over- and under-sampling
SMOTEENN
from imblearn.combine import SMOTEENN
smote_enn = SMOTEENN(random_state=0)
X_resampled, y_resampled = smote_enn.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['SMOTEENN'] = (X_resampled ,y_resampled)
[(0, 66114), (1, 67013), (2, 67212), (3, 67194), (4, 66959)]
SMOTETomek
from imblearn.combine import SMOTETomek
smote_tomek = SMOTETomek(random_state=0)
X_resampled, y_resampled = smote_tomek.fit_resample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
train_set_dict['SMOTETomek'] = (X_resampled ,y_resampled)
[(0, 67231), (1, 67289), (2, 67323), (3, 67323), (4, 67289)]
Bagging
Bagging
print(sorted(Counter(y_train).items()))
train_set_dict['Bagging'] = (X_train ,y_train)
[(0, 67343), (1, 11656), (2, 45927), (3, 52), (4, 995)]
BalancedBagging
print(sorted(Counter(y_train).items()))
train_set_dict['BalancedBagging'] = (X_train ,y_train)
[(0, 67343), (1, 11656), (2, 45927), (3, 52), (4, 995)]
BalancedRandomForest
print(sorted(Counter(y_train).items()))
train_set_dict['BalancedRandomForest'] = (X_train ,y_train)
[(0, 67343), (1, 11656), (2, 45927), (3, 52), (4, 995)]
Boosting
RUSBoost
print(sorted(Counter(y_train).items()))
train_set_dict['RUSBoost'] = (X_train ,y_train)
[(0, 67343), (1, 11656), (2, 45927), (3, 52), (4, 995)]
EasyEnsemble
print(sorted(Counter(y_train).items()))
train_set_dict['EasyEnsemble'] = (X_train ,y_train)
[(0, 67343), (1, 11656), (2, 45927), (3, 52), (4, 995)]
评估
from sklearn.svm import LinearSVC
from imblearn.metrics import classification_report_imbalanced
from sklearn.ensemble import RandomForestClassifier
################### train #####################################
plt.figure(figsize=(12, 6))
cm = []
clf_report_list = []
for name, (X, y) in tqdm_notebook(list(train_set_dict.items())):
RANDOM_STATE = 2019
if name in ['Bagging']:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
clf = BaggingClassifier(base_estimator=DecisionTreeClassifier(),
random_state=0)
elif name in ['BalancedBagging']:
from imblearn.ensemble import BalancedBaggingClassifier
clf = BalancedBaggingClassifier(base_estimator=DecisionTreeClassifier(),
sampling_strategy='auto',
replacement=False,
random_state=0)
elif name in ['BalancedRandomForest']:
from imblearn.ensemble import BalancedRandomForestClassifier
clf = BalancedRandomForestClassifier(n_estimators=100, random_state=0)
elif name in ['RUSBoost']:
from imblearn.ensemble import RUSBoostClassifier
clf = RUSBoostClassifier(random_state=0)
elif name in ['EasyEnsemble']:
from imblearn.ensemble import EasyEnsembleClassifier
clf = EasyEnsembleClassifier(random_state=0)
else:
# 模型
clf = RandomForestClassifier(n_estimators=161,
max_depth=49,
max_features="sqrt",
random_state=RANDOM_STATE)
clf.fit(X, y)
y_test_pred = clf.predict(X_test)
y_test_score = clf.predict_proba(X_test) # valid score
######################### 测试集评估 ########################
# 分类报告
clf_report = classification_report_imbalanced(
y_test, y_test_pred, digits=4, target_names=labels)
clf_report_list.append(clf_report)
# 混淆矩阵
cnf_matrix = confusion_matrix(y_test, y_test_pred)
cm.append((name, cnf_matrix))
# ROC
all_fpr, mean_tpr = macro_roc(
y_test, y_test_score, labels_number)
roc_auc = auc(all_fpr, mean_tpr)
sns.set_style('darkgrid')
# plt.figure(figsize=(5,4))
plt.plot(all_fpr, mean_tpr, lw=1,
label='{0} (auc = {1:0.4f})'.format(name, roc_auc))
plt.plot([0, 1], [0, 1], 'k--', lw=1)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.01])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.legend(loc=(1.1, 0))
plt.tight_layout()
plt.show()
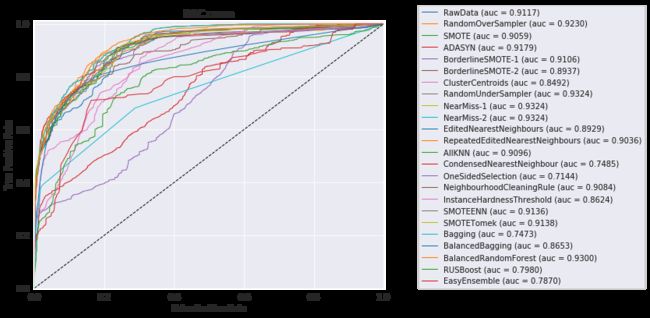
output_55_2.png
sns.set_style('white')
fig,axes = plt.subplots(6,4,figsize=(20,20))
for ax,(name,cnf_matrix) in zip(axes.ravel(),cm):
plot_confusion_matrix(cnf_matrix, labels,ax=ax,
normalize=True,
title=name,
cmap=plt.cm.Blues)
plt.tight_layout()
plt.show()

output_56_0.png
for clf_report,name in zip(clf_report_list,train_set_dict.keys()):
print(name,'\n',clf_report)
RawData
pre rec spe f1 geo iba sup
Normal 0.6489 0.9712 0.6024 0.7780 0.7648 0.6066 9711
Probe 0.8700 0.5808 0.9896 0.6966 0.7581 0.5512 2421
DoS 0.9616 0.7995 0.9842 0.8731 0.8871 0.7724 7458
U2R 0.8000 0.0200 1.0000 0.0390 0.1414 0.0180 200
R2L 0.8936 0.0610 0.9990 0.1142 0.2469 0.0552 2754
avg / total 0.8073 0.7528 0.8222 0.7131 0.7358 0.5829 22544
RandomOverSampler
pre rec spe f1 geo iba sup
Normal 0.6482 0.9683 0.6023 0.7765 0.7637 0.6045 9711
Probe 0.8523 0.5865 0.9878 0.6949 0.7612 0.5561 2421
DoS 0.9615 0.7900 0.9844 0.8674 0.8819 0.7626 7458
U2R 0.2143 0.0300 0.9990 0.0526 0.1731 0.0271 200
R2L 0.8930 0.0697 0.9988 0.1293 0.2639 0.0632 2754
avg / total 0.7998 0.7502 0.8220 0.7123 0.7362 0.5803 22544
SMOTE
pre rec spe f1 geo iba sup
Normal 0.6606 0.9679 0.6238 0.7853 0.7770 0.6245 9711
Probe 0.8471 0.5857 0.9873 0.6926 0.7604 0.5550 2421
DoS 0.9620 0.8081 0.9842 0.8784 0.8918 0.7814 7458
U2R 0.1818 0.0500 0.9980 0.0784 0.2234 0.0452 200
R2L 0.9102 0.1068 0.9985 0.1911 0.3265 0.0971 2754
avg / total 0.8066 0.7606 0.8312 0.7273 0.7533 0.5994 22544
ADASYN
pre rec spe f1 geo iba sup
Normal 0.6537 0.9683 0.6118 0.7805 0.7697 0.6135 9711
Probe 0.8411 0.5989 0.9864 0.6996 0.7686 0.5679 2421
DoS 0.9610 0.7800 0.9844 0.8611 0.8762 0.7521 7458
U2R 0.0838 0.0750 0.9927 0.0792 0.2729 0.0676 200
R2L 0.9113 0.0672 0.9991 0.1251 0.2591 0.0609 2754
avg / total 0.8019 0.7483 0.8260 0.7122 0.7380 0.5821 22544
BorderlineSMOTE-1
pre rec spe f1 geo iba sup
Normal 0.6443 0.9700 0.5948 0.7743 0.7596 0.5986 9711
Probe 0.8586 0.5869 0.9884 0.6973 0.7617 0.5568 2421
DoS 0.9603 0.7721 0.9842 0.8560 0.8717 0.7438 7458
U2R 0.0694 0.0500 0.9940 0.0581 0.2229 0.0450 200
R2L 0.8915 0.0418 0.9993 0.0798 0.2043 0.0377 2754
avg / total 0.7970 0.7418 0.8188 0.7019 0.7243 0.5687 22544
BorderlineSMOTE-2
pre rec spe f1 geo iba sup
Normal 0.6613 0.9694 0.6243 0.7863 0.7780 0.6261 9711
Probe 0.8431 0.6258 0.9860 0.7183 0.7855 0.5948 2421
DoS 0.9623 0.8018 0.9845 0.8748 0.8885 0.7750 7458
U2R 0.0694 0.0500 0.9940 0.0581 0.2229 0.0450 200
R2L 0.8961 0.0501 0.9992 0.0949 0.2238 0.0453 2754
avg / total 0.8039 0.7566 0.8314 0.7173 0.7427 0.5959 22544
ClusterCentroids
pre rec spe f1 geo iba sup
Normal 0.6393 0.3194 0.8636 0.4260 0.5252 0.2609 9711
Probe 0.6794 0.4936 0.9720 0.5718 0.6926 0.4568 2421
DoS 0.9756 0.6652 0.9918 0.7910 0.8122 0.6382 7458
U2R 0.0175 0.7250 0.6356 0.0342 0.6788 0.4649 200
R2L 0.2496 0.2320 0.9029 0.2405 0.4577 0.1954 2754
avg / total 0.7018 0.4454 0.9204 0.5363 0.6313 0.4005 22544
RandomUnderSampler
pre rec spe f1 geo iba sup
Normal 0.6559 0.9543 0.6211 0.7774 0.7699 0.6125 9711
Probe 0.8116 0.6316 0.9824 0.7103 0.7877 0.5987 2421
DoS 0.9697 0.7212 0.9889 0.8272 0.8445 0.6941 7458
U2R 0.1129 0.4200 0.9705 0.1780 0.6384 0.3852 200
R2L 0.6458 0.0563 0.9957 0.1035 0.2367 0.0508 2754
avg / total 0.7704 0.7281 0.8304 0.6991 0.7302 0.5674 22544
NearMiss-1
pre rec spe f1 geo iba sup
Normal 0.6559 0.9543 0.6211 0.7774 0.7699 0.6125 9711
Probe 0.8116 0.6316 0.9824 0.7103 0.7877 0.5987 2421
DoS 0.9697 0.7212 0.9889 0.8272 0.8445 0.6941 7458
U2R 0.1129 0.4200 0.9705 0.1780 0.6384 0.3852 200
R2L 0.6458 0.0563 0.9957 0.1035 0.2367 0.0508 2754
avg / total 0.7704 0.7281 0.8304 0.6991 0.7302 0.5674 22544
NearMiss-2
pre rec spe f1 geo iba sup
Normal 0.6559 0.9543 0.6211 0.7774 0.7699 0.6125 9711
Probe 0.8116 0.6316 0.9824 0.7103 0.7877 0.5987 2421
DoS 0.9697 0.7212 0.9889 0.8272 0.8445 0.6941 7458
U2R 0.1129 0.4200 0.9705 0.1780 0.6384 0.3852 200
R2L 0.6458 0.0563 0.9957 0.1035 0.2367 0.0508 2754
avg / total 0.7704 0.7281 0.8304 0.6991 0.7302 0.5674 22544
EditedNearestNeighbours
pre rec spe f1 geo iba sup
Normal 0.6375 0.9712 0.5821 0.7697 0.7519 0.5873 9711
Probe 0.8703 0.5820 0.9896 0.6975 0.7589 0.5524 2421
DoS 0.9608 0.7664 0.9846 0.8527 0.8687 0.7381 7458
U2R 0.5000 0.0200 0.9998 0.0385 0.1414 0.0180 200
R2L 0.9023 0.0570 0.9991 0.1072 0.2387 0.0516 2754
avg / total 0.8006 0.7415 0.8136 0.7020 0.7232 0.5630 22544
RepeatedEditedNearestNeighbours
pre rec spe f1 geo iba sup
Normal 0.6395 0.9708 0.5859 0.7711 0.7542 0.5907 9711
Probe 0.8699 0.5799 0.9896 0.6959 0.7575 0.5504 2421
DoS 0.9603 0.7723 0.9842 0.8561 0.8719 0.7440 7458
U2R 0.4444 0.0200 0.9998 0.0383 0.1414 0.0180 200
R2L 0.9066 0.0599 0.9991 0.1124 0.2447 0.0542 2754
avg / total 0.8013 0.7434 0.8152 0.7042 0.7258 0.5665 22544
AllKNN
pre rec spe f1 geo iba sup
Normal 0.6394 0.9712 0.5855 0.7711 0.7541 0.5906 9711
Probe 0.8719 0.5849 0.9897 0.7001 0.7608 0.5554 2421
DoS 0.9609 0.7706 0.9845 0.8553 0.8710 0.7424 7458
U2R 0.4444 0.0200 0.9998 0.0383 0.1414 0.0180 200
R2L 0.8944 0.0585 0.9990 0.1097 0.2417 0.0529 2754
avg / total 0.8001 0.7434 0.8151 0.7040 0.7254 0.5663 22544
CondensedNearestNeighbour
pre rec spe f1 geo iba sup
Normal 0.5797 0.7469 0.5902 0.6527 0.6639 0.4477 9711
Probe 0.7732 0.5324 0.9812 0.6306 0.7228 0.4990 2421
DoS 0.8747 0.7675 0.9456 0.8176 0.8519 0.7129 7458
U2R 0.0036 0.0300 0.9252 0.0064 0.1666 0.0253 200
R2L 0.7972 0.0414 0.9985 0.0787 0.2033 0.0374 2754
avg / total 0.7195 0.6381 0.8026 0.6290 0.6718 0.4871 22544
OneSidedSelection
pre rec spe f1 geo iba sup
Normal 0.5274 0.6492 0.5597 0.5820 0.6028 0.3666 9711
Probe 0.8380 0.5514 0.9872 0.6652 0.7378 0.5206 2421
DoS 0.6400 0.7647 0.7874 0.6968 0.7759 0.6007 7458
U2R 0.6667 0.0200 0.9999 0.0388 0.1414 0.0180 200
R2L 0.8250 0.0240 0.9993 0.0466 0.1548 0.0216 2754
avg / total 0.6356 0.5949 0.7385 0.5587 0.6157 0.4154 22544
NeighbourhoodCleaningRule
pre rec spe f1 geo iba sup
Normal 0.6363 0.9712 0.5800 0.7689 0.7505 0.5853 9711
Probe 0.8666 0.5795 0.9893 0.6946 0.7572 0.5498 2421
DoS 0.9605 0.7624 0.9845 0.8501 0.8664 0.7339 7458
U2R 0.5000 0.0200 0.9998 0.0385 0.1414 0.0180 200
R2L 0.8920 0.0570 0.9990 0.1072 0.2386 0.0516 2754
avg / total 0.7983 0.7399 0.8127 0.7004 0.7216 0.5604 22544
InstanceHardnessThreshold
pre rec spe f1 geo iba sup
Normal 0.8535 0.6872 0.9108 0.7614 0.7911 0.6119 9711
Probe 0.3513 0.5316 0.8819 0.4230 0.6847 0.4524 2421
DoS 0.9386 0.1947 0.9937 0.3225 0.4398 0.1780 7458
U2R 0.0224 0.9800 0.6177 0.0439 0.7780 0.6273 200
R2L 0.2162 0.0610 0.9692 0.0952 0.2432 0.0538 2754
avg / total 0.7425 0.4336 0.9396 0.4921 0.5964 0.3832 22544
SMOTEENN
pre rec spe f1 geo iba sup
Normal 0.6473 0.9682 0.6008 0.7759 0.7627 0.6030 9711
Probe 0.8378 0.5890 0.9863 0.6917 0.7622 0.5579 2421
DoS 0.9634 0.7654 0.9856 0.8530 0.8685 0.7377 7458
U2R 0.2188 0.0700 0.9978 0.1061 0.2643 0.0634 200
R2L 0.8841 0.1053 0.9981 0.1882 0.3242 0.0957 2754
avg / total 0.7975 0.7470 0.8216 0.7146 0.7397 0.5760 22544
SMOTETomek
pre rec spe f1 geo iba sup
Normal 0.6505 0.9681 0.6063 0.7781 0.7661 0.6082 9711
Probe 0.8449 0.5849 0.9871 0.6912 0.7598 0.5541 2421
DoS 0.9610 0.7761 0.9844 0.8587 0.8741 0.7481 7458
U2R 0.2034 0.0600 0.9979 0.0927 0.2447 0.0543 200
R2L 0.9159 0.1107 0.9986 0.1976 0.3326 0.1008 2754
avg / total 0.8025 0.7506 0.8237 0.7184 0.7436 0.5818 22544
Bagging
pre rec spe f1 geo iba sup
Normal 0.6558 0.9707 0.6145 0.7828 0.7723 0.6177 9711
Probe 0.8632 0.5993 0.9886 0.7075 0.7697 0.5694 2421
DoS 0.9640 0.8013 0.9852 0.8752 0.8885 0.7749 7458
U2R 0.5000 0.0200 0.9998 0.0385 0.1414 0.0180 200
R2L 0.9046 0.0930 0.9986 0.1686 0.3047 0.0844 2754
avg / total 0.8091 0.7591 0.8277 0.7236 0.7478 0.5941 22544
BalancedBagging
pre rec spe f1 geo iba sup
Normal 0.6632 0.9445 0.6370 0.7792 0.7757 0.6202 9711
Probe 0.7238 0.6105 0.9720 0.6623 0.7703 0.5719 2421
DoS 0.9530 0.7224 0.9824 0.8218 0.8424 0.6913 7458
U2R 0.1089 0.4150 0.9696 0.1726 0.6343 0.3801 200
R2L 0.6445 0.0599 0.9954 0.1096 0.2442 0.0541 2754
avg / total 0.7584 0.7224 0.8340 0.6936 0.7310 0.5672 22544
BalancedRandomForest
pre rec spe f1 geo iba sup
Normal 0.6765 0.9377 0.6606 0.7859 0.7871 0.6366 9711
Probe 0.7515 0.7084 0.9718 0.7293 0.8297 0.6703 2421
DoS 0.9683 0.6912 0.9888 0.8066 0.8267 0.6631 7458
U2R 0.1284 0.4950 0.9699 0.2039 0.6929 0.4573 200
R2L 0.6671 0.1710 0.9881 0.2723 0.4111 0.1552 2754
avg / total 0.7751 0.7339 0.8454 0.7188 0.7580 0.5886 22544
RUSBoost
pre rec spe f1 geo iba sup
Normal 0.5100 0.8751 0.3637 0.6444 0.5641 0.3345 9711
Probe 0.2858 0.3073 0.9076 0.2962 0.5281 0.2622 2421
DoS 0.9864 0.2241 0.9985 0.3652 0.4730 0.2064 7458
U2R 0.0359 0.0450 0.9892 0.0399 0.2110 0.0403 200
R2L 0.5165 0.2498 0.9675 0.3368 0.4916 0.2243 2754
avg / total 0.6401 0.5150 0.7114 0.4717 0.5181 0.2683 22544
EasyEnsemble
pre rec spe f1 geo iba sup
Normal 0.7402 0.8738 0.7679 0.8015 0.8191 0.6781 9711
Probe 0.2319 0.3792 0.8489 0.2878 0.5674 0.3068 2421
DoS 0.7588 0.3623 0.9431 0.4904 0.5845 0.3218 7458
U2R 0.0578 0.5550 0.9191 0.1048 0.7142 0.4915 200
R2L 0.4072 0.2429 0.9508 0.3043 0.4806 0.2146 2754
avg / total 0.6450 0.5715 0.8582 0.5765 0.6722 0.4621 22544