【Tensorflow2.0】4、Tensorflow2.0+Keras_快速入门教程
文章目录
- Tensorflow2.0+Keras综述
- Tensorflow2.0是Tensorflow1.x和Keras的组合设计,考虑了四年来的用户反馈和框架发展,很大程度上解决了上述问题,将成为未来的机器学习平台。
- 第一部分:Tensorflow基础
- Tensors张量
- 随机数常量[random constant正态分布](https://www.tensorflow.org/api_docs/python/tf/random/normal)
- 2.3 Variables变量
- Tensorflow数学运算
- `GradientTape`计算梯度
- 一个完整的例子:linear regression 线性回归
- 接下来加速训练速度,要使用`tf.function`
- 第二部分:Keras API
- 基础类`Layer`
- Trainable and non-trainable weights可训练和不可训练参数
- 堆叠网络层
- 内建层
- `call`方法中的`training`参数
- 函数式编程
- 损失函数类
- 评估指标类 metric class
- 优化类与一个完整的训练
- `add_loss`方法
- 完整示例:变分自动编码器variational autoencoder(VAE)
- 使用内建的循环
- 回调Callbacks
- 综述
- 下一步
本文是学习keras作者关于 tensorflow2.0的教程
#安装tensorflow
!pip install tensorflow==2.0.0
import tensorflow as tf
print(tf.__version__)
2.0.0
Tensorflow2.0+Keras综述
作者:fchollet,2019年10月
本文是关于Tensorflow2.0 API的简要介绍课程
Tensorflow2.0和Keras都已经发布有四年之久(2015年3月Keras发布,同年11月Tensorflow发布)。在过去的日子里深度学习得到的迅速发展,同时我们也知道
Tensorflow1.x和Keras的一些问题:
- 使用Tensorflow意味着要对静态图进行编程,对于熟悉命令式编程的程序比较难而且不方便
- Tensorflow api功能强大并且灵活,但是比较复杂容易混乱,难以使用
- Keras api 生产力高并且易用,但是缺乏用于研究的灵活性
Tensorflow2.0是Tensorflow1.x和Keras的组合设计,考虑了四年来的用户反馈和框架发展,很大程度上解决了上述问题,将成为未来的机器学习平台。
Tensorflow2.0构建在以下的核心思想之上:
- 编码更加pythonic,使有户像在用numpy编程一样,能立即获得结果
- 保留了静态图的特性(为了性能、分布式和生产布署),这使TensorFlow快速,可扩展且可投入生产。
- 使用Keras作为深度学习的高级api,使得Tensorflow变得易用高效
- 使整个框架兼有高级特性(易用,高效,不够灵活)和低级特性(功能强大可扩展,不易使用,但非常灵活)
第一部分:Tensorflow基础
Tensors张量
常量constant:
x = tf.constant([[4,2],[9,5]])
print(x)
tf.Tensor(
[[4 2]
[9 5]], shape=(2, 2), dtype=int32)
可以通过“.numpy()”来得到numpy array类型
x.numpy()
array([[4, 2],
[9, 5]], dtype=int32)
像numpy一样,有shape和dtype属性
print('shape:',x.shape)
print('dx.dtype)
(2, 2)
常用的产生常量的方法是tf.ones和tf.zeros就像numpy的np.ones``np.zeros
print(tf.ones(shape=(2,3)))
print(tf.zeros(shape=(3,2)))
tf.Tensor(
[[1. 1. 1.]
[1. 1. 1.]], shape=(2, 3), dtype=float32)
tf.Tensor(
[[0. 0.]
[0. 0.]
[0. 0.]], shape=(3, 2), dtype=float32)
随机数常量random constant正态分布
tf.random.normal(shape=(2,2),mean=0,stddev=1.0)
#整数均匀分布
tf.random.uniform(shape=(2,2),minval=0,maxval=10,dtype=tf.int32)
2.3 Variables变量
变量是一种特别的张量,用来存储可变数值,需要用一些值来初始化
initial_value = tf.random.normal(shape=(2,2))
a = tf.Variable(initial_value)
print(a)
可以通过assign(value)来赋值“=”,或assign_add(value)“+=”,或assign_sub(value)“-=”
new_value = tf.random.normal(shape=(2, 2))
a.assign(new_value)
for i in range(2):
for j in range(2):
assert a[i, j] == new_value[i, j]
added_value = tf.random.normal(shape=(2,2))
a.assign_add(added_value)
for i in range(2):
for j in range(2):
assert a[i,j] == new_value[i,j]+added_value[i,j]
Tensorflow数学运算
可以像numpy那样做作运算,Tensorflow的不同时这些运算可以放到GPU或TPU上执行
a = tf.random.normal(shape=(2,2))
b = tf.random.normal(shape=(2,2))
c = a+b
d = tf.square(c)
e = tf.exp(c)
print(a)
print(b)
print(c)
print(d)
print(e)
tf.Tensor(
[[ 1.6862711 -1.4246397]
[-1.0287055 -1.3188182]], shape=(2, 2), dtype=float32)
tf.Tensor(
[[ 1.4519434 0.7635907]
[ 1.1213834 -1.4559215]], shape=(2, 2), dtype=float32)
tf.Tensor(
[[ 3.1382146 -0.661049 ]
[ 0.09267795 -2.7747397 ]], shape=(2, 2), dtype=float32)
tf.Tensor(
[[9.8483906e+00 4.3698579e-01]
[8.5892025e-03 7.6991806e+00]], shape=(2, 2), dtype=float32)
tf.Tensor(
[[23.062654 0.51630944]
[ 1.0971084 0.0623657 ]], shape=(2, 2), dtype=float32)
GradientTape计算梯度
和numpy的另一个不同是,可以自动跟踪任何变量的梯度。
打开一个GradientTape,然后通过tape.watch()来跟踪变量
a = tf.random.normal(shape=(2,2))
b = tf.random.normal(shape=(2,2))
with tf.GradientTape() as tape:
tape.watch(a)#开始记录所有有关a参与过的运算
c = tf.sqrt(tf.square(a)+tf.square(b)) #变量a做一些运算
#计算c对于a的梯度
dc_da = tape.gradient(c,a)
print(dc_da)
tf.Tensor(
[[-0.53557533 0.87920487]
[ 0.24663754 0.4680054 ]], shape=(2, 2), dtype=float32)
对于所有变量,默认状态下会跟踪计算并用来求梯度,所以不用使用tape.watch()
a = tf.Variable(a)
with tf.GradientTape() as tape:
c = tf.sqrt(tf.square(a)+tf.square(b))
dc_da = tape.gradient(c,a)
print(dc_da)
tf.Tensor(
[[-0.53557533 0.87920487]
[ 0.24663754 0.4680054 ]], shape=(2, 2), dtype=float32)
可以通过多开几个GradientTape来求高阶导数:
with tf.GradientTape() as outer_tape:
with tf.GradientTape() as tape:
c = tf.sqrt(tf.square(a)+tf.square(b))
dc_da = tape.gradient(c,a)
d2c_d2a = outer_tape.gradient(dc_da,a)
print(d2c_d2a)
tf.Tensor(
[[0.54411626 0.33872807]
[1.5284648 0.5024241 ]], shape=(2, 2), dtype=float32)
一个完整的例子:linear regression 线性回归
到目前已经讲了像numpy一样的运算方式,但可在GPU或TPU上加速,并且会求梯度。下面展示一个完整的示例:线性回归。
为了演示,不会使用有知keras的高级api(Layer 或MeanSquaredError),仅使用最基本运算:
input_dim=2
output_dim=1
learning_rate = 0.01
#weight matrix
w=tf.Variable(tf.random.normal(shape=(input_dim,output_dim)))
#bias
b=tf.Variable(tf.random.normal(shape=(output_dim,)))
def compute_predictions(features):
return tf.matmul(features,w)+b
def compute_loss(labels,predictions):
return tf.reduce_mean(tf.square(labels-predictions))
def train_on_batch(x,y):
with tf.GradientTape() as tape:
predictions = compute_predictions(x)
loss = compute_loss(y,predictions)
#tape.gradient对于多个变量求梯度也是可以的
dloss_w,dloss_b=tape.gradient(loss,[w,b])
w.assign_sub(learning_rate*dloss_w)
b.assign_sub(learning_rate*dloss_b)
return loss
生成一些假数据来展示我们的线性回归算法
import numpy as np
import random
import matplotlib.pyplot as plt
%matplotlib inline
#准备数据
num_samples=10000
negative_samples = np.random.multivariate_normal(mean=[0,3],cov=[[1,0.5],[0.5,1]],size=num_samples)
print('negative_samples.shape',negative_samples.shape)
positive_samples = np.random.multivariate_normal(mean=[3,0],cov=[[1,0.5],[0.5,1]],size=num_samples)
print('positive_sample.shape',positive_samples.shape)
features = np.vstack((negative_samples,positive_samples)).astype(np.float32)
print("features.shape",features.shape)
labels = np.vstack((np.zeros((num_samples,1),dtype=np.float32),np.ones((num_samples,1),dtype=np.float32)))
print("labels.shape",labels.shape)
negative_samples.shape (10000, 2)
positive_sample.shape (10000, 2)
features.shape (20000, 2)
labels.shape (20000, 1)
plt.scatter(features[:,0],features[:,1],c=labels[:,0])
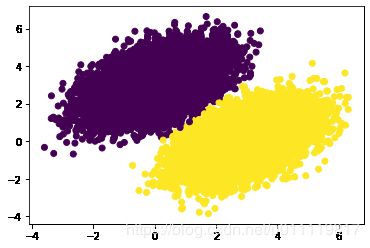
现在使用batch数据开始训练线性回归模型
#shuffle data打散数据
indices = np.random.permutation(len(features))
features = features[indices]
labels = labels[indices]
#使用tf.data来生成batch数据,方便循环使用
dataset = tf.data.Dataset.from_tensor_slices((features,labels))
dataset = dataset.shuffle(buffer_size=1024).batch(256)
#训练
for epoch in range(10):
for step,(x,y) in enumerate(dataset):
loss = train_on_batch(x,y)
print("Epoch %d: last batch loss = %.4f" %(epoch,float(loss)))
Epoch 0: last batch loss = 0.1631
Epoch 1: last batch loss = 0.1252
Epoch 2: last batch loss = 0.0770
Epoch 3: last batch loss = 0.0565
Epoch 4: last batch loss = 0.0325
Epoch 5: last batch loss = 0.0245
Epoch 6: last batch loss = 0.0470
Epoch 7: last batch loss = 0.0326
Epoch 8: last batch loss = 0.0316
Epoch 9: last batch loss = 0.0216
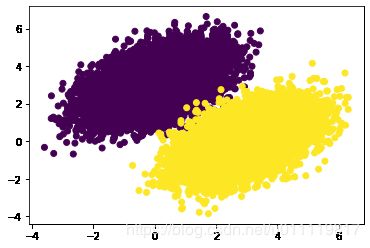
测试模型性能
predictions = compute_predictions(features)
plt.scatter(features[:,0],features[:,1],c=predictions[:,0]>0.5)
接下来加速训练速度,要使用tf.function
先计算我们现在代码的计算速度
import time
t0=time.time()
for epoch in range(20):
for step,(x,y) in enumerate(dataset):
loss = train_on_batch(x,y)
t_end = time.time()-t0
print("Time per epoch: %.3f s" %(t_end/20,))
Time per epoch: 0.145 s
将训练函数编译成静态图,只需要加上tf.function的python装饰器
@tf.function
def train_on_batch(x,y):
with tf.GradientTape() as tape:
predictions = compute_predictions(x)
loss = compute_loss(y,predictions)
dloss_w,dloss_b = tape.gradient(loss,[w,b])
w.assign_sub(learning_rate*dloss_w)
b.assign_sub(learning_rate*dloss_b)
return loss
再次使用:
t0=time.time()
for epoch in range(20):
for step,(x,y) in enumerate(dataset):
loss = train_on_batch(x,y)
t_end = time.time()-t0
print("Time per epoch: %.5f s" %(t_end/20,))
Time per epoch: 0.05802 s
大约有50%以上的提速。我们仅是使用一个小的模型,如果是真实的更大的模型,转换成静态图后,会有更大的提升。
eager模式方便debugging,并且可以对每一行实时可见结果;但如果要更快运行速度,转换成静态图会更好。
第二部分:Keras API
keras 是深度学习高级api,有以下几点需要知道:
- 对于工程师,Keras提供了现成的模块,比如layers,metrics,training loops等来支持常规的使用,易用且能产品化
- 对于研究究人员,也许并不想用内建模块,而是要用自己定义的。Keras同样提供支持,有自定义模块的模版,方便定义且与其它人交互。
- 对于库开发人员,Tensorflow是一个很大的生态系统,包含许多不同版本的库,为了不同库之间的交互,需要同样标准。
整体就是使整个框架兼备灵活性和高级api使用的便利性。
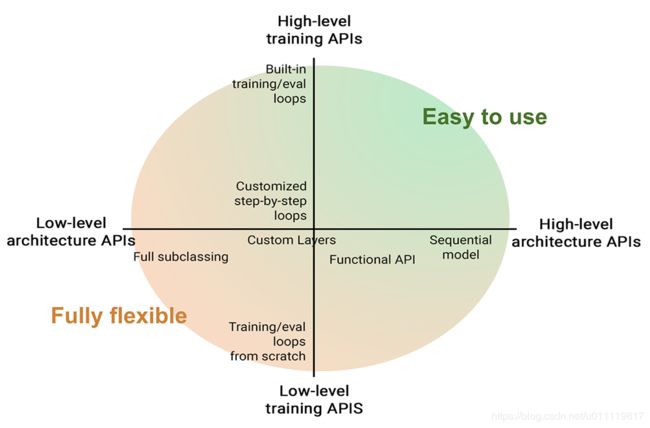
基础类Layer
第一个需要学习的类就是Layer,基本上所有的keras api是以这个类为基础的。
Layer类中封装一些状态(如权重)和计算(在call方法中定义)。
from tensorflow.keras.layers import Layer
class Linear(Layer):
"""y=wx+b"""
def __init__(self,units=32,input_dim=32):
super().__init__()
w_init=tf.random_normal_initializer()
self.w = tf.Variable(initial_value=w_init(shape=(input_dim,units),dtype=tf.float32),trainable=True)
b_init=tf.zeros_initializer()
self.b = tf.Variable(initial_value=b_init(shape=(units,),dtype=tf.float32),trainable=True)
def call(self,inputs):
return tf.matmul(inputs,self.w)+self.b
#实例化
linear_layer = Linear(4,2)
类实例化以后可以像函数一样使用
y = linear_layer(tf.ones((2, 2)))
assert y.shape == (2, 4)
Layer类将自动完成对类的跟踪更新
#所有权重都在`weights`的属性中
assert linear_layer.weights==[linear_layer.w,linear_layer.b]
linear_layer.weights
另外还有一种定义变量的快速方法,使用add_weight,对比两种方法:
w_init = tf.random_normal_initializer()
self.w = tf.Variable(initial_value=w_init(shape=shape,dtype=tf.float32))
可以快速使用:
self.w = self.add_weight(shape=shape,initializer'random_normal')
更好的定义权重方法是在一个类中的build方法中定义变量,这样做的好处是不需要指定输入数据的形状input_dim,第一层见到输入会获取到形状
from tensorflow.keras.layers import Layer
class Linear(Layer):
"""y=wx+b"""
def __init__(self,units=32):
super().__init__()
self.units = units
def build(self,input_shape):
self.w = self.add_weight(shape=(input_shape[-1],self.units),initializer=tf.random_normal_initializer(),trainable=True)
self.b = self.add_weight(shape=self.units,initializer=tf.constant_initializer(),trainable=True)
def call(self,inputs):
return tf.matmul(inputs,self.w)+self.b
#实例化
linear_layer = Linear(4)
#调用build方法并生成权重
y = linear_layer(tf.ones((2,2)))
assert len(linear_layer.weights)==2
Trainable and non-trainable weights可训练和不可训练参数
通过layer中产生的变量要么是可训练的要么是不可训练的,它们被分别放在trainable_weights和non_trainable_weights
from tensorflow.keras.layers import Layer
class ComputeSum(Layer):
"""return the sum of the inputs"""
def __init__(self,input_dim):
super().__init__()
#创建一个不可训练变量
self.total = tf.Variable(initial_value=tf.zeros(shape=(input_dim,)),trainable=False)
def call(self,inputs):
self.total.assign_add(tf.reduce_sum(inputs,axis=0))
return self.total
my_sum = ComputeSum(2)
x = tf.ones((2,2))
y = my_sum(x)
print(y.numpy())
y=my_sum(x)
print(y.numpy())
assert my_sum.weights==[my_sum.total]
assert my_sum.non_trainable_weights==[my_sum.total]
assert my_sum.trainable_weights==[]
[2. 2.]
[4. 4.]
堆叠网络层
神经网络可以通过递归堆成更大的网络,每一层可以自动更踪trainable和non-trainable weights
#再次使用Linear类,使用有build方法的那个
class MLP(Layer):
"""堆叠多个Linear层"""
def __init__(self):
super().__init__()
self.linear_1 = Linear(32)
self.linear_2 = Linear(32)
self.linear_3 = Linear(10)
def call(self,inputs):
x = self.linear_1(inputs)
x = tf.nn.relu(x)
x = self.linear_2(x)
x = tf.nn.relu(x)
x = self.linear_3(x)
return x
mlp = MLP()
#第一次调用mlp将产生变量
y = mlp(tf.ones(shape=(3,64)))
#所有变量都有跟踪记录
assert len(mlp.weights)==6
内建层
Keras内部有许多构建好的层,所以很多情况下不需要自己定义新的Layer.
- convolution layers 卷积层
- transposed convolution 逆卷积
- separateable convolution 可分离卷积
- average and max pooling 平均池化和最大值池化
- global average and max pooling全局平均和最大值池化
- LSTM,GRU(支持cuDNN加速)
- batchnormalization 批归一化
- dropout 随机舍弃
- attention 注意力机制
- convlstm2d
- etc 等
Keras 的参数配置使用常用的公开的参数,所以在大多数情况不重新定义参数而是使用默认的值,会得到较好的结果。例如LSTM初始化用正交矩阵,遗忘门使用偏置1。
call方法中的training参数
有一些层,特别是BatchNormalization和Dropout,在训练和推理阶段有不同的作用,需要在调用时指定training是True还是False。
from tensorflow.keras.layers import Layer
class Dropout(Layer):
def __init__(self,rate):
super().__init__()
self.rate=rate
def call(self,inputs,training=None):
if training:
return tf.nn.dropout(inputs,rate=self.rate)
return inputs
class MLPWithDropout(Layer):
def __init__(self):
super().__init__()
self.linear_1 = Linear(32)
self.dropout = Dropout(0.5)
self.linear_2 = Linear(10)
def call(self,inputs,training=None):
x = self.linear_1(inputs)
x = tf.nn.relu(x)
x = self.dropout(x,training=training)
x = self.linear_2(x)
return x
mlp = MLPWithDropout()
y_train = mlp(tf.ones((2,2)),training=True)
y_test = mlp(tf.ones((2,2)),training=False)
函数式编程
写模型并不是总要用面向对像编程的,可以使用函数的面向过程的方法,官方称之为"Functional API"
#我们可以使用`Input`来描述输入数据的形状和数据类型,形状只包括单个数据的形状,不含batch size.
#函数式编程定义每个单样本的转换,但可以调用整个batch size 的数据
inputs = tf.keras.layers.Input(shape=(16,)) # tf.kears.layers.Input与tf.keras.Input一样
x = Linear(32)(inputs)
x = Dropout(0.5)(x)
outputs=Linear(10)(x)
#`Model`可以定义模型的输入和输出
model = tf.keras.models.Model(inputs=inputs,outputs=outputs)#tf.keras.models.Model与tf.keras.Model 一样
#整个模型参数已经定义好
assert len(model.weights)==4
#调用模型
y = model(tf.ones((2,16)))
assert y.shape==(2,10)
函数式编程比面像对像对像编程更加简单,但是这种编程方式不可以处理递归的模型结构,只能用subclassing 子类方法。
二者的不同在这个博客中有解释 this blog post
更多关于函数式编程的说明参见
在搭建网络过程中,你常常将会是二者的结合使用。
对于层堆叠的模型,并且输入输出都只有一个,还可以使用Sequential序列编程
from tensorflow.keras import Sequential
# tf.keras.Sequential与tf.keras.models.Sequential是一样的
model = Sequential([Linear(32),Dropout(0.5),Linear(10)])
y = model(tf.ones((2,16)))
assert y.shape==(2,10)
损失函数类
keras 有许多内建的损失函数比如BinaryCrossentropy CategoricalCrossentropy KLDivergence等,损失没有状态,只返回损失值,工作方式如下:
bce = tf.keras.losses.BinaryCrossentropy()
y_true=[0.,0,1,1]
y_pred=[1.,1,0,0]
loss = bce(y_true,y_pred)
print("Loss:",loss.numpy())
Loss: 15.379093
评估指标类 metric class
同样,Keras内建许多评估指标,比如BinaryAccuracy AUC FalsePositives 等,评估指标有状态,需要update_state方法来获取最新结果(测试时要累积所有batchsize的结果)
m = tf.keras.metrics.AUC()
m.update_state([0,1,1,1],[0,1,0,0])
print("中间结果",m.result().numpy())
m.update_state([1,1,1,1],[0,1,1,0])
print("最终结果",m.result().numpy())
中间结果 0.6666667
最终结果 0.71428573
中间的状态结果可以用metric.reset_state来清除掉
通过Metric类,你也可以很方便的自定义自己的评估指标:
- 通过
__init__创建初始state - 通过往update_state中传入y_true和y_pred来更新state
- 通过result返回结果
- 通过reset_state清除状态
如下示例二分类TruePositive的求法
class BinaryTruePositives(tf.keras.metrics.Metric):
def __init__(self,name="binary_true_positives",**kwargs):
super().__init__(name=name,**kwargs)
self.true_positives = self.add_weight(name='tp',initializer=tf.zeros_initializer())
def update_state(self,y_true,y_pred,sample_weight=None):
y_true = tf.cast(y_true,tf.bool)
y_pred = tf.cast(y_pred,tf.bool)
values = tf.logical_and(tf.equal(y_true,True),tf.equal(y_pred,True))
values = tf.cast(values,self.dtype)
if sample_weight is not None:
sample_weight = tf.cast(sample_weight,self.dtype)
sample_weight=tf.broadcast_weights(sample_weight,values)
values = tf.multiple(values,sample_weight)
self.true_positives.assign_add(tf.reduce_sum(values))
def result(self):
return self.true_positives
def reset_states(self):
self.true_positives.assign(0)
m = BinaryTruePositives()
m.update_state([0,1,1,1],[0,1,0,0])
print("中间结果:",m.result().numpy())
m.update_state([1,1,1,1],[0,1,1,0])
print("最后结果:",m.result().numpy())
中间结果: 1.0
最后结果: 3.0
优化类与一个完整的训练
不需要像上边定义Linear层一样,自己定义优化算法。keras内建的许多比如SGD,RMSprop,Adam等。
以下为手写体识别示例,把求损失,使用评估指标和优化都统一到一起。
from tensorflow.keras import layers
#准备数据
(x_train,y_train),(x_test,y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train[:].reshape(60000,784).astype('float32')/255
dataset = tf.data.Dataset.from_tensor_slices((x_train,y_train))
dataset = dataset.shuffle(buffer_size=1024).batch(64)
#定义一个简单的模型
model = tf.keras.models.Sequential(
[
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(10)
])
#定义损失函数(实例化)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
#定义评估指标(实例化)
accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
#定义优化算法(实例化)
optimizer = tf.keras.optimizers.Adam()
#迭代训练
for step,(x,y) in enumerate(dataset):
#开启GradientTape
with tf.GradientTape() as tape:
#前向过程
logits = model(x)
#求loss
loss_value = loss(y,logits)
#求所有可训练参数的梯度
gradients = tape.gradient(loss_value,model.trainable_weights)
#更新参数
optimizer.apply_gradients(zip(gradients,model.trainable_weights))
#更新accuracy
accuracy.update_state(y,logits)
#打印日志
if step % 100 ==0:
print("step:",step)
print("Loss from lass step:%.3f" %(loss_value,))
print("Total runing accuracy so far:%.3f" %(accuracy.result()))
step: 0
Loss from lass step:2.374
Total runing accuracy so far:0.094
step: 100
Loss from lass step:0.371
Total runing accuracy so far:0.837
step: 200
Loss from lass step:0.217
Total runing accuracy so far:0.874
step: 300
Loss from lass step:0.245
Total runing accuracy so far:0.895
step: 400
Loss from lass step:0.301
Total runing accuracy so far:0.907
step: 500
Loss from lass step:0.100
Total runing accuracy so far:0.915
step: 600
Loss from lass step:0.076
Total runing accuracy so far:0.922
step: 700
Loss from lass step:0.215
Total runing accuracy so far:0.927
step: 800
Loss from lass step:0.165
Total runing accuracy so far:0.931
step: 900
Loss from lass step:0.048
Total runing accuracy so far:0.935
我从重复使用SparseCategoricalAccuracy来实现测试
x_test = x_test[:].reshape(10000,784).astype('float32')/255
test_data = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_data = test_data.batch(128)
accuracy.reset_states()
for step,(x,y) in enumerate(test_data):
logits = model(x)
accuracy.update_state(y,logits)
print("Final test accuracy: %.3f" %accuracy.result())
Final test accuracy: 0.961
add_loss方法
有时候需要脱离前向传播运算来单独计算损失,特别是正则化的损失。keras提供任何时候计算loss的能力,并用add_loss来记录。
如下,使用二范数的正则化
from tensorflow.keras.layers import Layer
class ActivityRegularization(Layer):
"""计算l2 regularization"""
def __init__(self,rate=1e-2):
super().__init__()
self.rate=rate
def call(self,inputs):
"""跟据输入,使用`add_loss`来添加regularization loss"""
self.add_loss(self.rate*tf.reduce_sum(tf.square(inputs)))
return inputs
通过add_loss填加的损失值可以能过Layer或Model的 .losses方法来获得
from tensorflow.keras import layers
class SparseMLP(Layer):
"""堆叠多个linear layer,并且加正则化"""
def __init__(self,output_dim):
super().__init__()
self.dense_1 = layers.Dense(32,activation=tf.nn.relu)
self.regularization= ActivityRegularization(1e-2)
self.dense_2 = layers.Dense(output_dim)
def call(self,inputs):
x = self.dense_1(inputs)
x = self.regularization(x)
x = self.dense_2(x)
return x
mlp = SparseMLP(1)
y=mlp(tf.ones((10,10)))
print(mlp.losses)
[]
损失值会被网络的初始层清除,而不会被累加。所以layer.losses只包含前最后一次前向运算的值。所以需要在训练循环时,将所有loss加起来,再示梯度。
# 只能得到最后一次的值
mlp = SparseMLP(1)
mlp(tf.ones((10,10)))
assert len(mlp.losses)==1
mlp(tf.ones((10,10)))
assert len(mlp.losses)==1 #并没有被累加
#以下将使用在训练有循环时对losses的处理
#prepare dataset
(x_train,y_train),_=tf.keras.datasets.mnist.load_data()
dataset = tf.data.Dataset.from_tensor_slices((x_train[:].reshape(60000,784).astype('float32')/255,y_train))
dataset.shuffle(buffer_size=1024).batch(64)
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
dataset = tf.data.Dataset.from_tensor_slices(
(x_train.reshape(60000, 784).astype('float32') / 255, y_train))
dataset = dataset.shuffle(buffer_size=1024).batch(64)
# 定义一个新的MLP
mlp = SparseMLP(10)
#losses and optimizer
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.1)
for step,(x,y) in enumerate(dataset):
with tf.GradientTape() as tape:
#前向运逄
logits = mlp(x)
#求前向运逄损失
loss = loss_fn(y,logits)
#加上正则化损失
loss += sum(mlp.losses)
#求梯度
gradients = tape.gradient(loss,mlp.trainable_weights)
#更新参数
optimizer.apply_gradients(zip(gradients,mlp.trainable_weights))
#日志
if step %100==0:
print("Loss at step %d: %.3f" %(step,loss))
Loss at step 0: 2.139
Loss at step 100: 1.972
Loss at step 200: 2.160
Loss at step 300: 2.062
Loss at step 400: 2.005
Loss at step 500: 2.081
Loss at step 600: 2.070
Loss at step 700: 1.987
Loss at step 800: 2.137
Loss at step 900: 2.003
完整示例:变分自动编码器variational autoencoder(VAE)
网址有我们到目前为止所有学习过的东西。
- Subclassing
Layer - 层的堆叠
- Loss类和Metric类
-add_loss - GradientTape
使用内建的循环
对于简单应用完全没有必要每次都自己从最底层的api写起。可以使用subclassing的子类编程方式或者Model的函数式编程或Sequential序列编程方式。
#准备数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000,784).astype('float32')/255
dataset = tf.data.Dataset.from_tensor_slices((x_train,y_train))
dataset.shuffle(buffer_size=1024)
dataset = dataset.batch(64)
#定义模型
model = tf.keras.models.Sequential([
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(10)
])
#定义损失
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
#定义优化
optimizer = tf.keras.optimizers.Adam()
使用model.compile来配置模型的优化、损失和评价方式
model.compile(optimizer=optimizer,loss=loss_fn,metrics=['accuracy'])
#然后使用fit来训练模型
model.fit(dataset,epochs=3)
Epoch 1/3
938/938 [==============================] - 3s 3ms/step - loss: 0.2345 - accuracy: 0.9308
Epoch 2/3
938/938 [==============================] - 2s 2ms/step - loss: 0.0924 - accuracy: 0.9717
Epoch 3/3
938/938 [==============================] - 2s 2ms/step - loss: 0.0580 - accuracy: 0.9823
需要注意的是,使用fit训练模型默认是使用静态图的,所以不需要使用tf.function
下面进行测试
x_test = x_test.reshape(10000,784).astype('float32')/255
test_dataset = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_dataset = test_dataset.batch(128)
loss,acc = model.evaluate(test_dataset)
print("Loss : %.3f -acc: %.3f" %(loss,acc))
79/79 [==============================] - 0s 2ms/step - loss: 0.0877 - accuracy: 0.9738
Loss : 0.088 -acc: 0.974
我们在使用fit时,可以监测训练和验证的loss和acc,而且fit中的数据可以直接是numpy的数据,不用tf.data来处理
(x_train,y_train),(x_test,y_test) = tf.keras.datasets.mnist.load_data()
x_train=x_train.reshape(60000,784).astype('float32')/255
num_val_samples=10000
x_val=x_train[-num_val_samples:]
y_val=y_train[-num_val_samples:]
x_train=x_train[:-num_val_samples]
y_train=y_train[:-num_val_samples]
#定义模型
model = tf.keras.models.Sequential([
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(10)
])
#定义损失
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
#定义优化
optimizer = tf.keras.optimizers.Adam()
#定义评价指标
accuracy=tf.keras.metrics.SparseCategoricalAccuracy()
model.compile(optimizer=optimizer,loss=loss_fn,metrics=['accuracy'])
history = model.fit(x_train,y_train,validation_data=(x_val,y_val),epochs=3,batch_size=128)
Train on 50000 samples, validate on 10000 samples
Epoch 1/3
50000/50000 [==============================] - 2s 30us/sample - loss: 0.2856 - accuracy: 0.9166 - val_loss: 0.1256 - val_accuracy: 0.9641
Epoch 2/3
50000/50000 [==============================] - 1s 19us/sample - loss: 0.1060 - accuracy: 0.9680 - val_loss: 0.1004 - val_accuracy: 0.9706
Epoch 3/3
50000/50000 [==============================] - 1s 19us/sample - loss: 0.0686 - accuracy: 0.9792 - val_loss: 0.0874 - val_accuracy: 0.9744
history.history
{'loss': [0.28559264993667605, 0.10595457391738891, 0.06859710264205933],
'accuracy': [0.91656, 0.96798, 0.9792],
'val_loss': [0.1256286082148552, 0.10038067170828581, 0.0873604137852788],
'val_accuracy': [0.9641, 0.9706, 0.9744]}
回调Callbacks
keras 的fit方法支持sample_weight和class_weight,另外支持callbacks回调,可以自定义训练和验证过程到底发生了什么。
callback是一个可以在训练不同结点调用的对像(比如每个batch结尾或epoch结尾),调用后可以执行一些操作,比如保存模型,恢复checkpoing,停止训练,修改模型参数等。
keras有大量内建的callback,比如ModelCheckpoint来在每个epoch之后保存模型,或EarlyStopping当验证精度符合一定的要求时,停止训练。
我们也可以自定义callback参考
from tensorflow.keras import layers
#定义模型
model = tf.keras.Sequential([
layers.Dense(256,activation='relu'),
layers.Dense(256,activation='relu'),
layers.Dense(10)
])
#定义损失
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
#定义评估指标
accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
#定义优化算法
optimizer = tf.keras.optimizers.Adam()
#配置模型
model.compile(optimizer=optimizer,loss=loss,metrics=[accuracy])
#配置callback
callbacks = [tf.keras.callbacks.EarlyStopping(),tf.keras.callbacks.ModelCheckpoint(filepath='my_model.keras',save_best_only=True)]
#开始训练
model.fit(x_train,y_train,validation_data=(x_val,y_val),epochs=30,batch_size=64,callbacks=callbacks)
Train on 50000 samples, validate on 10000 samples
Epoch 1/30
50000/50000 [==============================] - 2s 42us/sample - loss: 0.2434 - sparse_categorical_accuracy: 0.9283 - val_loss: 0.1304 - val_sparse_categorical_accuracy: 0.9614
Epoch 2/30
50000/50000 [==============================] - 2s 35us/sample - loss: 0.0949 - sparse_categorical_accuracy: 0.9707 - val_loss: 0.0850 - val_sparse_categorical_accuracy: 0.9744
Epoch 3/30
50000/50000 [==============================] - 2s 34us/sample - loss: 0.0619 - sparse_categorical_accuracy: 0.9811 - val_loss: 0.0916 - val_sparse_categorical_accuracy: 0.9719
综述
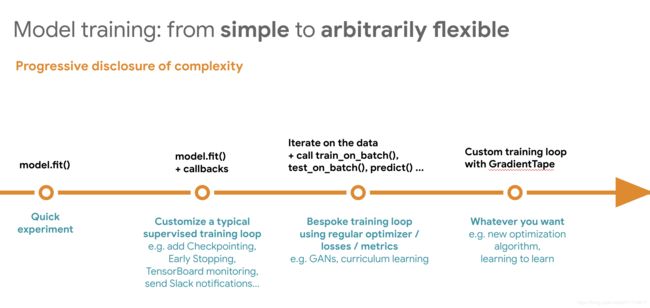
tensorflow2.0和keras提供了模型的灵活性和便捷性,选则适合你的工具就好了。
模型定义由简到繁:
Sequential -> Functional API -> Functional API + Custom_define -> Subclassing API
模型训练由简到繁:
model.fit -> model.fit + callbacks -> call train_on_batch with GradientTape -> GradientTape with all new algorithm

下一步
其它需要学习的内容:
- 模型保存和序列化
- 多GPU分布式训练
- tflite模型转换及加缘设备使用
- Tensorflow.js在浏览器中使用